Please provide the following information when requesting support.
• Hardware: 2x RTXA6000 Ada
• Network Type: Detectnet_v2
• TLT Version: API 4.0.2 - TaoClient: 4.0.1
• How to reproduce the issue ?
I’m migrating the entire deployment to a new workstatition.
With 1 GPU is working with the both configurations: with --use_amp and without it.
Now enable the two GPU with the TAO Helm deployment ‘values.yaml’.
First test with --use_amp enabled:
The initial steps are good from the logs, and when really need to start to train, get freeze.
The GPU have the ram loaded, but the frequency in idle.
LOG:
7a82fad8-bdd8-4a23-87f6-5c2265c4ce95_use_amp.txt (81.4 KB)
Second test without --use_amp.
Also launch the process, load the GPU memory, and get stuck with the GPU frequency at high.
Now we have new messages with NCCL info:
LOG:
83ea0c25-6a06-4f80-8703-9759d21fa062_no_amp.txt (83.7 KB)
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO Bootstrap : Using eth0:172.163.22.145<0>
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO NET/Plugin: Failed to find ncclNetPlugin_v6 symbol.
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO NET/Plugin: Loaded net plugin NCCL RDMA Plugin (v5)
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO NET/Plugin: Failed to find ncclCollNetPlugin_v6 symbol.
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO NET/Plugin: Loaded coll plugin SHARP (v5)
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO cudaDriverVersion 12000
NCCL version 2.15.5+cuda11.8
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO Plugin Path : /opt/hpcx/nccl_rdma_sharp_plugin/lib/libnccl-net.so
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO P2P plugin IBext
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO NET/IB : No device found.
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO NET/IB : No device found.
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO NET/Socket : Using [0]eth0:172.163.22.145<0>
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO Using network Socket
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO Channel 00/04 : 0 1
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO Channel 01/04 : 0 1
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO Channel 02/04 : 0 1
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO Channel 03/04 : 0 1
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO Trees [0] 1/-1/-1->0->-1 [1] -1/-1/-1->0->1 [2] 1/-1/-1->0->-1 [3] -1/-1/-1->0->1
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO Channel 00/0 : 0[21000] -> 1[22000] via P2P/IPC
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO Channel 01/0 : 0[21000] -> 1[22000] via P2P/IPC
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO Channel 02/0 : 0[21000] -> 1[22000] via P2P/IPC
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO Channel 03/0 : 0[21000] -> 1[22000] via P2P/IPC
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO Connected all rings
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO Connected all trees
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO threadThresholds 8/8/64 | 16/8/64 | 512 | 512
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO 4 coll channels, 4 p2p channels, 2 p2p channels per peer
83ea0c25-6a06-4f80-8703-9759d21fa062-86pn5:175:454 [0] NCCL INFO comm 0x7f43e7c1a310 rank 0 nranks 2 cudaDev 0 busId 21000 - Init COMPLETE
The rocket appear to be launch… but get stuck here.
A picture from the status of the GPUS
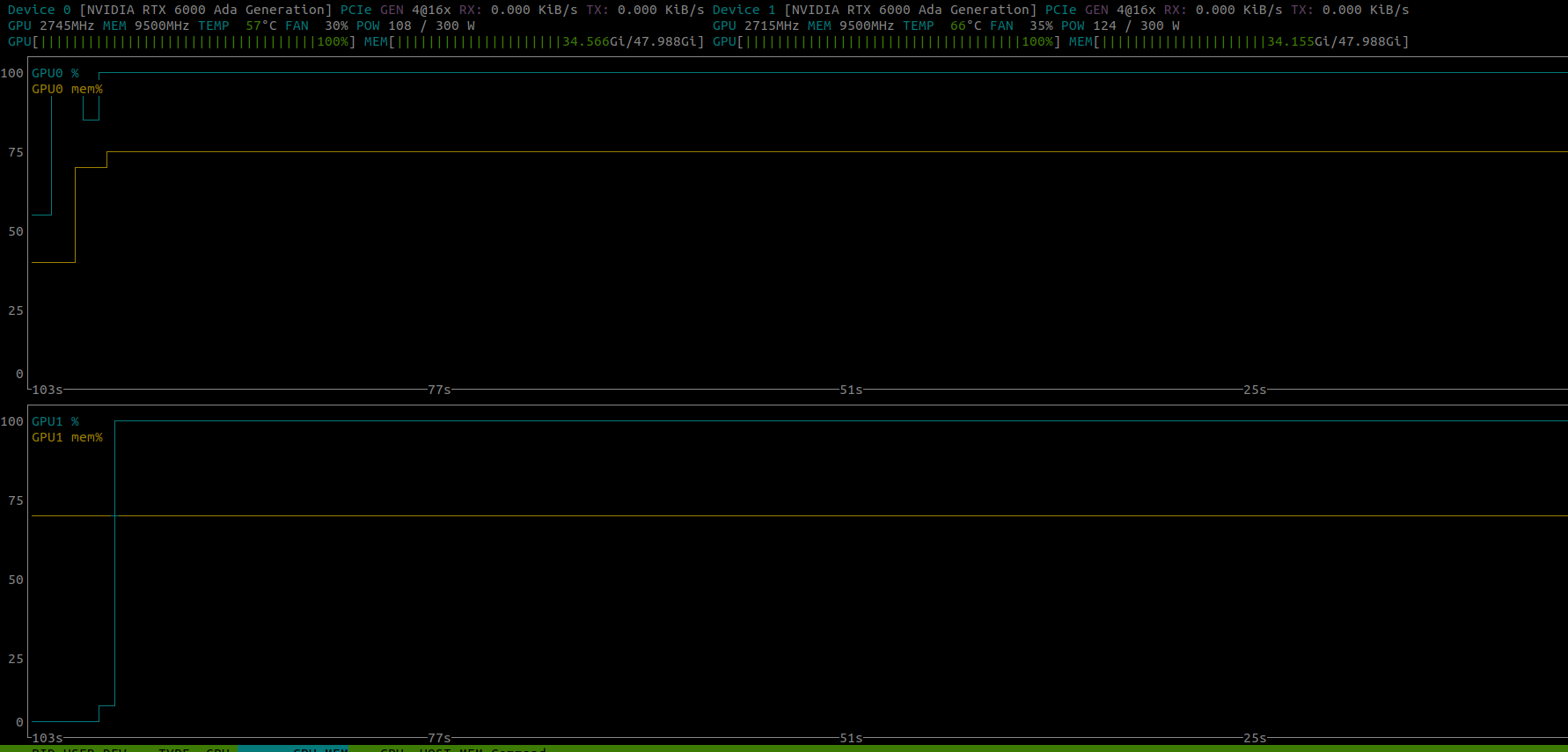
Thanks in advance.