Hi! I have some issues in installing TAO Toolkit API 5.2.0 on bare metal (single machine), using the provided scripts.
Starting from a fresh Ubuntu 20.04.6 these are the steps:
Set parameters in tao-toolkit-api-ansible-values.yml
Then running bash setup.sh install this is the result: first_run_log.txt (2.2 KB)
To solve the issue I’ve changed the value of check gpu per node to False. Restarting the installation gives this log: second_run_log.txt (2.2 KB)
My GPUs are seen as VGA controllers and not as 3D adapters, changing the grep condition to “VGA” fixed the problem. The new log is: third_log_run.txt (15.7 KB)
Site packages.google seems to be down, changed it to google.com and restart the script. The systems reboots when [Waiting for the Cluster to become available].
Executing the script after reboot gives: 4_run_log.txt (124.1 KB)
and the installation doesn’t go on.
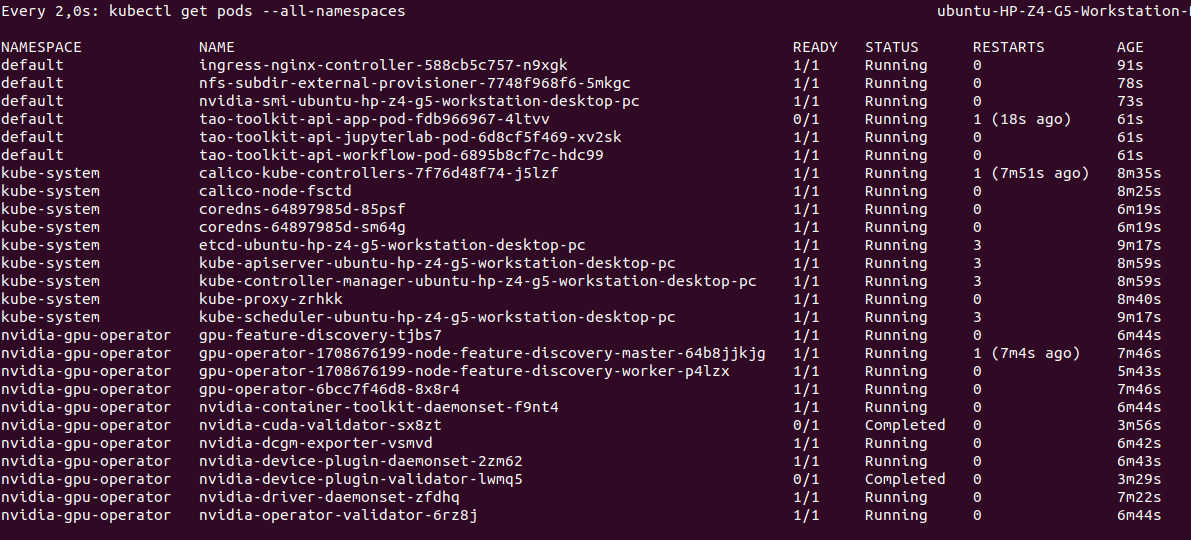
Command kubectl get pods --all-namespaces:
Executing command kubectl delete crd clusterpolicies.nvidia.com gives this log: output.txt (167.2 KB)
With the TAO api installation stuck. The kubectl describe pod tao command gives this info: kubect_describe.txt (4.9 KB)
with errors related to connection refused during the liveness checks.
This is not expected. The system should not reboot when Waiting for the Cluster to become available. Did you have the full log before Waiting for the Cluster to become available?
Hi Morganh and thanks for yor answer. Unfortunately not, because the system rebooted before the logs could be saved. I don’t think there was errors by the way, something like file 4_run_log.txt
After running setup.sh uninstall, rebooting and running setup.sh install the log is this one: after_reboot.txt (167.4 KB)
Some strange things that happen are:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
ingress-nginx default 1 2024-02-23 10:38:20.834726606 +0100 CET deployed ingress-nginx-4.9.1 1.9.6
nfs-subdir-external-provisioner default 1 2024-02-23 10:38:33.750200965 +0100 CET deployed nfs-subdir-external-provisioner-4.0.18 4.0.2
Result of helm upgrade:
history.go:56: [debug] getting history for release tao-toolkit-api
Release "tao-toolkit-api" does not exist. Installing it now.
install.go:178: [debug] Original chart version: ""
install.go:195: [debug] CHART PATH: /home/ubuntu/.cache/helm/repository/tao-toolkit-api-5.0.0.tgz
client.go:128: [debug] creating 1 resource(s)
client.go:128: [debug] creating 15 resource(s)
wait.go:48: [debug] beginning wait for 15 resources with timeout of 5m0s
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
...
ready.go:277: [debug] Deployment is not ready: default/tao-toolkit-api-app-pod. 0 out of 1 expected pods are ready
install.go:441: [debug] Install failed and atomic is set, uninstalling release
uninstall.go:95: [debug] uninstall: Deleting tao-toolkit-api
client.go:299: [debug] Starting delete for "tao-toolkit-api-ingress-auth" Ingress
client.go:299: [debug] Starting delete for "tao-toolkit-api-ingress-openapi-yaml" Ingress
client.go:299: [debug] Starting delete for "tao-toolkit-api-ingress-login" Ingress
client.go:299: [debug] Starting delete for "tao-toolkit-api-ingress-openapi-json" Ingress
client.go:299: [debug] Starting delete for "tao-toolkit-api-ingress-redoc" Ingress
client.go:299: [debug] Starting delete for "tao-toolkit-api-ingress-swagger" Ingress
client.go:299: [debug] Starting delete for "tao-toolkit-api-jupyterlab-service" Service
client.go:299: [debug] Starting delete for "tao-toolkit-api-service" Service
client.go:299: [debug] Starting delete for "tao-toolkit-api-workflow-pod" Deployment
client.go:299: [debug] Starting delete for "tao-toolkit-api-jupyterlab-pod" Deployment
client.go:299: [debug] Starting delete for "tao-toolkit-api-app-pod" Deployment
client.go:299: [debug] Starting delete for "e7f6a9f345004c800bf5eae8b81c3b1a20760348-rbac-crb" ClusterRoleBinding
client.go:299: [debug] Starting delete for "e7f6a9f345004c800bf5eae8b81c3b1a20760348-rbac-cr" ClusterRole
client.go:299: [debug] Starting delete for "tao-toolkit-api-pvc" PersistentVolumeClaim
client.go:299: [debug] Starting delete for "tao-toolkit-api-tutorials-configmap" ConfigMap
uninstall.go:144: [debug] purge requested for tao-toolkit-api
Error: release tao-toolkit-api failed, and has been uninstalled due to atomic being set: timed out waiting for the condition
helm.go:84: [debug] timed out waiting for the condition
release tao-toolkit-api failed, and has been uninstalled due to atomic being set
helm.sh/helm/v3/pkg/action.(*Install).failRelease
helm.sh/helm/v3/pkg/action/install.go:449
helm.sh/helm/v3/pkg/action.(*Install).reportToRun
helm.sh/helm/v3/pkg/action/install.go:433
helm.sh/helm/v3/pkg/action.(*Install).performInstall
helm.sh/helm/v3/pkg/action/install.go:389
runtime.goexit
runtime/asm_amd64.s:1581
TASK [capture user intent to override driver] *********************************************************************************************************************************************************************
[capture user intent to override driver]
One or more hosts has NVIDIA driver installed. Do you want to override it (y/n)?: