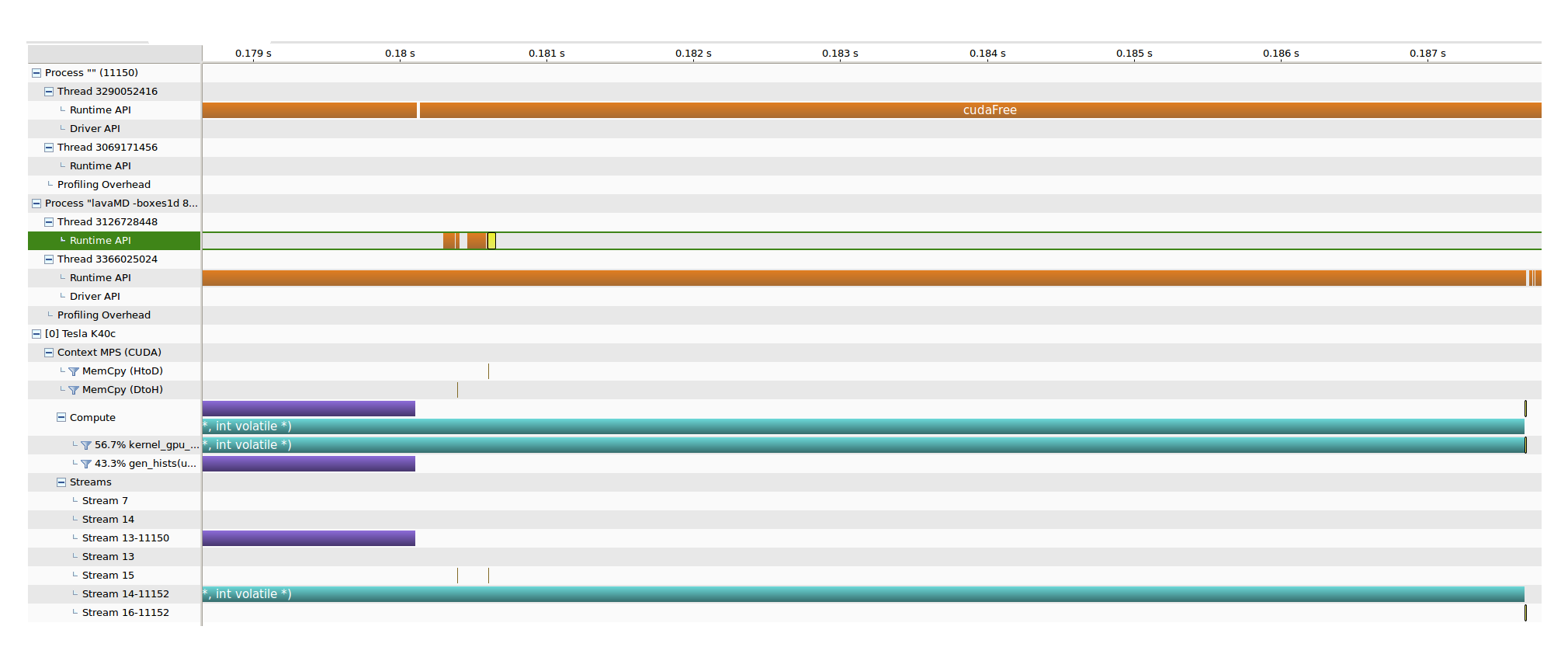
What could cause kernel execution to be serialized on two separate streams? I’m using CUDA 8.0 on a K40c with MPS running, and there are enough resources on the device to accommodate both kernels but I’m not observing any overlap. I create two streams in two different host threads, and launch one kernel in each of the streams without doing any work on the default stream. I tried compiling with and without “–default-stream per-thread” and both resulted in the same behavior. Running with and without profiling provide similar timings as well. The following is the timeline from nvvp (the purple kernel belongs to another program, I’m concerned with overlap of the instances of the green kernel):
The yellow rectangle in the Runtime API row of the host thread launching the second kernel shows the launch of the kernel. However, it’s not until the first kernel finishes that the second one starts execution (that tiny line in the bottom right of the image in stream 16-11152). Both launches are instances of the same kernel and are supposed to work on the same data, so when the first one finishes there’s no work left for the second one to do and it finishes very quickly. They grab blocks of work by atomically adding to the same global memory location.
Why would you expect kernel execution to overlap on a Kepler-class devices? What part of the documentation suggests that any kind of significant overlap should take place in this situation?
When I run the examples in the SDK I can see overlap, as well as the overlap with the kernel from the other application, so why shouldn’t I expect it in this case?
I cannot see any details in the reduced-size image in your post. Kepler is an old architecture with fairly crude resource allocation, if I recall correctly. I may well be wrong, it has been years since I used a K40. That is why I asked for relevant documentation pointers.
As a consequence, if one kernel is large enough to use up all the hardware resources, it will, and there won’t be any resources left for another kernel to run, except for minimal overlap at the edges where the first kernel is not yet / no longer using all the execution resources.
My guess is that the example you saw uses kernels that are not able to fill the machine by themselves, leaving execution resources available for other kernels to run with significant overlap.
The overlap of kernels will require, among other things, that the kernels are relatively small in their resource usage. Typical kernels are not like this. The “concurrent kernels” cuda sample code has carefully crafted kernels that use almost no resource, but still run for a long enough period of time to witness overlap.
This is in typical practice hard to witness. Other than your claim about enough resources, it’s impossible to probe this based on the information you have provided.
I’m not really sure why you would be using MPS, although I don’t think it should interfere.
Usually other things that prevent overlap are incorrect usage of streams, including the default stream.
If you claim that none of this applies to your case, then I’m unable to speculate further.
(I need to get more rigorous about not responding to questions that don’t provide a test case.)
a maximum of 32 grids can reside on a device with compute capability of 3.5 (K40c’s compute capability).
There are enough resources for both kernels, I control the size of the grid such that all can fit at the same time. The other point is that there’s not even minimal overlap in the end, one starts only after the other ends which wouldn’t be the case if there was any shortage of resources.
I don’t think it’s relevant to the problem, but I want to share the GPU among multiple kernels from different applications at run-time, so I need MPS. I then dynamically adapt the size of the existing kernels by either preempting some thread blocks or launching new instances to take arrival and departure of kernels into account.
I understand that it’s difficult to provide accurate answers when there’s no test case, and appreciate your responses, but it’s a fairly large project and it’s not possible to have a small simple test case which recreates the problem.
Here I put some Memcpy on the default stream, and the yellow rectangle corresponding to the kernel launch in the Runtime API row appears in the very end, right before the execution of the kernel itself, as opposed to the previous case when the kernel launch in Runtime API happened earlier, which means having work on the default stream delays the launch of the kernel not its execution.
![http://i.imgur.com/sKjGddN.png[/url]](http://i.imgur.com/sKjGddN.png%5B/url%5D){kind=link}