Hello, nv experts
I didn’t find reference description for the mapping relationship between block_idx(thread block) and sm_idx(SM) in nvidia public documents。
I want to know what is the mapping formular, is there anyone would like to teach me?
There is no relationship or mapping formula prescribed by CUDA. That is why you can’t find any information about it.
For many typical CUDA programs, the relationship should be irrelevant anyway. You can study nearly all the CUDA sample codes and they don’t need the SM ID for any reason.
1 Like
I’m very confused it, because I didn’t find any reference descriptions in nvidia public document,
but, I found there must be a fixed mapping formular after I reading this paper:<Stream-K_Work-centric Parallel Decomposition for Dense Matrix-Matrix Multiplication on the GPU>, it is published by nvidia, and this idea has been merged in cutlass.
at the same time, it show this figure:
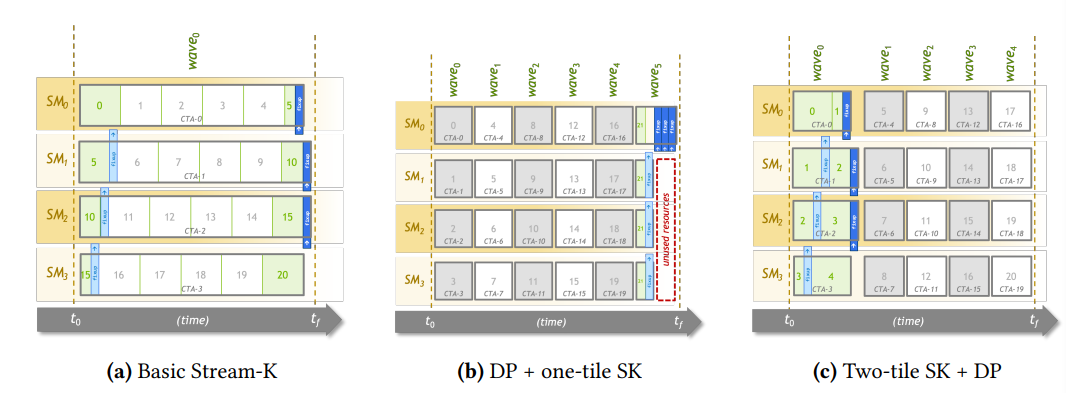
obviously, the author think there is a fixed relationship between CTA and SM, but It still didn’t show the relationship between CTA and SM, I still cannot find this mapping formula in this paper.
So, I’m very confused.
Using an atomic counter, one can logically reorder blocks such that blocks which are scheduled first have a smaller logical block id
If you want to do this level of tuning, a threadblock can query its SM ID and organize its work that way. For example if you launching a kernel with enough threadblocks to fill a GPU, then each threadblock can query its SM ID, and then choose to do a portion of the work based on SM ID rather than using built-in threadblock variables.
This, for example, would allow you to arrange work so as to provide benefit from the L1 cache to multiple threadblocks. If you have multiple threadblocks per SM, you still need to sort out which is which perhaps using a per-SM atomic like what striker159 suggested.
You can query the sm id like this.
Here is an example of a code that does SM-specialization, and allows for multiple blocks per SM.
There are a variety of other code examples that do various things based on the SM ID. Here are some examples: 1 2
I haven’t read the paper you indicated.
thanks for your kindly explanation
I applied the ptx in my applicatioin: asm("mov.u32 %0, %smid;" : "=r"(ret) );,and I diasm this ptx, the result like this:
/*0040*/ S2R R7, SR_VIRTUALSMID ; /* 0x0000000000077919 */
/* 0x000e620000004300 */
/*0050*/ SHF.L.U32 R2, R5, 0x1, RZ ; /* 0x0000000105027819 */
/* 0x001fca00000006ff */
/*0060*/ IMAD.WIDE.U32 R2, R2, R3, c[0x0][0x160] ; /* 0x0000580002027625 */
/* 0x000fca00078e0003 */
/*0070*/ STG.E [R2.64], R5 ; /* 0x0000000502007986 */
/* 0x000fe8000c101904 */
/*0080*/ STG.E [R2.64+0x4], R7 ; /* 0x0000040702007986 */
I noticed that “SR_VIRTUALSMID”, so, I think it is only virtual smid, instead of physical smid, my guess is right?