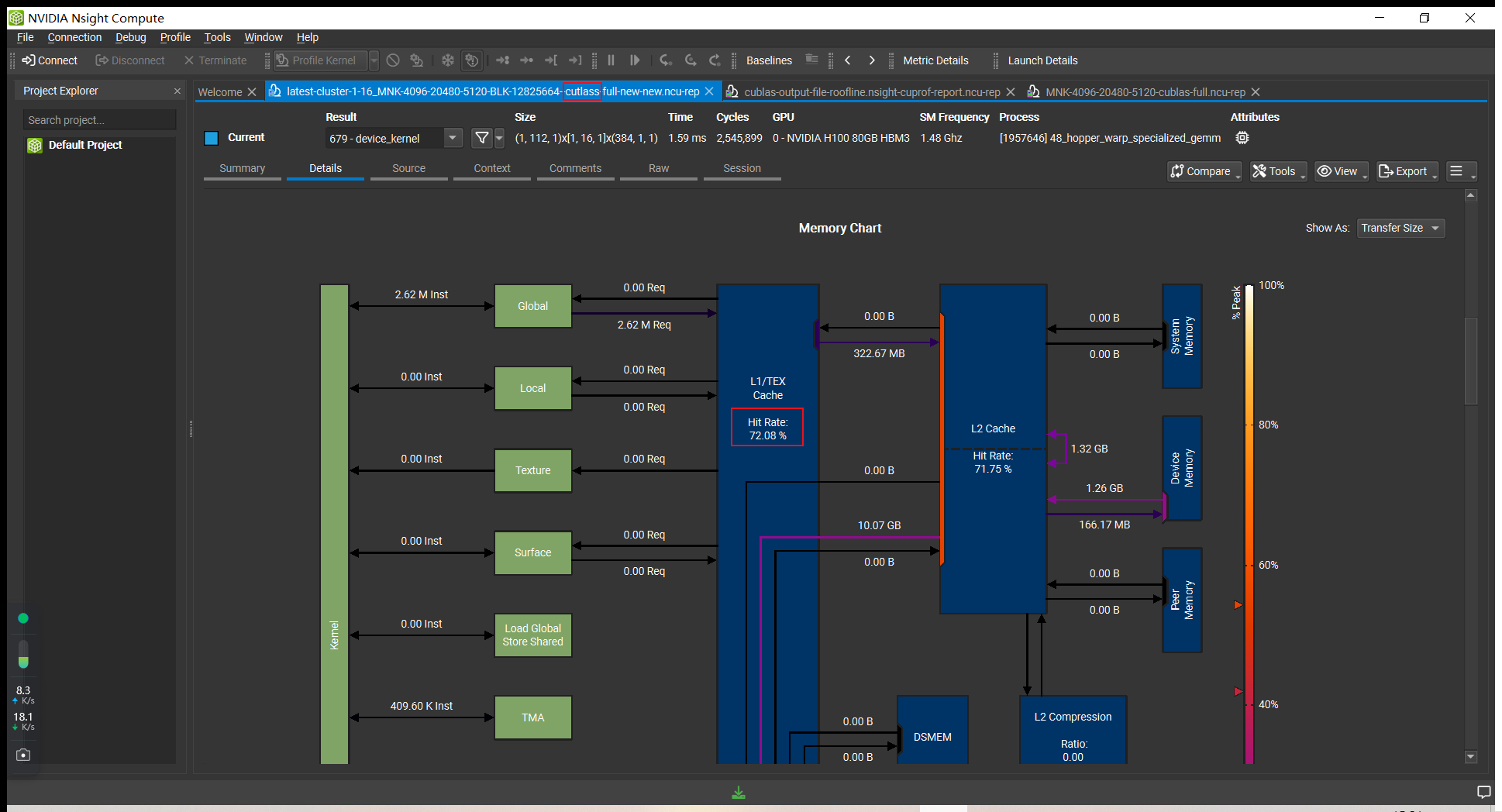
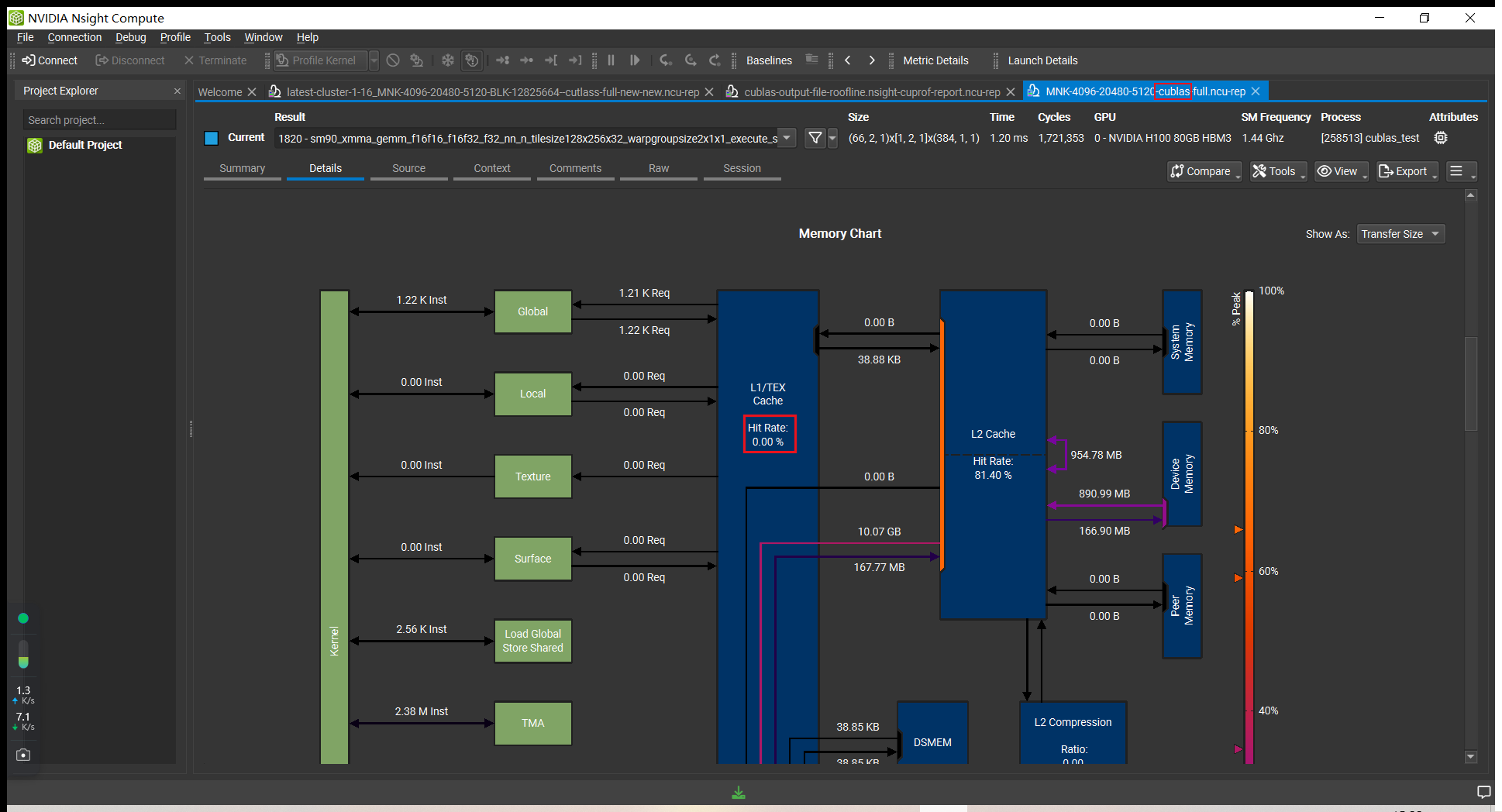
Using shared memory would not necessarily appear as L1 hit, you have to look at the tables below the graph in Compute Nsight to see the amount of shared memory stores and loads.
If you handle the data caching manually with shared memory, no L1 cache is needed.
With shared memory you can better control, when to start and when to end storage of data. With shared each thread can access a different bank, so less coalescing requirements.
L1 is simpler to use. If you cannot predict, which data to reuse or it is complicated, e.g. because the timing of different warps needing access to the data is not predetermined or because your overall working set is larger than the shared memory size or your program speed is not bound by it, or your problem and algorithm do not need repeated accesses, like element-wise operations.
Many kernels could be written to either use L1 or shared memory (or use each for different kind of data).
You can also write kernels, which use neither, because they keep the data within warps or threads.
Warps can use shuffle instructions to exchange data (shuffle uses the data shuffling portion of shared memory, but not the memory itself), threads can hold data in registers. If you unroll loops, you can store indexed arrays in registers. For example I have done complex FFT calculations with array size of 64 complex numbers in registers (needs 128 registers) of a single thread. So you can calculate 32 FFTs per warp simultaneously. No need for shared memory.