Why cuMemcpyHtoD and cuMemcpyHtoDAsync have almost the same performance tested at different CPU frequencies (1.5GHz and 2.8GHz) (copy 5M data) .
test code:

Why would there be an expectation of different copy performance based on CPU frequencies?
Because the GPU task is very small (only 5M data copy). In this condition, the performance should be different at different CPU frequencies. (CPU has a high occupancy)
CPU cores are not involved in these bulk copies, it is pretty much all memory controllers and DMA channels. The performance of data copies depends (to varying degrees based on the specifics of the copy operation) on the throughput of
(1) GPU memory (HBM2, GDDR6)
(2) PCIe interconnect (e.g. gen 4 x16) or NVlink
(3) system memory (typically DDR4)
If PCIe is used for host-device interconnect it clearly has the lowest throughput of these three entities and is therefore the main bottleneck for copies between host and device in either direction.
For copies to and from pageable host memory you may see a small performance difference when switching from, say, a system with 2 DDR4 channels to a system with 8 DDR4 channels, because such copies involve bulk copies within system memory.
My intention was to test the performance of CUDA software stack. So I only copy one byte repeatedly from host to device. Then I found different CPU frequencies have same performance.
If GPU has a small task(copy one byte data), CUDA stack become the major performance consumer. Why does it have nothing to do with CPU frequency?
According to the posted code the copy involvessizeof(char) * num bytes where num = 5 * 1024 * 1024. Which is a transfer size of 5 MB, not 1 byte.
If you were to copy 1 byte over and over gain between host and device the data throughput would be completely limited by PCIe overhead. PCIe uses packetized transfers, and the header size for one packet is on the order of 50 bytes, if I recall correctly. So if the payload of that packet is only 1 byte, the PCIe link will be busy but the payload data throughput will be low.
Your observation about CPU utilization is entirely plausible in so far as each transfer between host and device also involves the execution of some CUDA driver code, and if your program makes hundreds of thousands or millions of one-byte transfers to the GPU per second, that little overhead adds up so it can keep one CPU core quite busy.
Your basic idea is correct, of course. A CPU with higher single-thread performance (and this would be implied when CPU frequency changes from 1.5 GHz to 2.8 GHz) will execute the layers of the CUDA software stack faster. But off the top of my head the only CUDA API operations where that should be readily observable is in malloc/free type of calls, as they are quite expensive. For CUDA API calls that primarily involve configuring / controlling hardware, such as data copies between host and device, the host-side software overhead will be quite small and I would not know how to isolate and measure that reliably.
Have you checked whether the CUDA profiler can report the host-side overhead of CUDA API calls to you?
I try to use Nsight-system, but do not get the host-side overhead of CUDA API. Maybe it need some special configuration.
Maybe no such functionality is provided by the profiler. I have never needed this particular piece of data so have never tried to find out. What is the ultimate goal in determining the rather small host-side overhead of invoking a copy operation? As we have established, such an operation is ultimately limited by the throughput of the PCIe interconnect, i.e. hardware.
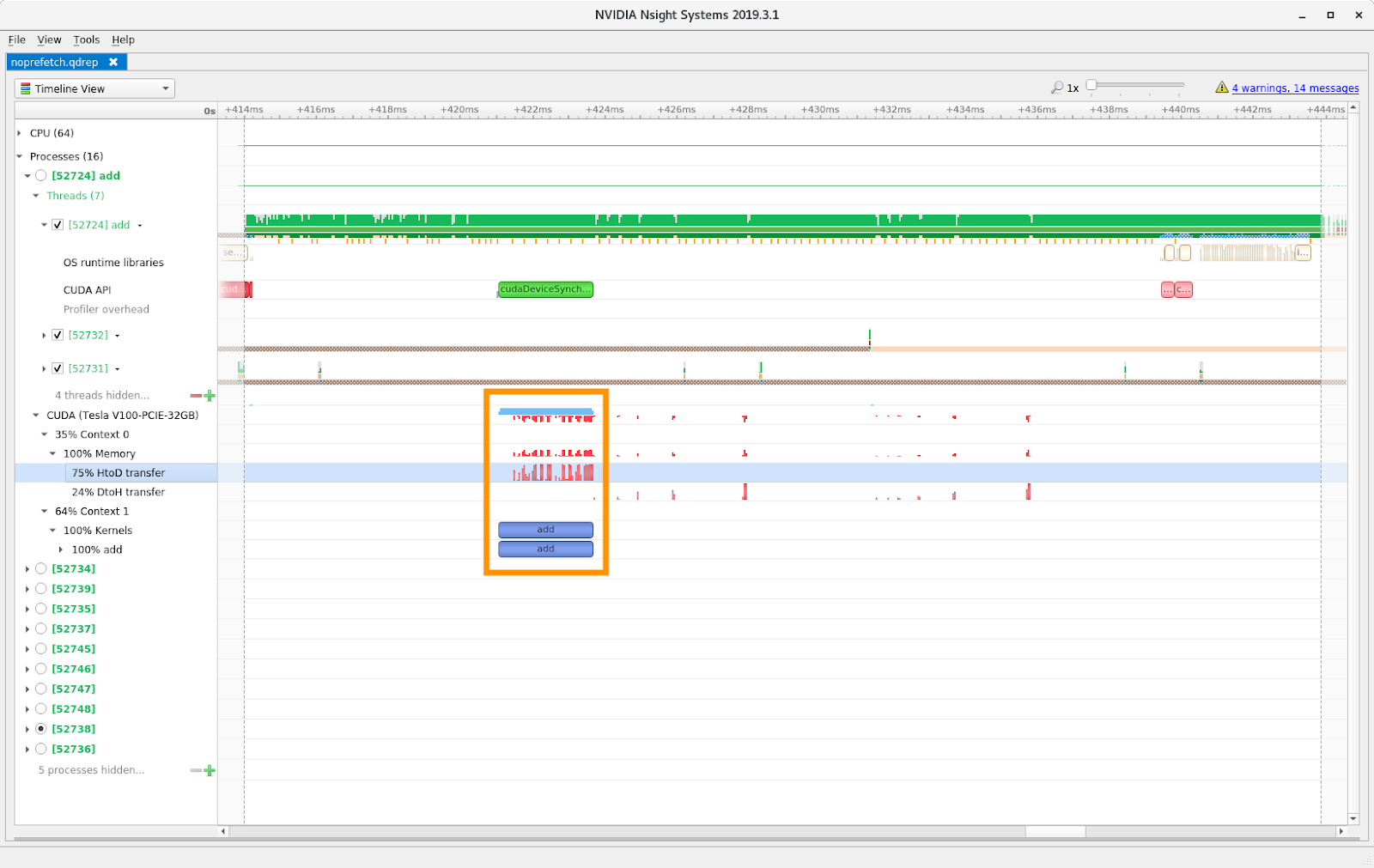
Host side duration of CUDA API calls is provided in the host timeline section of nsight systems GUI output. For example in the picture here (from this blog) look at the “CUDA API” timeline to see the trace of the CUDA API calls from the point of view of the host thread calling them. The trace includes a full duration indication, so overheads or other aspects can be evaluated from that.

{kind=link}
I want to test the bottleneck of both host and device.
In some case, the performance may limited by host.
It can help me to analyse the performance of application.
For example,when copying one byte from host to device again and again, you said the bottleneck is PCIe. Is it possible for host to become a bottleneck if host send packets or commands too slowly?
In the picture that I previously linked, the device side activity is depicted in the yellow box. Roughly speaking, the upper half of the timeline area/display in nsight systems corresponds to host timelines/traces, and the lower half corresponds to device timelines/traces.
How can something become a bottleneck if it isn’t fully utilized? Certainly the time used by a host thread to send commands to the GPUs or configure the GPU is not available to other processing in that thread. But that does not create a bottleneck in the sense in the usual sense of the word.
What problem are you ultimately tying to solve here? It seems to me this is some kind of XY problem, where the Y part is the accurate determination of the time needed for host-side activity of certain CUDA API calls, and the X part hasn’t been revealed yet.