I use a fc op, find the time of L2 to L1 and L2 to shared memory is slow,
but why the L2 to L1 more slow?
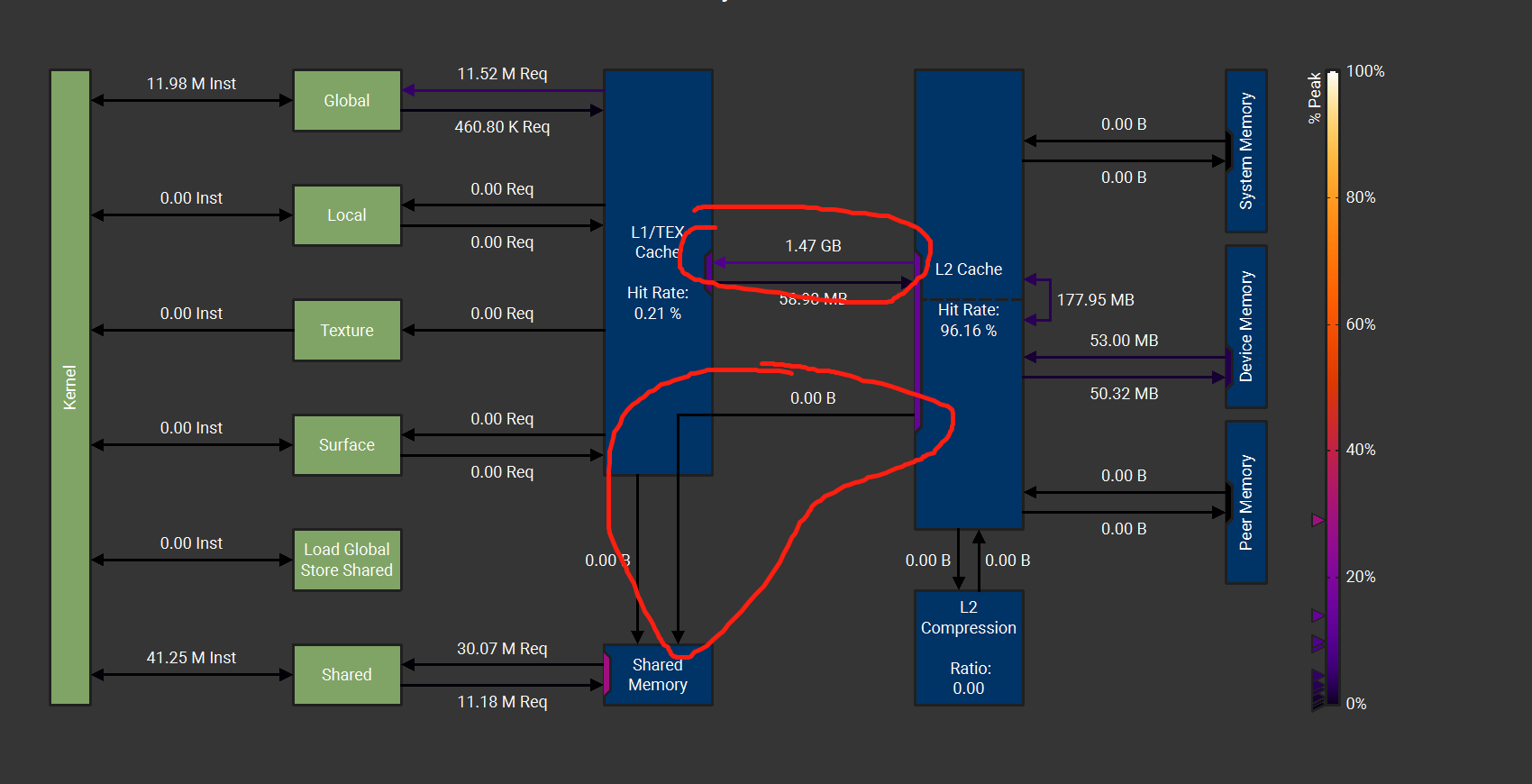
whether L2 → L1 → shared memory? but the L1 to shared menory is 0B
Can you share a Nsight Compute result with some more details? It’s not clear to me exactly what you’re seeing and how to clarify it. Thanks.

I profile a full connection layer on A100.
The above are the results of fp16 and fp32 respectively
in fp16, there is a line from L2 to shared memory with 191.66B, but in fp32, this line always 0B, all data trans to L1.
In my consciousness, L1 and Shared memory are the same piece of hardware, when it trans to L1 ? when it trans to shared memory?
thanks.
The L-shaped path from L2 to Shared Memory represents the LDGSTS instruction path, i.e. “Asynchronous Global to Shared Memcopy”. It’s hard to say why fp16 is using this path and fp32 is not. It could be that the compiler generated instructions to use this path in one case and not the other. Or if you’re using library code, maybe it was implemented that way. You should be able to look at the SASS assembly in Nsight Compute and see the difference in the SASS instructions. But why code was generated that way is difficult to say with only this information.