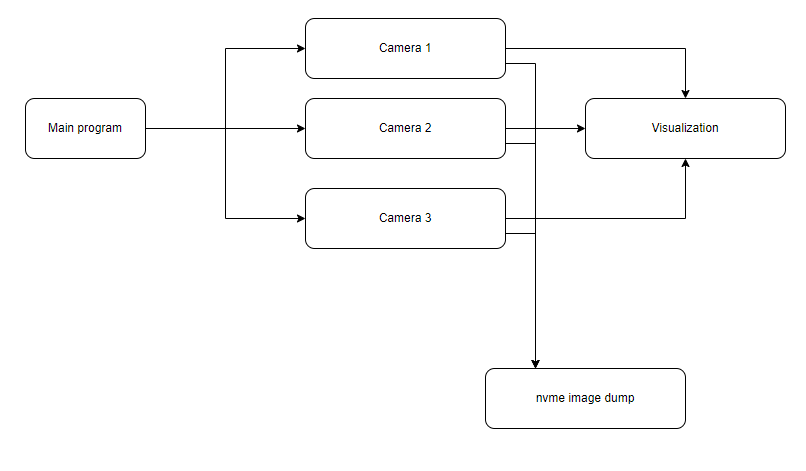
Hi,
Thanks for answering. Sorry for not providing all information. Very clear in my head :)
Yes. Its USB 3.1. . I did set the mode to 2 (15W 6 cores) (NX). I ran the jetson_clocks and the echo’s.
Seemingly no effect.
I have linked an image to show to problem.
What I believe still is that there is a problem reading and writing to my memory from the cameras and one visualization thread.
Image result.
I instantiate my memory array Memory stack and is created in my main program.
This is a class object in Memories called shared_memory. (don’t mind my nomenclature of private etc. its a bit confusing)
MemoryStack=[
Memories._shared_memory(),
Memories._shared_memory(),
Memories._shared_memory()]
The Camera uses this after reading with cv2.imread()
self.SharedMemory.put(newFrame,self.ind)
The Visualization does this:
self.Lock.acquire()
image1,index1 = self.memory[0].get()
image2,index2 = self.memory[1].get()
image3,index3 = self.memory[2].get()
self.Lock.release()
if int(self.properties.numberofcameras)==1:
fullImage = image1
elif int(self.properties.numberofcameras)==2:
fullImage =cv2.hconcat([image1,image2])
elif int(self.properties.numberofcameras)==3:
fullImage =cv2.hconcat([image1,image2,image3])
This is my memory class. The lock comes to play when using from get and put methods. I think the lock I have in my visualization is reduntant since I use that already in the get method.
So every camera uses put and get. BUT I don’t use thread-lock on the Array in the main program.
So perhaps that is the problem that the camera threads try to read from MemoryStack which is not
thread safe but every instance in the MemoryStack is protected with a lock when calling get/put.
class _shared_memory(object):
def __init__(self):
self.tLock = threading.Lock()
self._s_memory,self._index = None,None
@property
def _variable1(self):
return self._s_memory
@property
def _variable2(self):
return self._index
def get(self):
self.tLock.acquire()
v1 = self._variable1
v2 = self._variable2
self.tLock.release()
return v1, v2
def put(self, value,index):
self.tLock.acquire()
self._s_memory = value
self._index = index
self.tLock.release()
return
Hope I make sense here…Perhaps the source code I linked to can shed better light.