Originally published at: https://developer.nvidia.com/blog/even-easier-introduction-cuda/
Learn more with these hands-on DLI courses: Fundamentals of Accelerated Computing with CUDA C/C++ Fundamentals of Accelerated Computing with CUDA Python This post is a super simple introduction to CUDA, the popular parallel computing platform and programming model from NVIDIA. I wrote a previous “Easy Introduction” to CUDA in 2013 that has been very popular over…
Hi Sir, thanks for the tutorial. I tried this code on Tesla T4, and found that using 4096 blocks does not improve the performance to us level compare to 1 block 256 threads. What might be the reason ? thanks.
Thanks for the post Mark. To get accurate profiling, is it still a good idea to put cudaDeviceReset() just prior to exiting? https://devblogs.nvidia.com...
Also, is it possible to get this level of timing via code? cudaEventElapsedTime does not seem to have this same level of precision.
Thanks Mark. I tried this and it did not work as a straight copy and paste. The cudaMallocManaged did not appear to do anything. This is on a Titan X with up to date drivers and NSight. I replaced the cudaMallocManaged functionality with the relevant cudaMalloc and cudaMempy, which sorted it. Am I missing something wrt cudaMallocManaged?
It's a really good post btw. Thanks - I have learned much.
What do you mean did not appear to do anything? Did you get an error? Incorrect results? What CUDA version do you have installed? Is it an "NVIDIA Titan X" (Pascal) or "GeForce GTX Titan X" (Maxwell)?
I think the Windows tools are more dependent on cudaDeviceReset(). I kept it out of this post to keep things simple. cudaEventElapsedTime() should have the same level of precision, but in more complex apps you may get things in your timing that you didn't intend.
I believe the most reliable way to accurately time is to run your kernel many times in a loop, followed by cudaDeviceSynchronize() or cudaStreamSynchronize(), and use a high precision CPU timer (like std::chrono) to wrap the whole loop and the sync. Then divide by the number of iterations.
CUDA 8 latest. It's the Pascal card. After executing the cudaMallocManaged function the variable pointed to address 0x0. I'll put error checking into your original code in the morning and try to get more diagnostic information.
I cannot access variable assigned using 'cudaMallocManaged' on host. It throws '0xC0000005: Access violation writing location 0x00000000' error. I can access them fine on device kernel. Am I missing something ? I am using MS Visual Studio Community 2015 with CUDA Runtime 8.0 on GTX 1070.
I think I had the same problem. Var pointed to '0x0' and it was not accessible by host. However accessible by device. I know it works the old was using separate var for host and device. But it would be good if we can make it work without all those memCpy like this example does. Tell me if you have any luck.
Did you guys change the program at all? If you share your changes I can try to diagnose.
Did you change the code, or are you getting the error in the initialization loop?
I didn't change the code at all. Just copied it to visual studio. Yes, I got error on initialization loop. So I put initialization in kernel. Got error at verification as expected. Removed verification and it ran fine. From this I concluded that it's not accessible by host. Further mode in VS debugging watch it shows it the same was as var allocated by cudaMalloc, some can't read or something indicating that it's not accessible to CPU as I understand. And the address is 0x0. Sorry for long response. I really appreciate your help.
I just put the unchanged original on a box with a GT 755M and it fails similarly. What have I done wrong?
:::
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <iostream>
#include <math.h>
// Kernel function to add the elements of two arrays
__global__
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1 << 20;
float *x, *y;
// Allocate Unified Memory ñ accessible from CPU or GPU
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the GPU
add << <1, 1 >> >(N, x, y);
// Wait for GPU to finish before accessing on host
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i] - 3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}
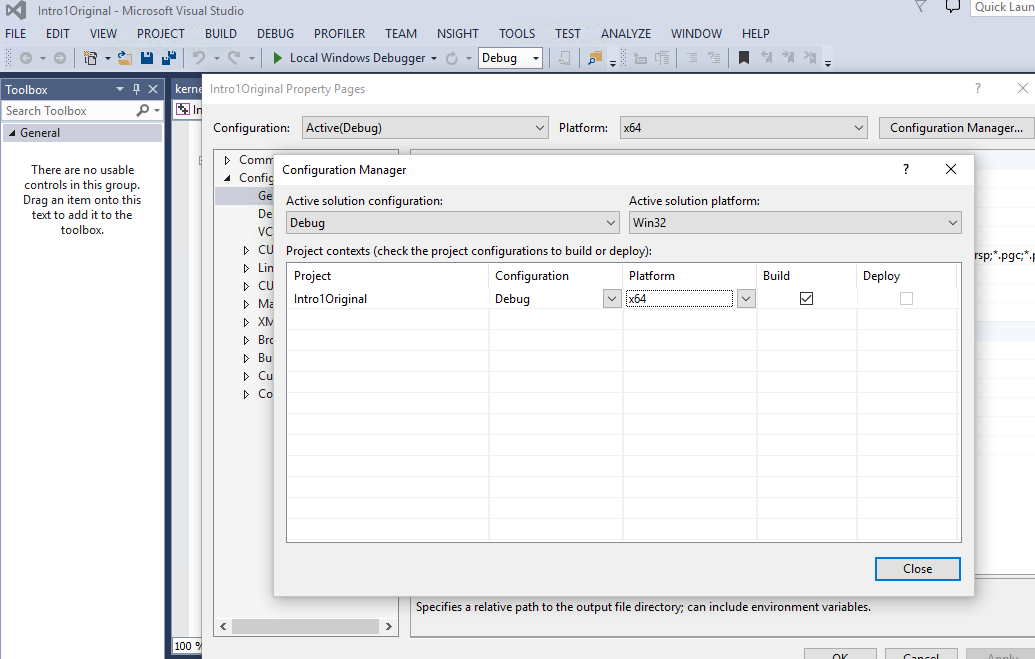
It is not sufficient to change the the target to x64 in the CUDA properties solution properties and Active(x64) in the properties - you must change it in the solution configuration manager. It then execs fine. The error is simply a 'not supported' one.
Thanks Mark - suspected it was my bad.
You need to change the solution properties to x64 in the Configuration Manager. Changin it in the CUDA props and in the Active platform dropdown don't get it done.
Thanks, that worked !
any chance you can post a screenshot of this, @mike_agius:disqus? Thanks!
I have used this tech way back and am quite pleased with the results .
The speedup is so adictive that i swear by my program
I encorage all to give cuda a must try to solve problems even if it requires nvidia specific hardware
.This is my code developed when i was grad student
{kind=link}