Hi! I am developing slender matrix multiply and follow cutlass’s GEMM algorithm, also follow their suggestion, to change the kernel size.
My matrix is of the size 30720 * 3072 @ 3072 * 128, and I find out, the best kernel size is 128 * 128.
Later I find out change the L2 cache policy is benificial.
So I am measuring my performance
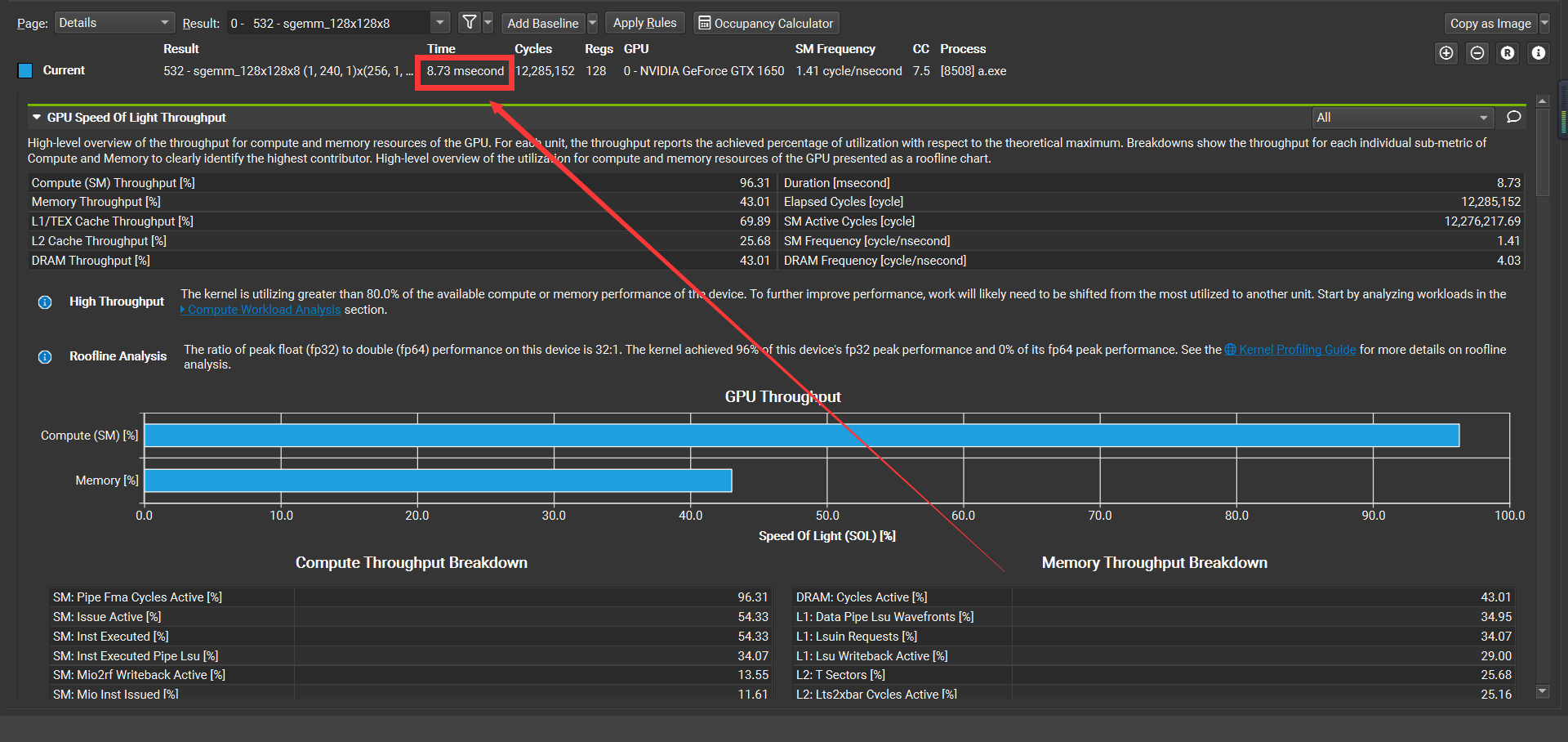
From google’s page, I learnt my turing 1650’s fp32 peak performance is 3.2TFLOPS

My kernel’s time spending is 8.73ms, so 2307203072*128/(8.73e-3)≈2.76e12(calculation/second)
So it is, 2.76e12/3.2e12≈86.25%?
So, seems still have improved space. For my slender matrix multiply, cutlass does not provide too much suggestions. I tired to find some papers, but those papers’ performance is actually much more slow than cutlass…or maybe only fast when verrrrry slender?
So could someone kindly provide some ideas? Maybe…Using stream to split calculation? sliceK? Splitk?(But I have tried them and become slower…not sure maybe my code’s incorrect implementation…)
Thank you!!!