Dear Team,
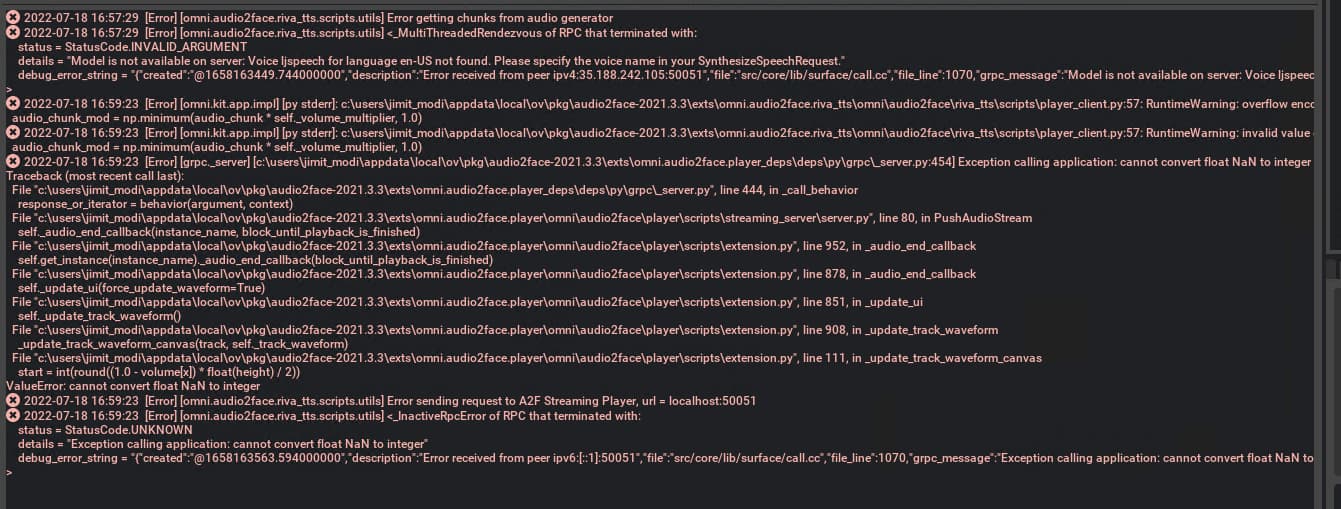
Riva TTS app in A2F application is not working if I am using Riva 2.2 and above TTS endpoints. But, It works perfectly with Riva 1.7.0-beta. Can you tell me what the issue I might be facing?
Dear Team,
Riva TTS app in A2F application is not working if I am using Riva 2.2 and above TTS endpoints. But, It works perfectly with Riva 1.7.0-beta. Can you tell me what the issue I might be facing?
I changed voice-name from “ljspeech” to “English-US-Female-1” in the tts_client.py:

Hello @farman.ahmed! I contacted the dev team for more help in answering your questions. I will post back when I have more information!
Hi @farman.ahmed
The error still looks like it’s using “ljspeech” instead of “English-US-Female-1”.
Did you restart the app after making the code change?
If you insert some prints along with your code change, can you see if the changes is used?
Hi @esusantolim
I have restarted the app after code change, I’m still facing this issue.
@farman.ahmed ,
Have you tried adding prints ?
Can you also share the path of the file you edited? (just making sure it’s the same file as those printed in the error log)
Can you share your edited file?
Thanks
The fix for this is quite easy, there is just some difference in the quality and how the numbers are handled. I did this fix a long time ago but tested it now and works with latest A2F and with Riva version 2.3.0
In player_client.py of the RIVA TTS Example plugin, change lines 48 through 64 to:
if self._zero_padding_len > 0.0:
buf_len = int(float(samplerate) * self._zero_padding_len)
zero_padding_chunk = np.zeros(buf_len, dtype=np.int16)
zero_audio = zero_padding_chunk.astype(np.float32, order='C') / 32768.0
yield audio2face_pb2.PushAudioStreamRequest(audio_data=zero_audio.tobytes())
try:
for chunk in audio_generator:
# WARNING: assuiming chunk.audio bytes contain array of float32
if self._volume_multiplier != 1.0:
multiplier = pow(2, (np.sqrt(np.sqrt(np.sqrt(self._volume_multiplier))) * 192 - 192)/6)
audio_chunk = np.frombuffer(chunk.audio, dtype=np.int16)
audio_chunk_mod = np.multiply(audio_chunk, multiplier)
audio = audio_chunk_mod.astype(np.float32, order='C') / 32768.0
else:
audio_chunk = np.frombuffer(chunk.audio, dtype=np.int16)
audio = audio_chunk.astype(np.float32, order='C') / 32768.0
yield audio2face_pb2.PushAudioStreamRequest(audio_data=audio.tobytes())
Don’t remember exactly what those constants do in the multiplication but has something to do with quality of the sound so it matches the sample rate.
It worked. Thanks for the help.