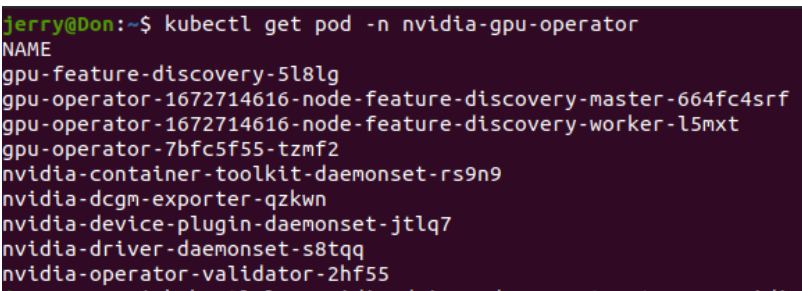
From the file cnc/cnc-validation.yaml, the “Waiting for the cluster to become available” is stuck due to below command.
name: Waiting for the Cluster to become available
args:
executable: /bin/bash
shell: |
state=$(kubectl get pods -n nvidia-gpu-operator | egrep -v ‘Running|Completed|NAME’ | wc -l)
while [ $state != 0 ]
do
sleep 10
state=$(kubectl get pods -n nvidia-gpu-operator | egrep -v ‘Running|Completed|NAME’ | wc -l)
done
register: status
when: “cnc_version > 4.1 and ansible_architecture == ‘x86_64’”
You already check it via “kubectl get pods -n nvidia-gpu-operator” .
Can you open a new terminal to check several logs against the failed pod?
For example, for your failed pod,
$ kubectl logs -n nvidia-gpu-operator nvidia-driver-daemonset-s8tqq