I am using Dusty’s jetson-inference repository to create a real-time object detection program for a custom dataset.
Background info
Right now I am training and predicting on a PC with a NVIDIA graphics card and CUDA installed. The goal is to put a nice trained model (in ONNX) format on the Jetson Nano, and perform inference with TensorRT optimization. However, the model is not predicting correctly…
I am using the VisDrone2019-DET dataset, which has 8629 images. I have transformed the data to conform to the VOC standards, this is what my dataset looks like:
VisDrone
├── Annotations
│ ├── 000001.xml
│ ├── 000002.xml
│ ├── 000003.xml
│ ├── 000004.xml
│ ├── 000005.xml
├── ImageSets
│ ├── Main
│ │ ├── test.txt
│ │ └── trainval.txt
├── JPEGImages
│ ├── 000001.jpg
│ ├── 000002.jpg
│ ├── 000003.jpg
│ ├── 000004.jpg
│ └── 000005.jpg
└── label.txt
Example of the annotation files:
<annotation>
<object>
<name>person</name>
<bndbox>
<xmax>374</xmax>
<xmin>160</xmin>
<ymax>481</ymax>
<ymin>217</ymin>
</bndbox>
<truncation>0</truncation>
<occlusion>0</occlusion>
</object>
<object>
<name>person</name>
<bndbox>
<xmax>20</xmax>
<xmin>1</xmin>
<ymax>98</ymax>
<ymin>1</ymin>
</bndbox>
<truncation>0</truncation>
<occlusion>0</occlusion>
</object>
<object>
<name>car</name>
<bndbox>
<xmax>375</xmax>
<xmin>310</xmin>
<ymax>289</ymax>
<ymin>165</ymin>
</bndbox>
<truncation>0</truncation>
<occlusion>0</occlusion>
</object>
</annotation>
The data looks really nice in my eyes, although I am suspecting that the data may be too hard for the choice of model. I wanted to post a picture of an annotated example image from the dataset, but the forum won’t allow me to add more than one embedded picture per topic…
Now when I go to training the model, I am executing this:
python train_ssd.py --net mb2-ssd-lite --pretrained-ssd models/mb2-lite.pth --data ../../VisDrone --model-dir models/visdrone_model --dataset-type voc --epochs 100
I have tried a little to play around with --batch-size and --learning-rate, but when testing different options with lower epochs, it still is pretty bad
This is the average precision of the model (note that it is calculated using the training images):
python eval_ssd.py --net mb2-ssd-lite --trained_model models/visdrone_model/mb2-ssd-lite-Epoch-99-Loss-6.650372860745224.pth --dataset_type voc --dataset ../../VisDrone/ --label_file models/visdrone_model/labels.txt --eval_dir models/visdrone_model_eval
[...redacted...]
Average Precision Per-class:
car: 0.08366060023699787
motor: 0.0036423337837340614
person: 0.0023940388984447654
pedestrian: 0.002341346690480933
awning tricycle: 0.002820879803813936
tricycle: 0.0019855374143438924
bicycle: 0.0004966070280048979
truck: 0.053817137171613544
van: 0.01781248643689646
bus: 0.11825235193326702
Average Precision Across All Classes: 0.02872233193975974
To predict images with run_ssd_example.py, I made one change, since it gave the error RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! That’s why I changed the line:
predictor = create_mobilenetv2_ssd_lite_predictor(net, candidate_size=200)
to:
import torch
predictor = create_mobilenetv2_ssd_lite_predictor(net, candidate_size=200,device=torch.device('cuda:0'))
Then using run_ssd_example.py, I predicted objects in the same image. The prediction looks really bad to me…
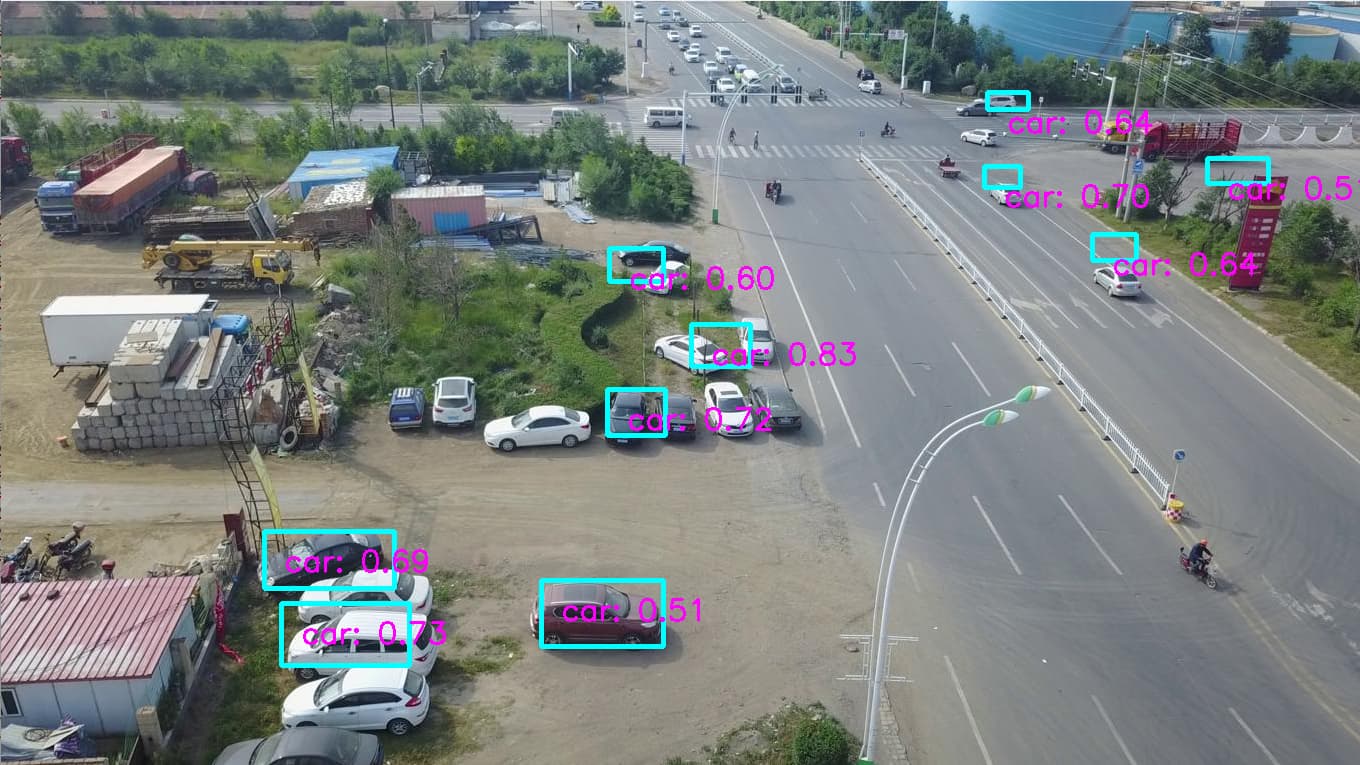
To me it looks like the training did some things right, but you can see that it is really not good enough.
Please note that this image processing is done with pytorch, and not with TensorRT. When I use detectnet with TensorRT, I get similar results thought.
Now that I flooded you with information, I have some questions for you:
- Any ideas for changing the batch-size and learning-rate (and maybe more options) to make the training work better?
- As you can see, the precision and predictions are really bad, any idea why? I thought maybe the dataset is too hard for the SSD Mobilenet V2 lite. If so, how can I improve on this, while keeping a real-time model?
Let me know if you could use any more information!
