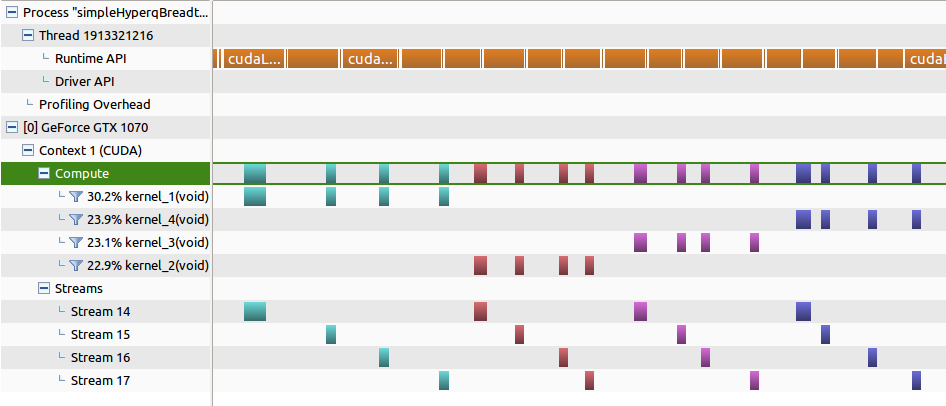
Try running the CUDA concurrentKernels sample code. When using the profilers, make sure the options to profile concurrent kernels is enabled.
Since all the kernels launched in the example you give are launched into the same stream per iteration, no concurrency will be witnessed for kernels in the same iteration, with respect to each other. Kernels in subsequent iterations may not run concurrently if the GPU is fully occupied with other kernels from previous iterations.
In the attached images you cut off the timeline axis so it is not possible to determine the duration. From the images it is can been seen that the CPU launch overhead exceeds the kernel duration so you will not be able to achieve concurrent execution unless you increase the duration of the kernel.
The first recommendation is to increase the duration of each kernel. The Fermi - Volta the CWD (compute work distributor) will full distribute all thread blocks from one kernel before processing the next kernel (assuming all kernels are launched with equal priority). If the kernel launch saturate the GPU resources then concurrency will only be observed at the end of a kernel as SM resources are freed.