I found a strange behavior using streams. The host->device memory copy is overlapped with the kernel execution, but the device->host copy waits for all kernel runs to be finished.
The following image shows the timing: 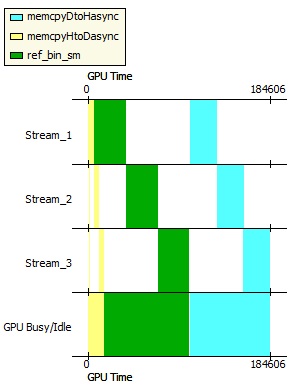
As you can see from the profiler output, streams are correctly used, all memories are pinned: 
The SDK’s simplestream example is also affected by the problem, I get the following results:

I use a GTX480 in an MSI P7N motherboard (nForce780), CUDA toolkit 3.0, driver 257.21. Everything was run through VNC (hopefully this is not the reason…).
Code:
cudaStream_t stream[3];
for (int i = 0; i < 3; ++i)
cudaStreamCreate(&stream[i]);
for (int i = 0; i < 3; ++i)
cudaMemcpyAsync(outAddrGPU+i, outAddr+i,
4, cudaMemcpyHostToDevice, stream[i]);
for (int i = 0; i < 3; ++i)
cudaMemcpyAsync(dataGPU+i*1024*512*8, dataPtr+i*1024*512*8,
(1024*512*8+32)*sizeof(unsigned int), cudaMemcpyHostToDevice, stream[i]);
for (int i = 0; i < 3; ++i)
ref_bin_sm <<< dimGrid, dimThrd, 0, stream[i] >>> (dataGPU+i*1024*512*8, resGPU[i], outAddrGPU+i, 0, 0x3f, 0x0);
for (int i = 0; i < 3; ++i)
cudaMemcpyAsync(resPtr+i*(128*1024*1024/8), resGPU[i],
(80*1024*1024/8)*sizeof(unsigned long long), cudaMemcpyDeviceToHost, stream[i]);
I have modified the host code in order to have host->device copies on stream0 and (kernel runs + device->host copies) in three other streams. Moreover, I put the three streams into a for loop, so that all streams run a kernel and memcopy 3 times. This way concurrent execution works more or less as I would have imagined.

Still, the first memcopy waits for all kernel runs to be finished, but at least further kernels and copies are overlapped. I am still not really satisfied with the results, as I thought streams are command queues where a command executes whenever it is possible (that is all previous commands from the same stream were executed and the required resource is free). But it seems to me that streams are more limited.
I have a more general problem with cudaMemcpyAsync.In my case, the number of data generated is not known before the kernel runs, therefore a global memory variable contains the number of outputs. The idea is to read this variable first, and then do a memcopy based on this value. That is:
(1) run the kernel
(2) memcopy number of results: RES
(3) memcopy RES output words
Unfortunately it does not work with cudaMemcpyAsync, as the number of bytes to be copied is passed to memcopy based on the value, not based on the reference. So when the second memcopy is queued into the stream this value is zero, it only gets the real value when the first memcopy was executed. Passing this parameter by reference would solve this kind of problem but I cannot really see a way to implement this with the current cudaMemcpyAsync function.
If an NVIDIA employee reads this maybe he can answer: is it possible to have a memcopy which passes all parameters by reference?
If anyone has an idea how to do a hack, I would really appreciate it.