I turned on MPS on Tesla T4 and found that MPS turned on and not turned on, the GPU Memory Usage on NVIDIA-SMI is the same.
Q1:Does MPS work?
Q2:Why the GPU Memory Usage occupied by CUDA programs is the same?
Q3:Why MPS Server always occupies 25Mib?I tested other applications with MPS turned on, it also takes 25Mib in NVIDIA-SMI, but I forgot to save the result.
Q1: Why did you post the output of nvidia-smi as pictures? Are you aware of cut & paste?
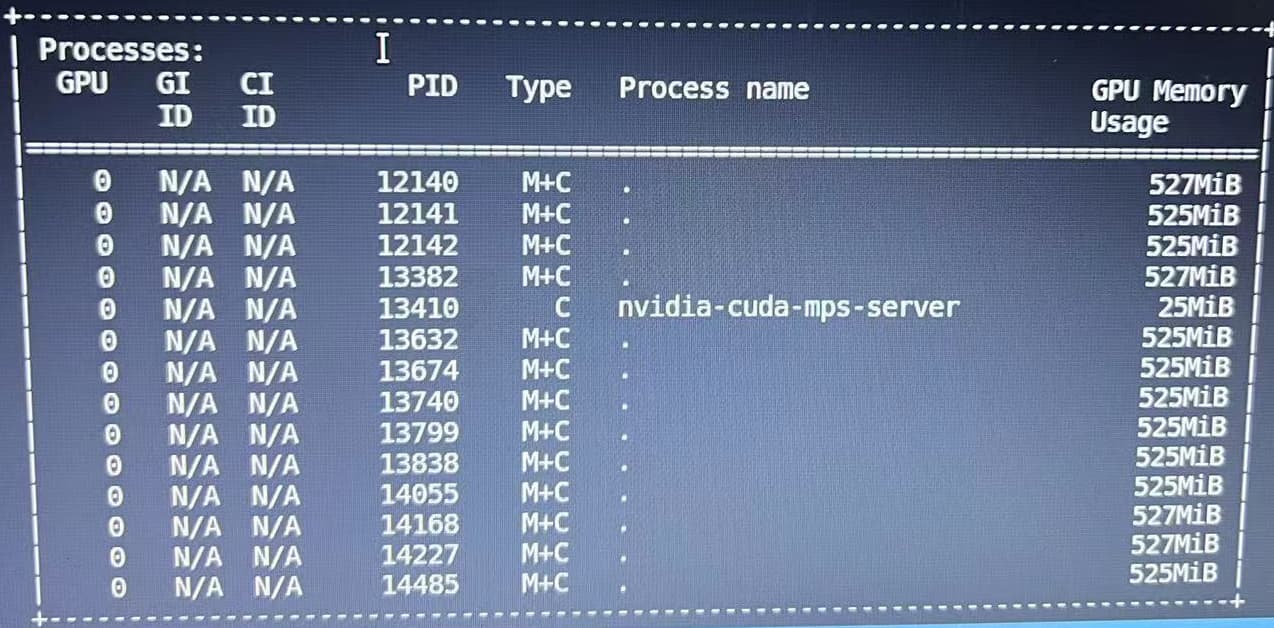
Q2: Does the first picture correspond to running without MPS, while the second picture corresponds to running with MPS? The type “M” in the second picture suggests this, please confirm.
Q3: What are the processes corresponding to the PIDs listed? Is it possible that these are multiple instances of the same application?
Q4: How do you know that the MPS Server “always occupies 25 MiB”? How many different experiments did you run to establish that? Assuming the observation can be generalized, and the MPS server does in fact always use 25 MiB, what would be the issue with that?
Yes. The first picture corresponds to running without MPS, and the second picture corresponds to running with MPS.
The MPS runs in docker, and the processes listed run in docker too.The type “M+C” in NVIDIA-SMI shows that all the processes are running under the scheduling of MPS. But the GPU Memory Usage is the same in both situation.
So I want to know whether the MPS works or not?
Why the memory usage is the same?
Whether MPS service shared the memory and context?
I tested it in two situation.
1:two different processes run in the same GPU Tesla T4.
2.same processes run in Tesla T4 and NVIDIA 2080Ti.
The MPS server always occupy 25 MiB under both situation. Because they are all after the Volta architecture, I want to know whether the mps server always occupy 25MiB after Volta.
It is still not clear what is being asked here. Is the question:
(1) Why do all processes listed (other than the MPS server) consume roughly 525 MiB?
(2) Why is there no significant difference in memory usage in the processes between running with and running without MPS?
If (1): These are possibly multiple instances of the same application, which in turn makes it likely that they require similar amounts of memory. I can neither confirm nor refute that working hypothesis remotely. You could, if you have access to the system.
If (2): Assuming that the exact same processes were active when running with and without MPS (something for you to confirm), why (in your thinking) should the amount of memory needed per process differ depending on whether MPS is active or not?
I cannot find anything about that in the documentation. Unless you can find guarantees provided by documentation, no assumptions can or should be made: In the absence of guarantees made by the vendor, the observation of memory usage is one of an implementation artifact, and may differ by software version, GPU characteristics, configuration settings.
They’re the same processes with same data, so in principle, it should occupy the same memory. But MPS will share cuda context, so when MPS is turned on, shouldn’t the occupied memory be smaller than when MPS is not turned on.
There is nothing here that suggests to me that MPS is not working.
You seem to have this idea:
That’s a false statement. I don’t know of anywhere in NVIDIA documentation where that claim is made.
It is true that with MPS on, that one way to think about work issuance across multiple processes is as if they were issued from a single context. But that is merely an idea used to aid understanding. It does not describe the actual situation.
Enabling MPS does not allow or force independent processes to use the same CUDA context.
So as already stated, there is no reason to conclude that enabling MPS will have any significant effect on CUDA process memory usage.
I assume, as a program that runs on a computer and executes and does various things, it requires memory, like most programs that I am familiar with. The detailed explanation of MPS memory usage is not provided or documented by NVIDIA, AFAIK.