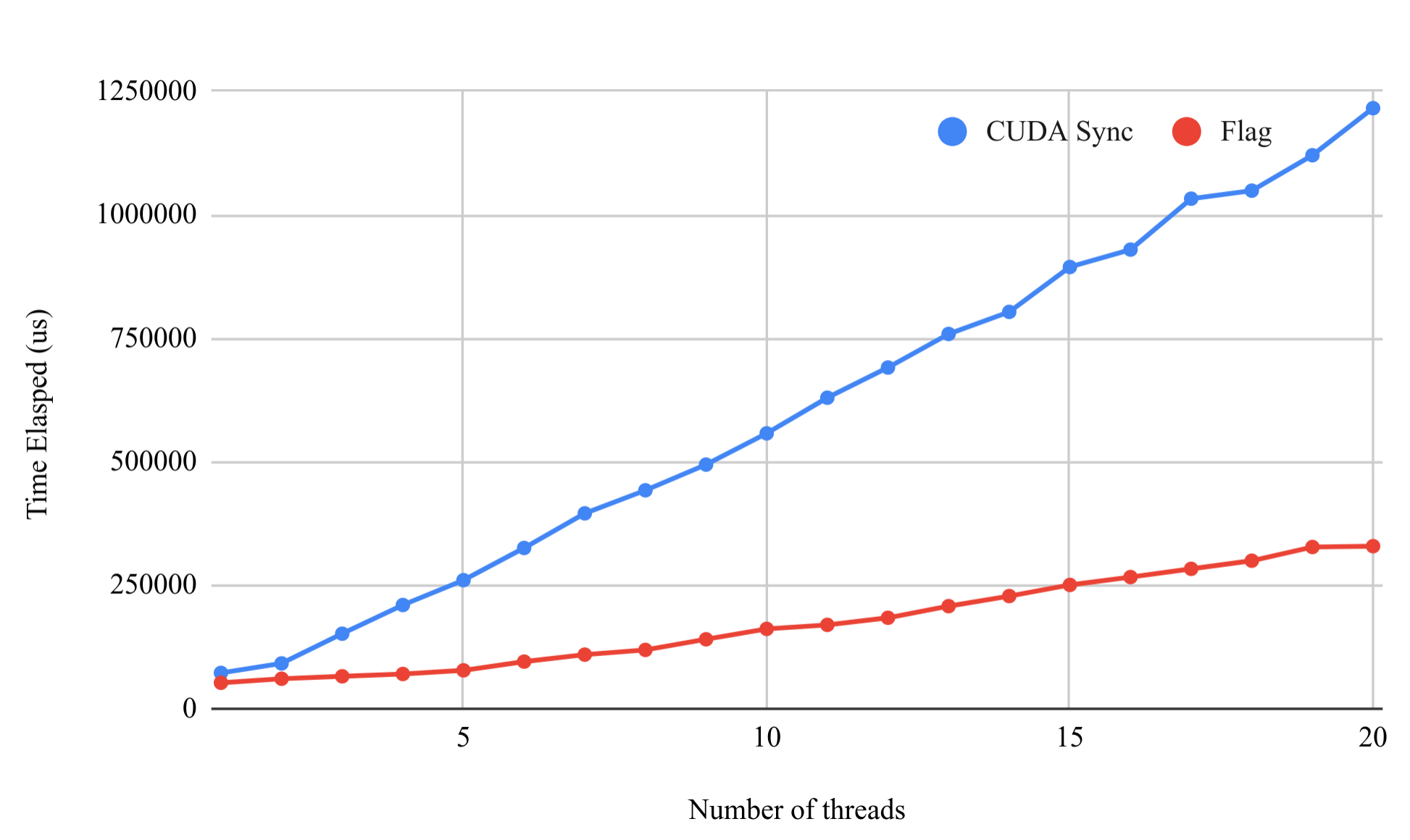
I am working on a project where I will need to run a bunch of small kernels concurrently. I realize that cudaStreamSynchronize has become the bottleneck. So, I tried to avoid cudaStreamSynchronize and use a flag-based approach: the kernel will set a flag in pinned memory as it completes, and the CPU code will busy poll on the flag until the flag is set. Below is an example code that compares the performance between cudaStreamSynchronize and the flag-based approach:
#include <cuda_runtime.h>
#include <cstdio>
#include <cstdlib>
#include <chrono>
#include <thread>
#include <vector>
__global__ void dummy_cuda_sync() {
}
__global__ void dummy_flag(volatile int* flag) {
*flag = 1;
}
void run_cuda_sync(int num_iter, cudaStream_t stream) {
for (int i = 0; i < num_iter; ++i) {
dummy_cuda_sync<<<1, 1, 0, stream>>>();
cudaStreamSynchronize(stream);
}
}
void run_flag(int num_iter, cudaStream_t stream, volatile int* flag) {
for (int i = 0; i < num_iter; ++i) {
*flag = 0;
dummy_flag<<<1, 1, 0, stream>>>(flag);
while (*flag == 0);
}
}
int main(int argc, char** argv) {
int num_iter = atoi(argv[1]);
int num_thrs = atoi(argv[2]);
std::vector<cudaStream_t> streams;
streams.resize(num_thrs);
for (int i = 0; i < num_thrs; ++i) {
cudaStreamCreate(&streams[i]);
}
volatile int* flags;
cudaMallocHost(&flags, sizeof(int) * num_thrs);
double time_cuda_sync;
double time_flag;
{
std::vector<std::thread> thrs;
auto start_time = std::chrono::steady_clock::now();
for (int i = 0; i < num_thrs; ++i) {
thrs.emplace_back(run_cuda_sync, num_iter, streams[i]);
}
for (auto& thr : thrs) {
thr.join();
}
auto end_time = std::chrono::steady_clock::now();
time_cuda_sync = std::chrono::duration<double, std::micro>(end_time - start_time).count();
}
{
std::vector<std::thread> thrs;
auto start_time = std::chrono::steady_clock::now();
for (int i = 0; i < num_thrs; ++i) {
thrs.emplace_back(run_flag, num_iter, streams[i], flags + i);
}
for (auto& thr : thrs) {
thr.join();
}
auto end_time = std::chrono::steady_clock::now();
time_flag = std::chrono::duration<double, std::micro>(end_time - start_time).count();
}
printf("%f,%f\n", time_cuda_sync, time_flag);
}
Why are the time linear to the number of threads? My kernel is so small that even when I run 20 at a time, the GPU should be able to run them concurrently and so the time it takes should not increase.
Why is cudaStreamSynchronize so much slower than the flag-based apporach?
So even with __threadfence_system(), flag-based approach is still much faster than cudaStreamSynchronize() especially when there is a high concurrency.
The CUDA runtime has known locking behavior when multiple threads use the CUDA runtime simultaneously. This could impact both kernel launches (which use the runtime under the hood) as well as explicit calls such as cudaDeviceSynchronize().
It’s possible they are not measuring the same thing. A kernel which has posted something in pinned memory is still running and has not released its resources back to the block scheduler/CWD. A kernel launched into a stream that has definitely reach a cuda stream sync point has definitely done those things.
More generally, back to the original idea, kernels whose duration is long compared to the launch overhead are going to make more efficient use of the GPU than kernels that are short relative to the launch overhead. So you are definitely operating in a region here that is known to be non-optimal.
Also, launch overhead, launch efficiency, and even multi-stream behavior are things that get worked on by the CUDA dev team from time to time. Therefore, if by chance you happen to be working on an old CUDA version (9.x would be “old” for example) you may discover better behavior with the latest CUDA releases.
Finally, you can affect the CUDA behavior at a sync point. You might wish to experiment with spin vs. yield.
Thank you for your reply. In an effort to understand how the lock of the CUDA runtime affects the performance of cudaStreamSynchronize, I tried to use cudaLaunchHostFunc to register a callback after each kernel, so that there will be only one CPU thread monitoring all streams.
I don’t know what the slowness is caused by. Your approach seems unwise to me, and adding additional CUDA runtime API calls to each kernel launch of tiny little kernels is only going to make the overhead problem worse.
I never had any trouble monitoring multiple streams from one CPU thread using cudaStreamQuery. I agree you may not like the performance of it if you use it to monitor kernels that have less than 50us duration, and I don’t have any further suggestions or comments on that topic.
It’s a bad idea. Taking a bad idea and grafting additional scaffolding on top of a bad idea is not going to make the bad idea any better.
It’s a bad idea. I doubt I would be able to comment further.
If you have a standard set of a sequence of very short kernels you want to run, CUDA graphs may offer some improvement, but its not going to provide any benefit for your “monitoring”.