I am trying to understand the overhead latency of using culaunchHostFunc.
I have for loop in main stream 0. I want that before every iteration some CPU code will run and finish. Therefore, in another stream, I plan to use culaunchHostFunc to send event to to CPU service (culaunchHostFunc will be quick) and after launch kernel that waits for signal from CPU. after the kernel i record event for stream 0.
Pseudo code:
for:
for:
stream 1:
- culaunchHostFunc
- kernel
- signal event
stream 0:
- wait event
- kernel
for (int i = 0; i < NUM_ITERATIONS; i++) {
// stream1:
cudaLaunchHostFunc(stream1, fastCallback, &iterationIndices[i]);
timeBasedSleepKernel<<<1, 1, 0, stream1>>>(sleepMicroseconds);
// Record event after sleep kernel completes in Stream 1
cudaEventRecord(events[i], stream1);
// stream0:
// Make Stream 0 wait for the event from Stream 1 before launching next computation
cudaStreamWaitEvent(stream0, events[i], 0);
// Launch computation kernel for next iteration in Stream 0
simulateWorkKernel<<<gridSize, blockSize, 0, stream0>>>(
d_buffer, dataSize, computeIterations);
}
Now there problem that latency of returning from CPU callback is not consistent if using multistreams:
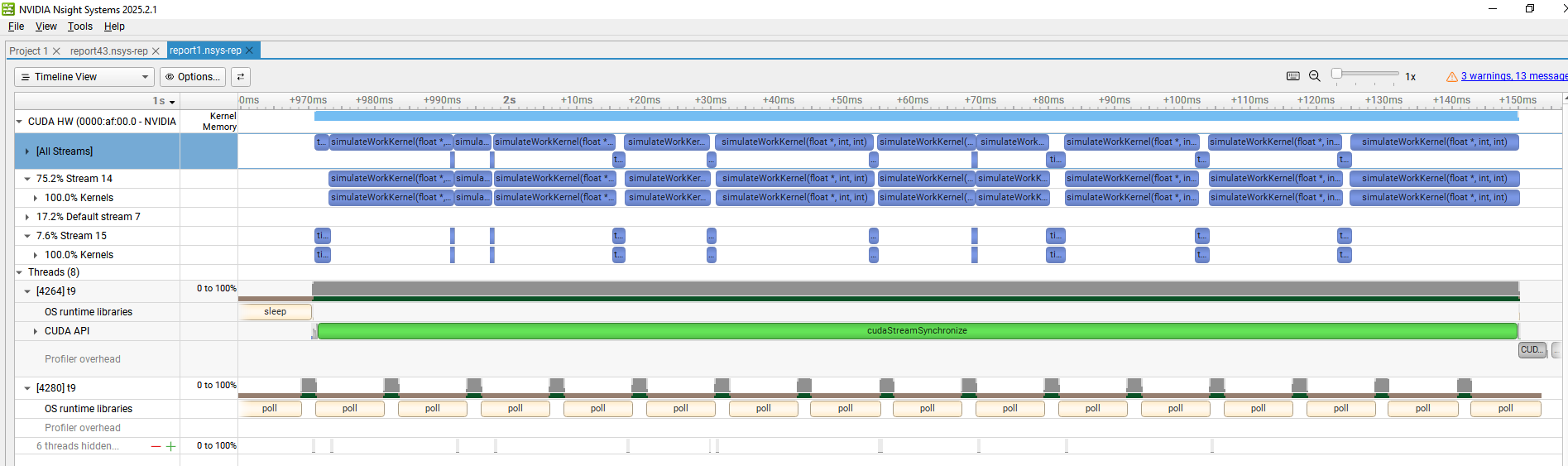
We can see here 12ms of overhead from CPU callback finish to stream 1 continue, where it does not happen every time.
Another strange thing is that if remove stream 0 the problem disappears
- Can someone explain why this happens?
- I would appreciate any advice on how to implement the flow explained above.
Many thanks.
If you are launching a host func from each stream, those host funcs may be processed in a single extra CPU thread spun up by CUDA, and therefore may be serialized. The serialization could give rise to additional latency.
The code in gray in your post doesn’t really align with your pseudo code; so I can’t really tell what you are doing. Therefore I don’t know if this is the issue or not.
I am sorry i had a mess in the pseudo code… fixed it
I am not launching CPU callbacks from many streams but from only one stream.
@Robert_Crovella
I don’t have any further comments. I would need to see a complete test case, and even then I may or may not make any discoveries. The complete test case should include a full compilable code, preferably as short as possible - just completing what you have already shown. It should include the exact compile command, the GPU you are running on, and the platform details (OS, CUDA version). If this does happen to be windows WDDM, I generally don’t spend much time trying to figure out work-ordering issues on that platform, there are various challenges that tend to interfere with ideal ordering.
cuLaunchHostExample.txt (7.2 KB)
@Robert_Crovella
I have attached the full code.
It’s pretty simple and and main body is the for loop explained above. I am running on Linux and used both A100 & H100 GPU’s.
Compiled with nvcc release 12.6, V12.6.68, without additional compilation flags:
nvcc example.cu -o example
I don’t see any variability in the spacing of the timeBasedSleepKernel. Running your code as-is, on a L4 GPU on linux, CUDA 12.2, and also on a A40 GPU on linux, CUDA 12.8.1, this is what I see in the nsys timeline, it does not look like your timeline excerpt, the spacing of the timeBasedSleepKernel (in stream 15) follows the ordering/spacing of the simulateWorkKernel(in stream 14) exactly, with no variability that I can see:
It’s remotely possible that CUDA 12.6 had an issue that does not manifest in CUDA 12.2 nor CUDA 12.8. I don’t have a CUDA 12.6 machine handy to test on. If your CPUs are busy with other work unrelated to this application/process, I suppose that might be another explanation. The callbacks are launched in a thread. There is no guarantee as to how the OS will schedule that thread, and I would assume that if the CPU/system has a large number of busy threads, its entirely possible that the worker thread spun up by the CUDA runtime to process callbacks could get “starved” from time to time. If such possibilities don’t seem plausible to you, no further ideas come to mind, for me.
@Robert_Crovella
Thank you very much for the response, appreciate it.
I will look more into it.