I’m sharing a repository Docker-Yolov7-Nvidia-Kit which I’ve meticulously built to streamline the end-to-end process of model training (PyTorch), model quantization (PyTorch), model exportation (ONNX), model building (TensorRT/Triton-Server), and model utilization using DeepStream. The idea behind creating this repository was to establish a seamless, hassle-free workflow, sparing users from excessive effort.
To streamline the process, I’ve created a git repository containing three components:
- Docker Yolov7 - Supports model training, quantization and export (ONNX).
- Docker Triton-Server-Yolov7 - Utilizes models Yolov7 FP16 and Yolov7 QAT (INT8) in ONNX format to builds engines, and makes them available via Triton-Server.
- Docker Deepstream-Yolov7 - Deepstream application designed to utilize
file://orrtsp://as input sources, perfom inference over Yolov7 Models (via triton-server) and employ RTSP Server for output.
Note: TheDocker Deepstream-Yolov7relies onTriton-Server-Yolov7to be operational.
The ONNX model was exported using the Efficient NMS plugin to achieve the following advantages:
- The plugin implements a very efficient NMS algorithm which largely reduces the latency of this operation in comparison to other NMS plugins.
- The parsing function provided by NvDsInferYolov7EfficientNMS for Gst-nvinferserver manage the number of classes dynamically becomes effortlessly achievable. In contrast, with all other plugins, it’s necessary to hardcode the number of classes
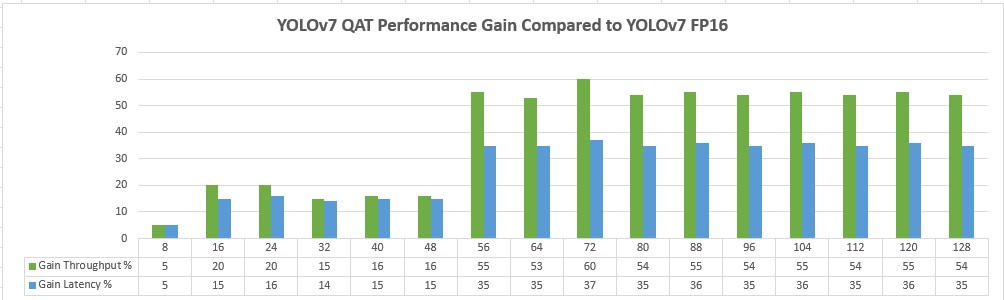
Perfomance
The Yolov7 QAT model has shown significant improvements compared to Yolov7 FP16 in both throughput and latency, reaching up to 1220 inferences per second with a latency of 39 milliseconds (25.6 fps) on a single GPU RTX 4090
Below is a graph comparing the performance results of YOLOv7 FP16 versus YOLOv7 Quantization-Aware Training (QAT) at 640x640 resolution on a single GPU RTX 4090 - AMD Ryzen 7 3700X 8-Core setup


Yolov7 QAT Accuracy
Accuracy assessment of the YOLOv7 QAT model should be conducted at various stages: during training (using PyTorch) and after converting the model to a TensorRT engine. It is essential to evaluate the model’s accuracy not only in the PyTorch format but also considering its final inference deployment using TensorRT. Therefore, I’ve made enhancements to the repository to incorporate accuracy measurement using the pycocotools tool for models in the TensorRT engine format.
Video Processed using Deepstream Sample App

Training Repo Enhancements
The Yolov7_quat repository, originally forked from the Nvidia yolo_deepstream repository, was tailored to implement end-to-end Onnx export functionality, along with various enhancements, including an added capability for training custom datasets. These improvements are thoroughly outlined within the repository’s documentation.
The Yolov7 repository originally forked from the Original Yolov7 repository to support the latest versions of PyTorch, accommodating architectures such as Hopper/Ada and few enhancements.
This post represents an enhancement to the discussion found at (Deepstream / Triton Server - YOLOv7)