This command will create an ONNX model with an efficientNMS node. To be able to map the model outputs from efficientNMS to the NVIDIA NvDsObjectMeta data structure you need this code which needs to be added/compiled in /opt/nvidia/deepstream/deepstream-6.1/sources/libs/nvdsinfer_customparser/nvdsinfer_custombboxparser.cpp
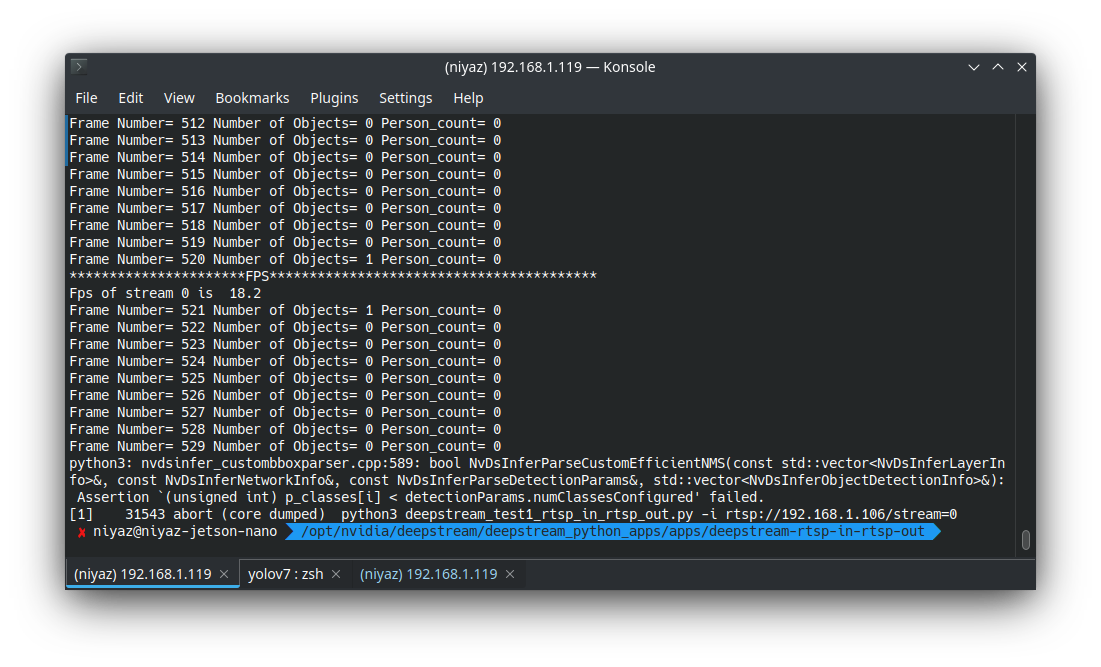
The issue is probably that you have not updated num-detected-classes=91 to be correct for the model you are running. This assertion checks that any detected class from the model is less than this num-detected-classes variable.
When I run ‘sudo -E make install’ I get the following problems which don’t seem realted to the code posted above (Jeston Xavier NX):
g++ -o libnvds_infercustomparser.so nvdsinfer_custombboxparser.cpp nvdsinfer_customclassifierparser.cpp -Wall -std=c++11 -shared -fPIC -I…/…/includes -I /usr/local/cuda-11.4/include -Wl,–start-group -lnvinfer -lnvparsers -Wl,–end-group
In file included from /usr/include/aarch64-linux-gnu/NvInferRuntimeCommon.h:19,
from /usr/include/aarch64-linux-gnu/NvInferLegacyDims.h:16,
from /usr/include/aarch64-linux-gnu/NvInfer.h:16,
from /usr/include/aarch64-linux-gnu/NvCaffeParser.h:16,
from …/…/includes/nvdsinfer_custom_impl.h:126,
from nvdsinfer_custombboxparser.cpp:25:
/usr/local/cuda-11.4/include/cuda_runtime_api.h:147:10: fatal error: crt/host_defines.h: No such file or directory
147 | #include “crt/host_defines.h”
| ^~~~~~~~~~~~~~~~~~~~
compilation terminated.
In file included from /usr/include/aarch64-linux-gnu/NvInferRuntimeCommon.h:19,
from /usr/include/aarch64-linux-gnu/NvInferLegacyDims.h:16,
from /usr/include/aarch64-linux-gnu/NvInfer.h:16,
from /usr/include/aarch64-linux-gnu/NvCaffeParser.h:16,
from …/…/includes/nvdsinfer_custom_impl.h:126,
from nvdsinfer_customclassifierparser.cpp:25:
/usr/local/cuda-11.4/include/cuda_runtime_api.h:147:10: fatal error: crt/host_defines.h: No such file or directory
147 | #include “crt/host_defines.h”
| ^~~~~~~~~~~~~~~~~~~~
compilation terminated.
make: *** [Makefile:41: libnvds_infercustomparser.so] Error 1
I was able to run the model using the provided tutorial on x86 architecture but when trying to run it in jetson docker, am facing the same issue. Seems like the C files are not available in the docker.
Please let me know if you were able to find a workaround.
Jetson docker does not have the libraries to build the static library. You will need to build it on the host by installing deepstream directly on host.
I’m having some doubts here, maybe somebody could jump in.
I’m running DS 6.0 on a Jetson Nano. Resnet10 and stuff works. Also yolo7tiny with an “inherited” setup.
Now I wanted to start from scratch and followed the advices given here.
While trying to run it I’m getting this, and I can’t figure out, what to do:
UID = 1]: Trying to create engine from model files
WARNING: [TRT]: onnx2trt_utils.cpp:366: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: DLA requests all profiles have same min, max, and opt value. All dla layers are falling back to GPU
ERROR: [TRT]: 4: [shapeCompiler.cpp::evaluateShapeChecks::832] Error Code 4: Internal Error (kOPT values for profile 0 violate shape constraints: reshape would change volume. IShuffleLayer /model/model.77/Reshape: reshaping failed for tensor: /model/model.77/m.0/Conv_output_0)
ERROR: Build engine failed from config file