Can anybody help me understand why stride-2 access of 4-byte words in L1 cache only results in one wavefront, while stride-2 access to shared-memory results in two wavefronts (Magnus Strengert makes this point in both his excellent presentations S32089 and S41723, but I could not understand this point). Since both L1 cache and shared memory use the same 32-banked memory that is partitioned into shared-mmeory and L1 cache, won’t two cycles be needed for stride-2 access to shared-memory and L1 cache to access the needed 32 words from the 16 banks that will hold the words?
Hi saday, thanks for watching the GTC presentations! Your comment that a 4byte access with stride-2 requires two cycles to fetch the data from the memory banks is correct. The source of the mismatch come from the fact that the concept of a wavefront is different from the actual accesses/conflicts to the memory banks.
Looking at the mental model of the L1TEX pipeline from S32089 (repeated for completeness below), the wavefronts are counted in the TAG stage. This is also encoded in the sub-string l1tex__t in the metric l1tex__t_output_wavefronts_pipe_lsu_mem_global_op_ld that we use to collect these wavefronts. It’s the amount of work items we send further down the pipeline to fulfill the current request. Not all requests can be processed in a single wavefront. How many wavefronts are needed per request depends on multiple factors, including the hardware architecture and the memory access pattern.
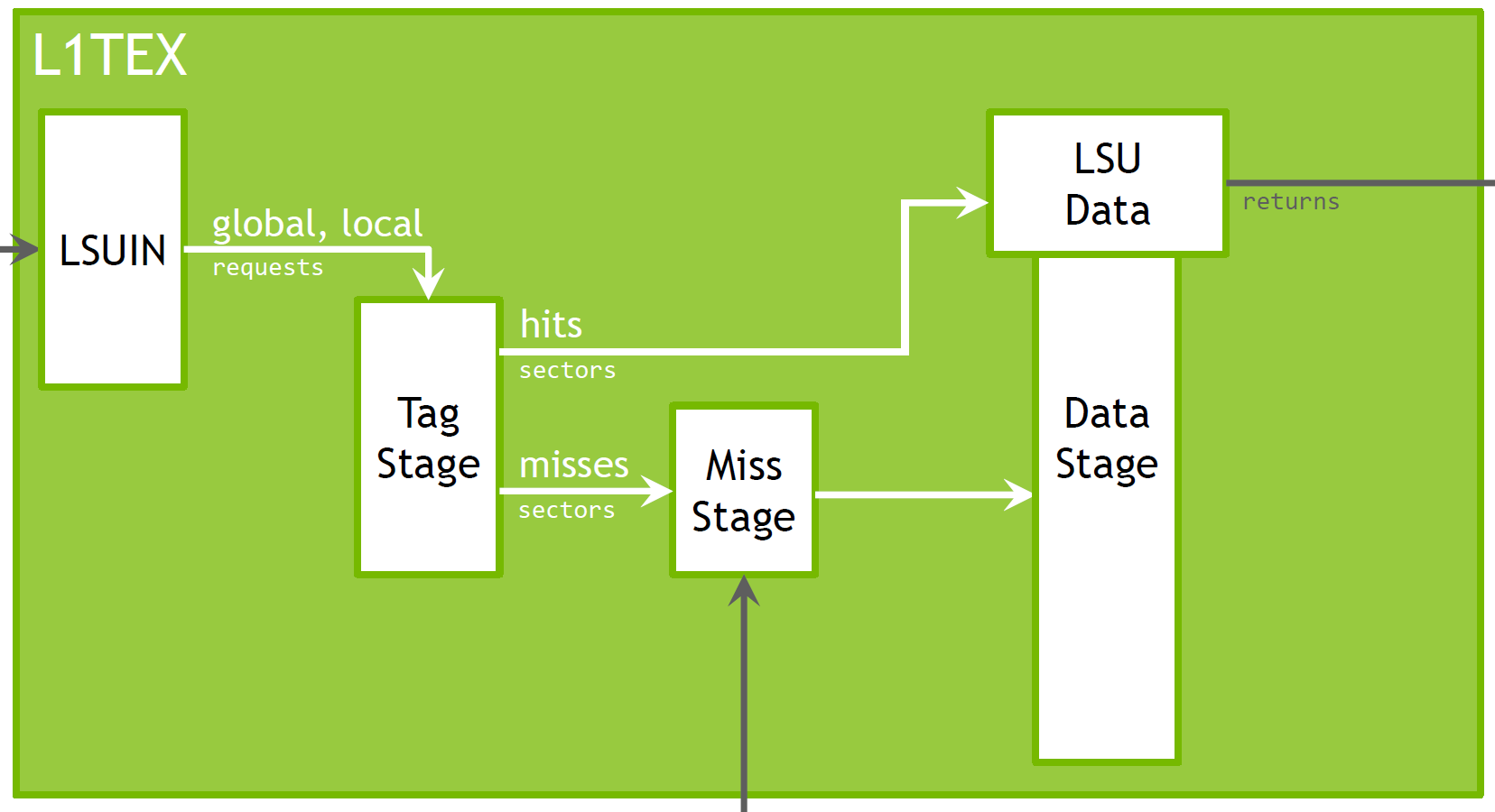
In contrast, the cycles it takes to access the data of a wavefront from the memory banks is a property of the Data stage. And it behaves exactly as you described already.
Both stages can cause a request to require extra cycles by either requiring multiple wavefronts and/or multiple bank accesses. I hope that helps to better describe the difference.
2 Likes