Hello, I have some questions about the following two kernels. Because I can’t explain some metrics correctly according to my understanding.
Environment
A100-PCIe-40GB
CUDA 11.8
Descriptions
Both of the kernels load matrix of size 1024x1024 half type matrix (row-major) from global memory to another part of global memory.
Kernel 1: using LDGSTS instruction to load data from global memory to shared memory. The shared memory size is 64x(64 + 8) in half type, 64x64 is the real memory size to contain the matrix tile, but a pad 8 half elements to the end of each tile row to avoid bank conflict for the following ldmatrix instructions(not included in the demo kernel).
#include <sys/time.h>
#include <cuda_profiler_api.h>
#include <cuda.h>
#include <cuda_fp16.h>
#include <cuda_runtime.h>
#include <stdio.h>
#include <cuda_pipeline.h>
#include <bits/stdc++.h>
using namespace std;
#define OFFSET_ROW(row, col, lda) ((row) * (lda) + (col))
#define CHECK_CUDA2(func) \
{ \
cudaError_t status = (func); \
if (status != cudaSuccess) { \
printf("CUDA API failed at line %d with error: %s (%d)\n", \
__LINE__, cudaGetErrorString(status), status); \
} \
}
__global__ void test_ldgsts(
const int M, const int N, const int K,
const half* d_matrixB_row_major,
half* d_store_back
) {
const int block_idx_x = blockIdx.x;
assert(block_idx_x == 0);
const int block_idx_y = blockIdx.y;
const int lane_id = threadIdx.x % 32;
constexpr const int stage = 2;
const int tileB_size = 64 * (64 + 8);
__shared__ half tileBblock[64 * (64 + 8) * stage];
#define LOAD_TILEB(smem_st_ptr, gmem_ld_ptr) \
{ \
float4* dst; \
float4* src; \
for (int tileK_iter_inner = 0; tileK_iter_inner < 16; tileK_iter_inner++) { \
dst = (float4*)(&tileBblock[(smem_st_ptr) * tileB_size + \
(tileK_iter_inner * 4 + lane_id / 8) * (64 + 8) + lane_id % 8 * 8]); \
src = (float4*)(&d_matrixB_row_major[((gmem_ld_ptr) * 64 + \
tileK_iter_inner * 4 + lane_id / 8) * N + block_idx_y * 64 + lane_id % 8 * 8]); \
__pipeline_memcpy_async(dst, src, sizeof(float4)); \
} \
}
#define STORE_TILEB(smem_st_ptr, gmem_ld_ptr) \
{ \
float4* dst; \
float4* src; \
for (int tileK_iter_inner = 0; tileK_iter_inner < 16; tileK_iter_inner++) { \
dst = (float4*)(&tileBblock[(smem_st_ptr) * tileB_size + \
(tileK_iter_inner * 4 + lane_id / 8) * (64 + 8) + lane_id % 8 * 8]); \
src = (float4*)(&d_store_back[((gmem_ld_ptr) * 64 + \
tileK_iter_inner * 4 + lane_id / 8) * N + block_idx_y * 64 + lane_id % 8 * 8]); \
*src = *dst; \
} \
}
//! no pipe but ldgsts
int tileK_iter = 0;
for (; tileK_iter < K / 64; tileK_iter++) {
LOAD_TILEB(tileK_iter % 2, tileK_iter)
__pipeline_commit();
__pipeline_wait_prior(0);
__syncthreads();
STORE_TILEB(tileK_iter % 2, tileK_iter)
}
}
void my_test_ldgsts(
int M, int N, int K,
half* h_matrixB_row_major
) {
half* h_check_matrixB = (half*)malloc(sizeof(half) * K * N);
half* d_matrixB_row_major;
CHECK_CUDA2(cudaMalloc(&d_matrixB_row_major, sizeof(half) * K * N));
half* d_matrixB_row_major_check;
CHECK_CUDA2(cudaMalloc(&d_matrixB_row_major_check, sizeof(half) * K * N));
CHECK_CUDA2(cudaMemcpy(d_matrixB_row_major, h_matrixB_row_major, sizeof(half) * K * N, cudaMemcpyHostToDevice));
int Tile_N = 64;
dim3 blockDim(32, 1, 1);
dim3 gridDim(1, ceil(N / Tile_N));
test_ldgsts<<<gridDim, blockDim>>>(M, N, K, d_matrixB_row_major, d_matrixB_row_major_check);
CHECK_CUDA2(cudaGetLastError());
CHECK_CUDA2(cudaMemcpy(h_check_matrixB, d_matrixB_row_major_check, sizeof(half) * K * N, cudaMemcpyDeviceToHost));
CHECK_CUDA2(cudaDeviceSynchronize());
for (int i = 0; i < K; i++) {
for (int j = 0; j < N; j++) {
if ((float)h_check_matrixB[i * N + j] != (float)h_matrixB_row_major[i * N + j]) {
printf("(%d,%d)device %.2f vs host %.2f\n", i, j, (float)h_check_matrixB[i * N + j], (float)h_matrixB_row_major[i * N + j]);
break;
}
}
}
}
Kernel 2: using LDGSTS instruction, but the shared memory is 64x64. I use the swizzle format to avoid bank conflict for the following ldmatrix instructions.
__global__ void test_ldgsts(
const int M, const int N, const int K,
const half* d_matrixB_row_major,
half* d_store_back
) {
const int block_idx_x = blockIdx.x;
assert(block_idx_x == 0);
const int block_idx_y = blockIdx.y;
const int lane_id = threadIdx.x % 32;
constexpr const int stage = 2;
const int tileB_size = 64 * 64;
__shared__ half tileBblock[64 * 64 * stage];
#define LOAD_TILEB_SWIZZLE(smem_st_ptr, gmem_ld_ptr, smem_len) \
{ \
float4* dst; \
float4* src; \
for (int tileK_iter_inner = 0; tileK_iter_inner < 16; tileK_iter_inner++) { \
int row = tileK_iter_inner * 4 + lane_id / 8; \
int col = lane_id % 8 * 8; \
col = col ^ ((row & 0x7) << 3); \
dst = (float4*)(&tileBblock[ \
(smem_st_ptr) * 64 * (smem_len) + \
OFFSET_ROW(row, col, (smem_len))]); \
src = (float4*)(&d_matrixB_row_major[((gmem_ld_ptr) * 64 + \
tileK_iter_inner * 4 + lane_id / 8) * N + block_idx_y * 64 + lane_id % 8 * 8]); \
__pipeline_memcpy_async(dst, src, sizeof(float4)); \
} \
}
#define STORE_TILEB_SWIZZLE(smem_st_ptr, gmem_ld_ptr, smem_len) \
{ \
float4* dst; \
float4* src; \
for (int tileK_iter_inner = 0; tileK_iter_inner < 16; tileK_iter_inner++) { \
int row = tileK_iter_inner * 4 + lane_id / 8; \
int col = lane_id % 8 * 8; \
col = col ^ ((row & 0x7) << 3); \
dst = (float4*)(&tileBblock[ \
(smem_st_ptr) * 64 * (smem_len) + \
OFFSET_ROW(row, col, (smem_len))]); \
src = (float4*)(&d_store_back[((gmem_ld_ptr) * 64 + \
tileK_iter_inner * 4 + lane_id / 8) * N + block_idx_y * 64 + lane_id % 8 * 8]); \
*src = *dst; \
} \
}
//! swizzle ldgsts no pad
int tileK_iter = 0;
for (; tileK_iter < K / 64; tileK_iter++) {
LOAD_TILEB_SWIZZLE(tileK_iter % 2, tileK_iter, 64)
__pipeline_commit();
__pipeline_wait_prior(0);
__syncthreads();
STORE_TILEB_SWIZZLE(tileK_iter % 2, tileK_iter, 64)
}
}
Nsight compute reports
| metrics | Kernel1 | Kernel2 |
|---|---|---|
| SMEM | ||
| Instructions | 4096 | 4096 |
| wavefronts | 16384 | 16384 |
| bank conflicts | 0 | 0 |
| L1/TEX Cache(Global Load to Shared Store Bypass) | ||
| Instructions | 4096 | 4096 |
| wavefronts | 8192 | 4096 |
| sectors | 98304 | 65536 |
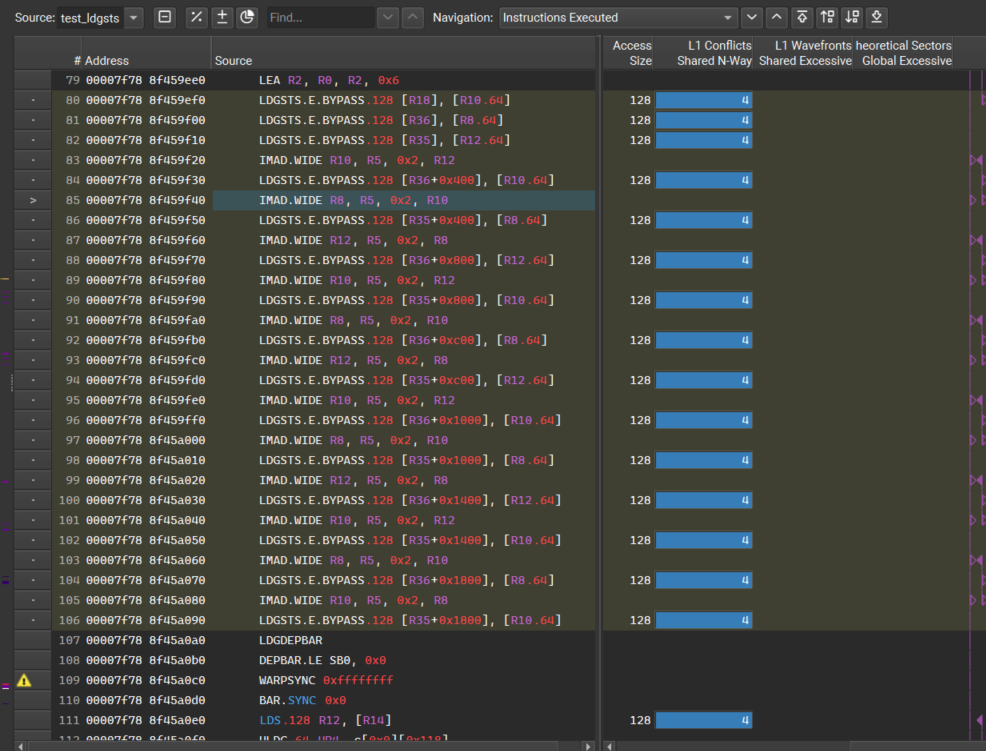
Kernel 1:


Kernel 2:

Questions
- What is the relationship between “L1 Conflicts Shared N-way” with bank conflicts? According to Nsight Compute documents, the wavefront means the units that can be processed in parallel. If an instruction makes every thread access 128bit consecutive memory. Then every 8 threads will access 128byte consecutive memory, and there is no bank conflict, and will cause 4 cycles(or wavefronts?) to execute this instruction. So the L1 conflicts shared N-way is wavefronts/instruction = 4. But in Kernel 1, the L1 conflicts shared N-way is an average of 10, which means it takes 10 wavefronts to execute the instruction, and it still has no bank conflict, why?
- Why are the “L1 wavefronts shared excessive” and “L2 Theoretical Sectors Global Excessive” both not zero in Kernel 1? The access pattern in Kernel 1 is every 8 threads loads 128-byte data from global memory to shared memory, while in shared memory data is not consecutive stored across the subwarp. The L1/L2 cache line is 128 bytes, so I can’t understand the excessive.