Description
Hi, I have an issue regarding dynamic batch size on CRNN-like model with Bi-LSTM inside. I encounter incorrect output when I am using batch > 1 (please see Test 2,3, and 4), thank you for your help.
FYI, I have tested other models (object detection, and other things with static shape), and they are working normally. Which means that the Tensor-RT+Python+OS has no issue (at least on CNN-like models).
Note: I could send you the model through the email, kindly await for your reply, thanks
[Test 1]
If use fixed conversion, aka.
trtexec --onnx=“ocr_recog.onnx” --shapes=‘x’:1x3x32x320 --saveEngine=“net_recog.trt” --explicitBatch --workspace=4096
and do inference on batch=1, the output will be nonzeros (0 to 1), which is correct!
Snapshot with batch=1:

[Test 2]
However, If I use model from [Test 1], then I modify the shape after the TRT-conversion using these:
self.context.active_optimization_profile = 0
orishape_ctx = self.context.get_binding_shape(0)
print('ori shape: ', orishape_ctx)
print('ori shape now: ', self.context.get_binding_shape(0), xshape)
self.allocate_buffers(x.shape)
The output will be correct for the first batch, not on batch > 1 (i.e. if I feed my model with 3 batch, batch 1’s output is correct, but batch 2 & 3 are incorrect).
Snapshot with batch>1:
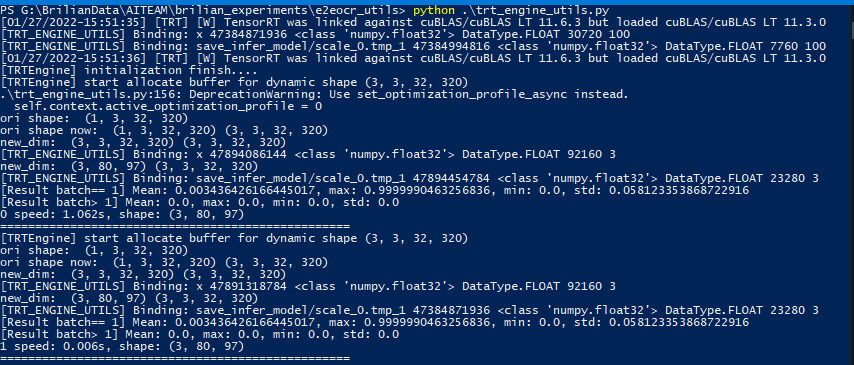
[Test 3]
If I try to modify the fixed ONNX using build_engine as in this blog, this blog, or Nvidia repo, I could also built the model successfully.
Then, I try to load the model, and change the “-1” as in the blog link above, then all returned inference output is zero. I’ve also tried to send only batch: 1, and it also returns zero results (the result shape is correct, but the min, max, and std values are 0.0).
After that, I tries to use Logger with trt.Logger.VERBOSE, then I get these silent error:
[01/27/2022-15:30:14] [TRT] [E] 3: [executionContext.cpp::nvinfer1::rt::ShapeMachineContext::resolveSlots::1480] Error Code 3: API Usage Error (Parameter check failed at: executionContext.cpp::nvinfer1::rt::ShapeMachineContext::resolveSlots::1480, condition: allInputDimensionsSpecified(routine)
)
[01/27/2022-15:30:14] [TRT] [E] 2: [executionContext.cpp::nvinfer1::rt::ExecutionContext::enqueueInternal::366] Error Code 2: Internal Error (Could not resolve slots: )
Snapshot of [Test 3 and 4] with batch=1:

Snapshot of [Test 3 and 4] with batch>1:

[Test 4]
I’ve also tried to convert my text recognition model from ONNX to Tensor-RT with trtexec. It is successfully convereted. The command looks like this:
trtexec --onnx=“ocr_recog_dnm.onnx” --optShapes=‘x’:50x3x32x320 --minShapes=‘x’:1x3x32x320 --maxShapes=‘x’:100x3x32x320 --saveEngine=“net_recog.trt” --explicitBatch --workspace=4096
When I test the model with batch size: 1 or more, the output value will also always 0 (tested with min, max, mean, and std). And it also has the [Test 3]'s silent error.
Environment
Windows 10.
CUDA 11.1
Tensor-RT 8.2.1.8
Python 3.8.10
TensorRT Version: 8.2.1.8 (Windows version, after links the path to env. variable, then just pip install on the tensorrt_8xx/python/ folder).
GPU Type: RTX3070
Nvidia Driver Version: 471.41
CUDA Version: (11.1 on my env.path) (11.4 on nvidia-smi)
CUDNN Version: 8.2.1 (checked on cudnn_version.h in cudnn/include)
Operating System + Version: Win10 10.0.19044
Python Version (if applicable): 3.8.10
PyTorch Version (if applicable): 1.9.x
Relevant Files
Please kindly send your email, then I will send it immediately.