Hello this is the first time I ask for help on a forum, I hope I will be able to be clear and give you all the necessary information, thank you for your indulgence if you need more information to help me I would provide them quickly of course
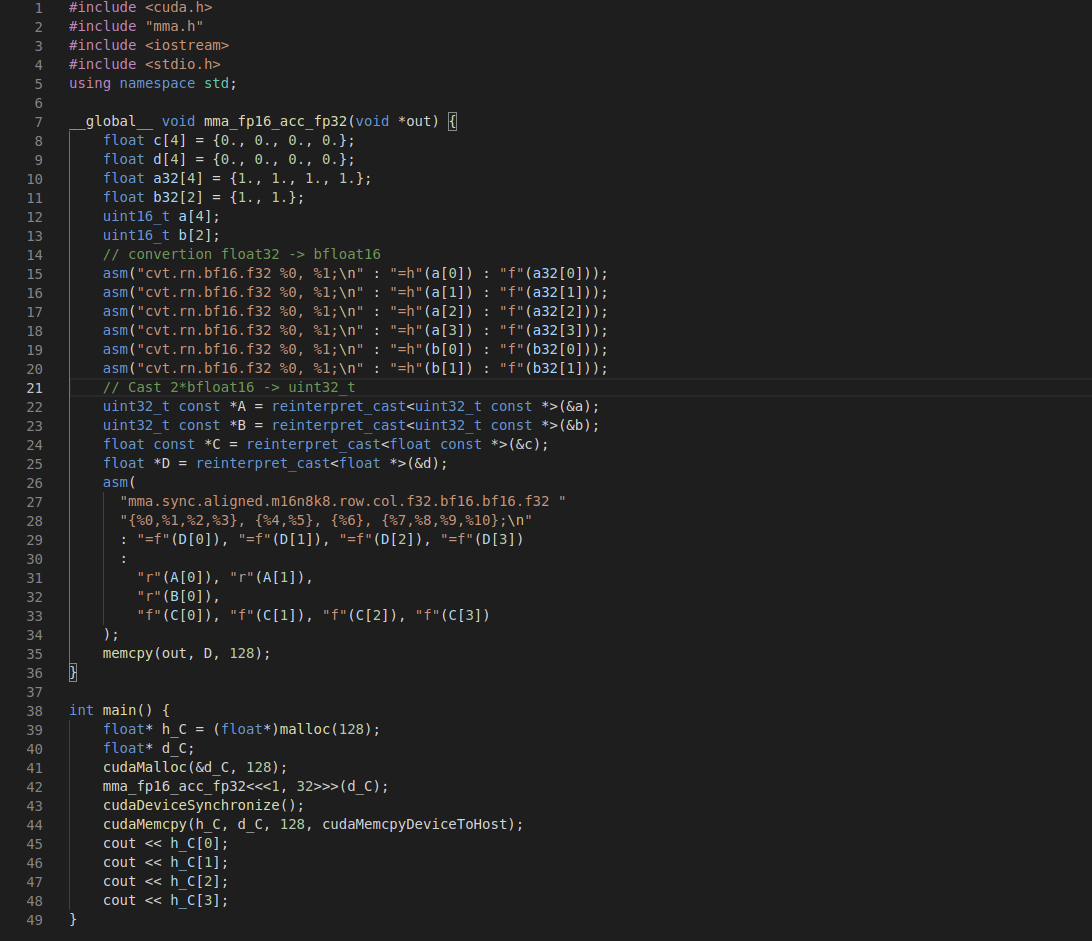
I am trying to use the Mma instruction, I was using an rtx3080, I copied the cultass implementation mma sm80 for my use.
Here is my problem I do not really know what Mma instruction is doing I thought this one would do a simple matrix multiplication:
resulta = [ [(a[0] * b[0] + a[0] * b[1]) + d[0] ],
[ (a[1] * b[0] + a[1] * b[1]) + d[1] ],
[ (a[2] * b[0] + a[2] * b[1]) + d[2] ],
[ (a[3] * b[0] + a[3] * b[1]) + d[3] ]]
if i have an error in my implementation surely in the transformation of the float32 into bfloat16 or in the combination of two bfloat16 into float32.
Or otherwise the conversion operations are correct and if someone can explain to me the operations of the operation Mma thank you very much!
{kind=link}
here are the results of my tests
Resulta 1:
a = {1, 1, 1, 1}
b = {1, 1}
c = {0, 0, 0, 0}
D = {8, 8, 8, 8}
Resulta 2:
a = {1, 1, 1, 1}
b = {1, 1}
c = {1, 1, 1, 1}
D = {9, 9, 9, 9}
Resulta 3:
a = {2, 2, 2, 2}
b = {1, 1}
c = {0, 0, 0, 0}
D = {16, 16, 16, 16}
Resulta 4:
a = {2, 2, 2, 2}
b = {1, 1}
c = {0, 0, 0, 0}
D = {16, 16, 16, 16}
Resulta 5:
a = {2, 1, 1, 1}
b = {1, 1}
c = {0, 0, 0, 0}
D = {12, 12, 8, 8}
Resulta 6:
a = {1, 1, 1, 2}
b = {1, 1}
c = {0, 0, 0, 0}
D = {8, 8, 12, 12}
Resulta 6:
a = {1, 1, 1, 2}
b = {1, 1}
c = {0, 0, 0, 0}
D = {8, 8, 12, 12}
Resulta 7:
a = {0.2, 0.2, 0.2, 0.2}
b = {0.2, 0.2}
c = {0, 0, 0, 0}
D = {0.320625, 0.320625, 0.320625, 0.320625}
Resulta 8:
a = {0.2, 0.4, 0.2, 0.2}
b = {0.2, 0.2}
c = {0, 0, 0, 0}
D = {0.480938, 0.480938, 0.320625, 0.320625}
Resulta 8:
a = {0.2, 0.4, 0.2, 0.2}
b = {0.2, 0.2}
c = {2, 4, 8, 1.5}
D = {2.48094, 4.48094, 8.32063, 1.82063}