My company acquired a workstation a few months ago with a RTX 3090 for training/inference of deep learning models, specifically transformer-based models running on pytorch. The workstation came with additional slots, and we immediately add an existing RTX 3060 card which was already running regularly on another workstation.
Since we first started using it, we always get an error which first freezes the UI for a couple of minutes, then when it’s available again, a process running on either of the GPUs is crashed, with an “ERR!” showing on nvidia-smi. Usually the 3090 is the one to crash, but sometimes happens to the 3060 as well. The affected GPU only works again after the workstation is rebooted.
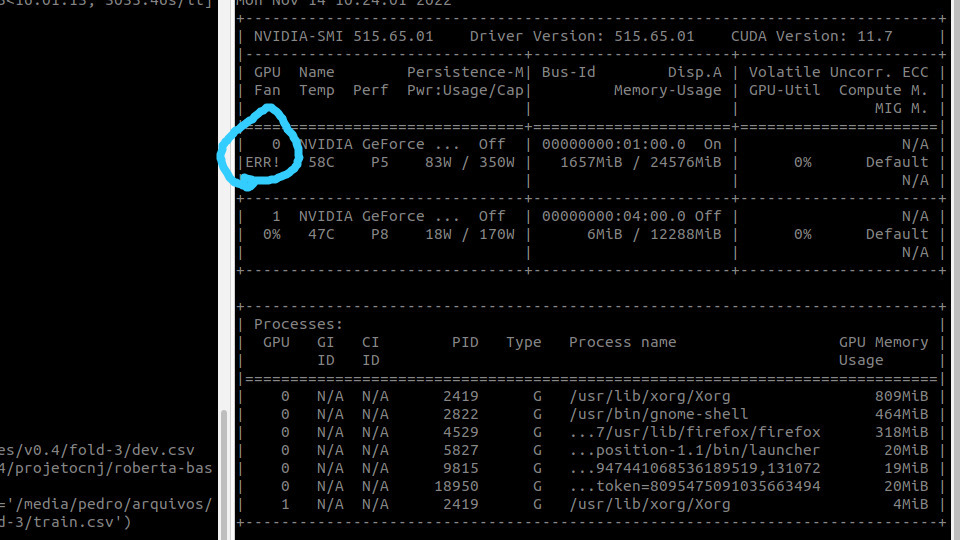
I have already tested a bunch of nvidia drivers, from 510 to 525, with the corresponding CUDA drivers, from 11.3 to 12.0. Already tried switching different pytorch versions from 1.12 to nightly 2.0, but the same thing happens. I couldn’t notice anything wrong in the attached nvidia-bug report. I need to know how I could debug this issue, find out what’s going on. The stacktrace from the model doesn’t have any information, it’s always “Cuda error: no kernel image is available for execution on the device” once the driver is not longer available; the actual error never gets printed in the stacktrace because it’s not rooted in the model itself.
The workstation was first setup with Linux Mint 20.3 (ubuntu 20.04), but we have already tested it with Ubuntu 22.04 as well. Already formatted twice, and it always happens with a fresh environment. The firmware of the 3090 was updated back when the debugging for this started.
I had some support from the vendor requesting to run a benchmark on superposition, but nothing happened.

nvidia-bug-report.zip (500.6 KB)
I have also tried leaving only one of the cards, but eventually the error happens with either of them, so it doesn’t look like it’s related to be running two different cards.
The motherboard is an ASRock Z690 Pro RS, and the GPUs are MSI RTX 3090 and Gigabyte RTX 3060.