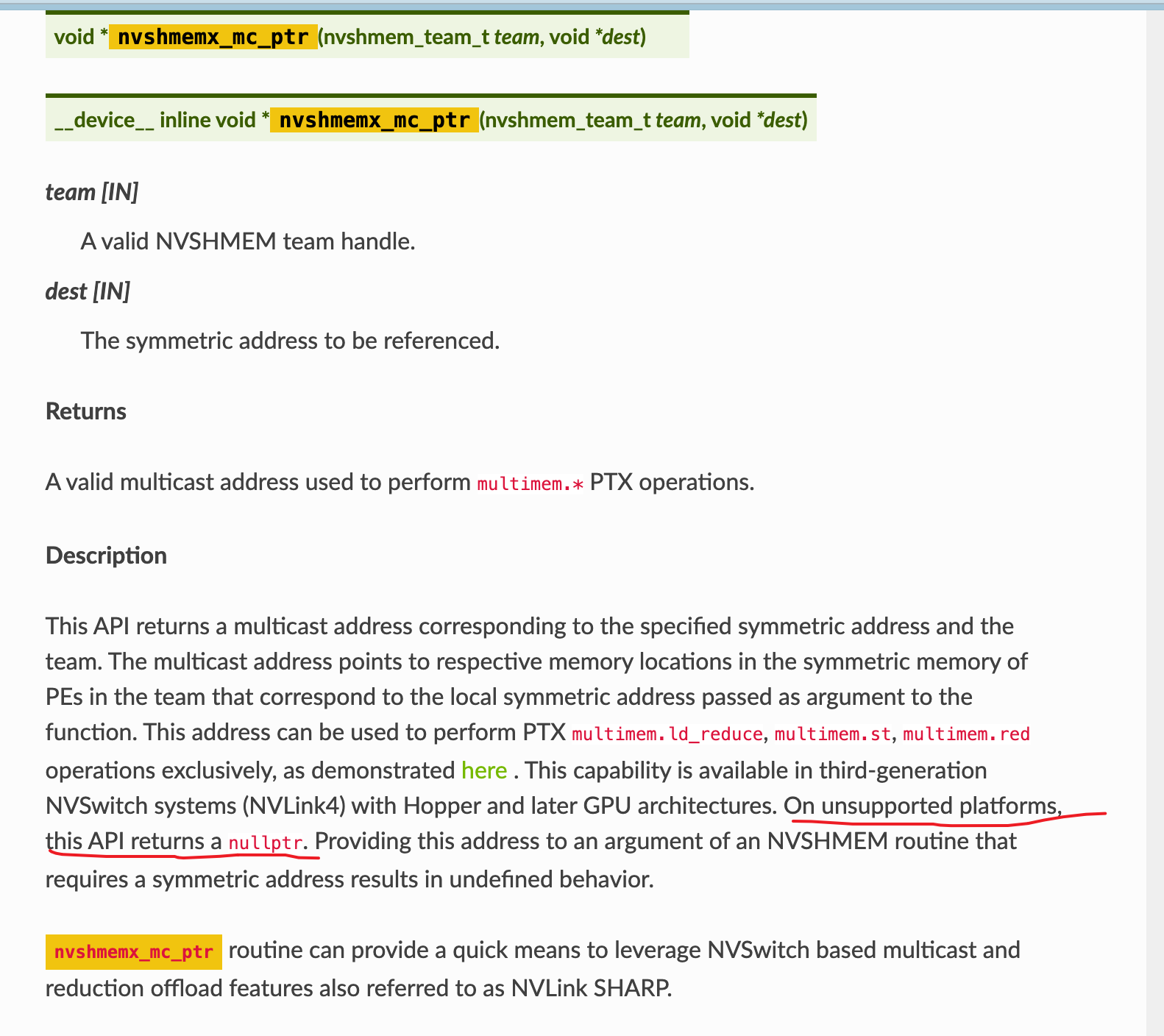
but when i run nshmemx_mc_ptr() the program core dumps when i set NVSHMEM_DISABLE_CUDA_VMM=1 on a H800 machine, when i dump into the gdb core, it’s nvshmemx_mc_ptr:
I think nvshmem may provide an API that tells me if NVLS is used in a team. I don’t want to process the logic to check if the hardware support NVLS or if the team support NVLS or if env NVSHMEM_DISABLE_CUDA_VMM is set or not.
but when i run nshmemx_mc_ptr() the program core dumps when i set NVSHMEM_DISABLE_CUDA_VMM=1 on a H800 machine, when i dump into the gdb core, it’s nvshmemx_mc_ptr:
Thanks for pointing it out. This is a known defect on 3.2 release when the user explicitly disables VMM (which is necessary to use NVLS feature) - we have internally also identified the same and addressed the problem and fix should be available in our 3.3 release. The workaround for this in 3.2 is to use __device__ void *nvshmemx_mc_ptr(nvshmem_team_t team, const void *ptr) directly on the user kernel directly instead of calling this API on the host and passing the multicast address to the user kernel, if that works for your usecase.
I think nvshmem may provide an API that tells me if NVLS is used in a team. I don’t want to process the logic to check if the hardware support NVLS or if the team support NVLS or if env NVSHMEM_DISABLE_CUDA_VMM is set or not.
The intent of this API to provide the capability that you are asking i.e given a team and symmetric buffer address, provide a equivalent symmetric multicast address. Once this defect is fixed, it should be work reliably for your use cases.