I am trying to parallelise a python code that basically does a matrix multiplication.
I am using PYCUDA for this, but I think my question is not really linked to Pycuda in particular but to the way cuda works in general.
The computation takes the form C=A*B.
The matrices A and B are initialized in python and are global inputs of my program (their allocation time is not taken in consideration here). I send them to the GPU and I compute the result C=A*B on it.
The computation of the matrix product in itself is way faster than the python multiplication using numpy.
But the problem is the time transfert of the variables to the GPU. In practice, transfering A and B to the GPU, and getting the result C from the GPU to python is longer than the global python execution time.
In fact the time that the matrix transfers to the GPU is approximately the total time of my PyCuda program. Indeed, the matrix computation in itself is negligible.
My question is : how can I improve the speed of this program ?
I think it is a very common problem because I know that PyCuda is sometimes used to improve matrix multiplication speed. But here I see that the transferring times between GPU and CPU memories is the limiting factor and because of it there is no interest for me to use CUDA… which I find strange bc I have read that CUDA is often used for such computations.
Here is my code :
#!python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Dans ce code on essaie de comprendre les temps de calcul et les bytes par s de transfert memoire
import time
import numpy as np
from pycuda import driver, compiler, gpuarray, tools
import math
import matplotlib.pyplot as plt
from sys import getsizeof
# -- initialize the device
import pycuda.autoinit
# -----------------------------------------------------
# CUDA parameters
kernel_code_template = """
__global__ void MatProd(float* C, float* A, float* B, int dimAx, int dimBx, int dimCx, int dimCy)
{
int row = blockDim.y*blockIdx.y+threadIdx.y;
int col = blockDim.x*blockIdx.x+threadIdx.x;
double Result = 0;
if (row<=dimCy-1 && col<=dimCx-1)
{
for (int k = 0; k < dimAx; k++)
{
Result += A[k + dimAx*row] * B[col + dimBx*k];
}
C[col + row*dimCx] = Result;
}
}
"""
# get the kernel code from the template
kernel_code=kernel_code_template
# compile the kernel code
mod = compiler.SourceModule(kernel_code)
# get the kernel function from the compiled module
MatProd = mod.get_function("MatProd")
warp_size=32 # Warp size on the GPU.
# --------------------------------------------------------------------
# --------------------BEGIN of INITIALISATION-------------------------
# --------------------------------------------------------------------
# We create the python matrices for the computation C=A*B
# This part is supposed as an input, so we don't take in account any computation
# time here.
nb_columnsA=100
nb_linesA=pow(10,6)
nb_columnsB=2
nb_linesB=nb_columnsA
a_cpu=np.random.rand(nb_linesA,nb_columnsA).astype(np.float32)
b_cpu=np.random.rand(nb_linesB,nb_columnsB).astype(np.float32)
# --------------------------------------------------------------------
# --------------------End of INITIALISATION---------------------------
# --------------------------------------------------------------------
# --------------------------------------------------------------------
# --------------------CUDA PART---------------------------------------
# --------------------------------------------------------------------
# We send the data to the GPU
total_CUDA_time_Begin=time.clock()
time_memory_alloc_GPU_Begin=time.clock()
a_gpu = gpuarray.to_gpu(a_cpu)
b_gpu=gpuarray.to_gpu(b_cpu)
# We allocate the memory on the GPU for the result C=A*B
c_gpu = gpuarray.empty((nb_linesA, nb_columnsB), np.float32)
time_memory_alloc_GPU_End=time.clock()
# ----------------------------------------------------------
# Starting of the CUDA computation :
# We reserve the number of threads per block on the memory
threadPerBlockx=warp_size
threadPerBlocky=warp_size
# We reserve a number of block on the memory.
BlockPerGridx = (int) (1 + (nb_columnsB - 1) // threadPerBlockx);
BlockPerGridy = (int) (1 + (nb_linesA - 1) // threadPerBlockx);
time_computation_CUDA_Begin=time.clock()
MatProd(
# output
c_gpu,
# inputs
a_gpu, b_gpu,
np.int32(nb_columnsA),np.int32(nb_columnsB),np.int32(nb_columnsB),np.int32(nb_linesA),
# (only one) block of MATRIX_SIZE x MATRIX_SIZE threads
block = (threadPerBlockx, threadPerBlocky, 1), grid=(BlockPerGridx,BlockPerGridy)
)
time_computation_CUDA_End=time.clock()
time_memory_get_result_GPU_Begin=time.clock()
c_gpu_result=c_gpu.get() # We get the result
time_memory_get_result_GPU_End=time.clock()
total_CUDA_time_End=time.clock()
# --------------------------------------------------------------------
# --------------------END OF CUDA PART--------------------------------
# --------------------------------------------------------------------
# --------------------------------------------------------------------
# --------------------PYTHON PART-------------------------------------
# --------------------------------------------------------------------
# We compute in python :
total_Python_time_Begin=time.clock()
c_cpu=np.empty([nb_linesA,nb_columnsB]).astype(np.float32)
time_computation_Python_Begin=time.clock()
c_cpu=np.dot(a_cpu,b_cpu)
time_computation_Python_End=time.clock()
total_Python_time_End=time.clock()
# --------------------------------------------------------------------
# --------------------END OF PYTHON PART------------------------------
# --------------------------------------------------------------------
#------------------------------------------------------------
# We display the execution times :
# Computation times :
time_computation_CUDA=time_computation_CUDA_End-time_computation_CUDA_Begin
time_computation_Python=time_computation_Python_End-time_computation_Python_Begin
print("CUDA pure computation time : ", time_computation_CUDA)
print("Python pure computation time : ", time_computation_Python)
print(" ")
# Memory allocation times :
time_memory_alloc_GPU=time_memory_alloc_GPU_End-time_memory_alloc_GPU_Begin
time_memory_get_result_GPU=time_memory_get_result_GPU_End-time_memory_get_result_GPU_Begin
print("CUDA memory allocation time (allocating C, transferring A,B from CPU to GPU):", time_memory_alloc_GPU)
print("CUDA getting result from GPU (Pulling back C from GPU to CPU after computation) :", time_memory_get_result_GPU)
# Total time (computation + memory allocation)
print(" ")
total_CUDA_time=total_CUDA_time_End-total_CUDA_time_Begin
total_Python_time=total_Python_time_End-total_Python_time_Begin
print("CUDA total time (alloc C + A to gpu + B to gpu + comput + get result) :", total_CUDA_time)
print("Python total time (comput + alloc C) :", total_Python_time)
Here are the outputs :
CUDA pure computation time : 0.0002852345678547863
Python pure computation time : 0.032470123456732836
CUDA memory allocation time (allocating C, transferring A,B from CPU to GPU): 0.17344750617121463
CUDA getting result from GPU (Pulling back C from GPU to CPU after computation) : 0.16262162962812
CUDA total time (alloc C + A to gpu + B to gpu + comput + get result) : 0.3363879506177909
Python total time (comput + alloc C) : 0.04350814814824844
We thus remark that indeed the computation time is way faster in CUDA than in Python, but because of the memory transfer from CPU to GPU and from GPU to CPU the CUDA code is still slower than the python one.
What’s more the CUDA computation time is negligible in regard of these allocations time.
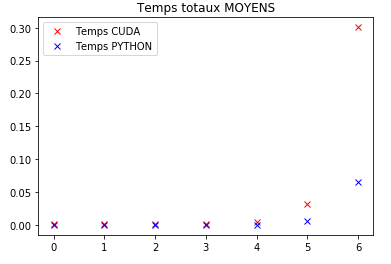
In this example C=A*B, I worked with A matrix : 100 columns and 10^6 lines and B matrix : 100 lines and 2 columns but I also did a code that plot the computation and allocation time in function of k, where number of line of A = 10^k
The k is the x-axis of thoose graph (so the matrix has from 1 lines to 10^6 lines).
This first graph shows the total time.
For GPU it means : transferring A & B from CPU to GPU, allocating C on GPU, computing C=A*B, and transferring at the end C from GPU to CPU
For Python it means : allocating C and computing A*B (I remind that A and B are global inputs and are not taking in consideration when measuring computation time for python)
This second graph shows the allocation & data transfer time.
For the GPU it means : transferring A & B from CPU to GPU, allocating C on GPU and transferring at the end C from GPU to CPU;
For Python it means : allocating C.
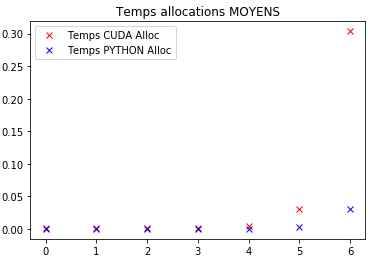
Thus again : how can I increase the speed of matrices transfer between Python and Cuda ? Because it seems the parallelised code will never be faster as the none parallelised one just because of thoose memory transfers. I find this strange bc CUDA is often used to improve speed of such operations.
Remark : I am on MSI GT72 with GTX 970M graphic card.