because it depends on the exact pattern of addresses across the warp, to determine bank conflicts. And in addition to 4 float vs. 8 float, there are addressing pattern differences.
understanding how shared bank conflicts arises depends on a certain amount of explanation. You can find such in unit 4 of this online tutorial series and many other places on the web.
In a nutshell, you must consider the address pattern across the warp on an instruction-by-instruction basis, and if each thread is loading (in a single instruction issue) more than 4 bytes, you must consider the address pattern on a transaction-by-transaction basis. Each transaction will be no more than 128 bytes warp-wide, that is; when the entire warp is requesting more than 128 bytes at the point of a single SASS instruction issue, then the memory controller will break that into multiple transactions.
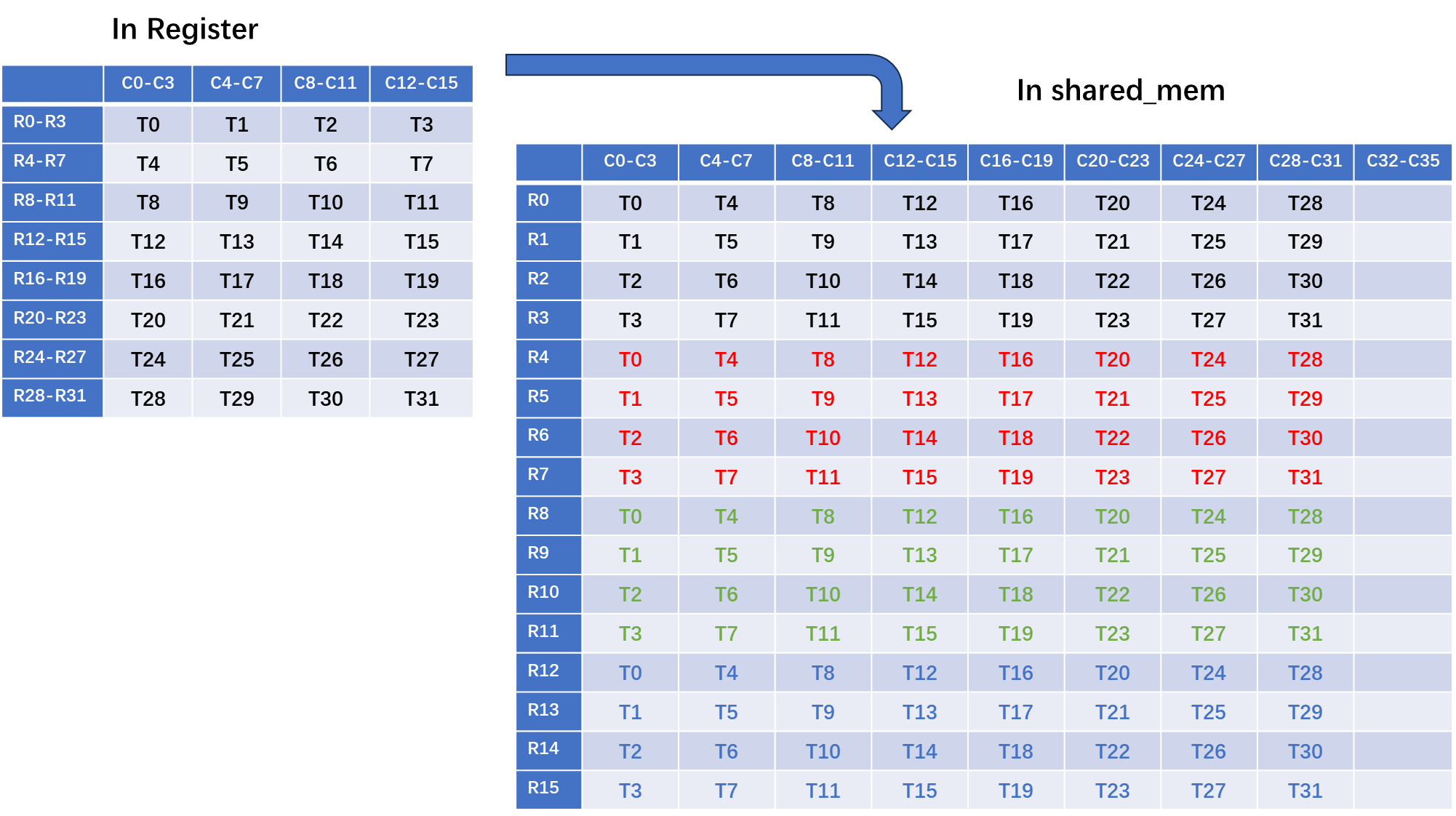
The address pattern generated by each thread in the warp must be considered against the bank pattern. Shared memory is broken into banks, which can be thought of as columns if shared is arranged in a 2D format, where each column is 4 bytes wide and there are 32 columns. You can see pictorial examples of thinking/looking at shared that way, at the top of this thread.
When the addressing pattern is such that there is no more than one item needed per column, then you will have an not-bank-conflicted access. When the addressing pattern is such that there are two or more items needed in a single column, there will be bank conflicts.
When you write a code like this:
sharedMem[factor*tid + i] = input[base+factor*tid + i];
and factor == 1, then the address pattern across the warp is that each thread will have an address that is adjacent to its neighbor threads. This will result in one item per column needed in shared, and this will be non-bank-conflicted.
When factor is 2 or higher, you run into the possibility that multiple items will be needed in a single column. This will result in bank conflicts.
For example if factor is 2, on the first iteration of the loop (i is zero), the address index pattern is:
warp lane: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
index: 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62
In this case we see that thread at warp lane zero is requesting item at index 0. Thread at warp lane 16 is requesting item at index 32, this is in the same shared column as index 0. This produces 2-way bank conflict.
This sort of analysis is necessary to statically determine bank conflicts in the general case. Its tedious, so I won’t do it repeatedly.
When I am teaching CUDA, I often mention that if you observe that an index is created using threadIdx.x as an additive factor only in the index creation, that will produce adjacent indexing across a warp, and that is canonically good for either coalescing considerations or bank-conflict considerations. Its not the only possible bank-conflict-free pattern, but it is one of them.
The first example I gave (factor == 1) fits this description. The second example I gave (factor == 2) does not fit this rubric.