Hello, i have a question about my cuda programming.
For making accelerating the programming, I made a simple code to cuda programming.
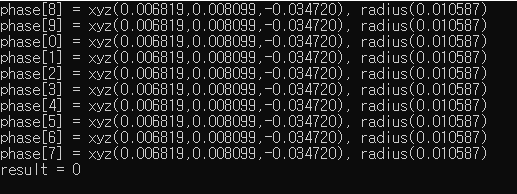
However, i got a problem such as no numbers return except zero. I looked up several times but using a host with my source code worked very well. So i tried to find out the programming in CUDA source but i cannot find a problem.
For making a AoS(array on structure) in CUDA, I made a followin codes.
#include <iostream>
#include <chrono>
#include <cstdlib>
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#define maxNum 10
#define THREADS 4
typedef struct test {
float x, y, z;
}points;
__device__ int dmax = -0.05;
__device__ int dmin = 0.066;
__device__ double dradius = 0.2;
__device__
double sqrts(double a) {
return sqrt(a);
}
__device__
double dv_pow(double a, double b) {
return (double)pow(a, b);
}
__global__ void function(points *devin, int *dev_count, int size) {
int idx = threadIdx.x + blockDim.x*blockIdx.x;
if (idx < size) {
float xa = devin[idx].x;
float ya = devin[idx].y;
float za = devin[idx].z;
double radius = sqrts((dv_pow((double)xa, 2.0) + dv_pow((double)ya, 2.0)));
__syncthreads();
int start = 0;
printf("phase[%d] = xyz(%f,%f,%f), radius(%lf)\n", idx, devin[idx].x, devin[idx].y, devin[idx].z, radius);
if ((xa != 0 && ya != 0 && za != 0) && za < dmin || za > dmax || radius >= dradius) {
start++;
}
}
}
int main() {
int limit = maxNum;
srand((unsigned)time(NULL));
points *alpha;
alpha = new points[limit];
for (int i = 0; i < limit; i++) {
/*
0.006819 0.008099 -0.034720
0.005938 0.007701 -0.035073
0.005802 0.007906 -0.035066
0.005667 0.008112 -0.035059
0.005532 0.008317 -0.035052
0.005396 0.008523 -0.035045
0.005243 0.008714 -0.035046
0.005096 0.008910 -0.035045
0.004949 0.009106 -0.035044
0.004801 0.009302 -0.035042
*/
alpha[i].x = 0.006819;
alpha[i].y = 0.008099;
alpha[i].z = -0.034720;
}
points *dev_alpha;
int counts=0, *dev_count;
cudaError(cudaMalloc((void**)&dev_alpha, sizeof(points)*limit));
cudaError(cudaMalloc((void**)&dev_count, sizeof(int)));
cudaError(cudaMemcpy(dev_alpha, alpha, sizeof(points)*limit, cudaMemcpyHostToDevice));
cudaError(cudaMemcpy(dev_count, &counts, sizeof(int), cudaMemcpyHostToDevice));
dim3 threads(THREADS);
dim3 blocks((limit + THREADS - 1) / THREADS);
function<<<blocks, threads>>>(dev_alpha, dev_count, limit);
cudaError(cudaMemcpy(&counts, dev_count, sizeof(int), cudaMemcpyDeviceToHost));
printf("result = %d\n", counts);
cudaError(cudaFree(dev_alpha));
cudaError(cudaFree(dev_count));
delete[] alpha;
return 0;
}
This is my main function.
please help me to find a problem.
Thank you!
ps. I will attach the result images.