Dear experts,
I’m a beginner in CUDA programming.
I was following the to perform a parallelised host-to-device memcpy and I wrote the example code below.
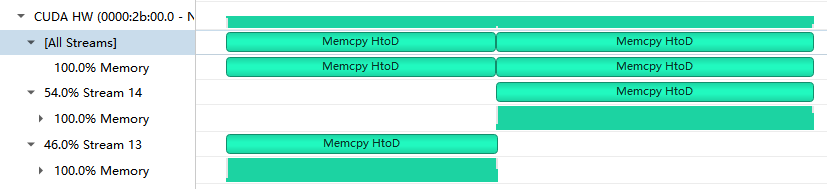
However when I run the nsight systems “trace” I found that the memcpy’s don’t seem to be parallelised, as shown in the attached picture.
May i ask what was missed in the example code or this can be done by other approaches?
Thanks ahead!
Brown
void Routine()
{
cudaStream_t s1;
cudaStream_t s2;
CUDA_CHECK(cudaStreamCreate(&s1));
CUDA_CHECK(cudaStreamCreate(&s2));
double* host_1;
double* host_2;
CUDA_CHECK(cudaHostAlloc(&host_1, MYSIZE, cudaHostAllocDefault));
CUDA_CHECK(cudaHostAlloc(&host_2, MYSIZE, cudaHostAllocDefault));
double* device_1;
double* device_2;
CUDA_CHECK(cudaMallocAsync(&device_1, MYSIZE, s1));
CUDA_CHECK(cudaMallocAsync(&device_2, MYSIZE, s2));
CUDA_CHECK(cudaMemcpyAsync(device_1, host_1, MYSIZE, cudaMemcpyHostToDevice, s1));
CUDA_CHECK(cudaMemcpyAsync(device_2, host_2, MYSIZE, cudaMemcpyHostToDevice, s2));
// clean up
CUDA_CHECK(cudaFreeHost(host_1));
CUDA_CHECK(cudaFreeHost(host_2));
CUDA_CHECK(cudaFreeAsync(device_1, s1));
CUDA_CHECK(cudaFreeAsync(device_2, s2));
CUDA_CHECK(cudaStreamDestroy(s1));
CUDA_CHECK(cudaStreamDestroy(s2));
}