I am using iGPU on Jetson AGX Orin for Matrix Vector Multiplication.
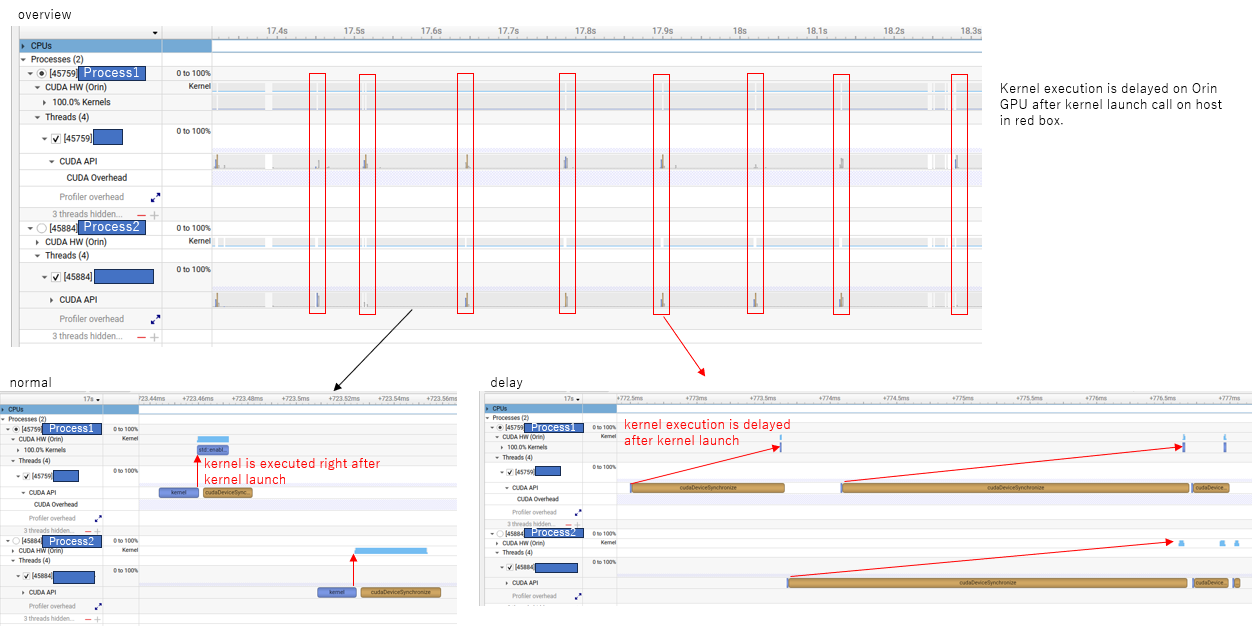
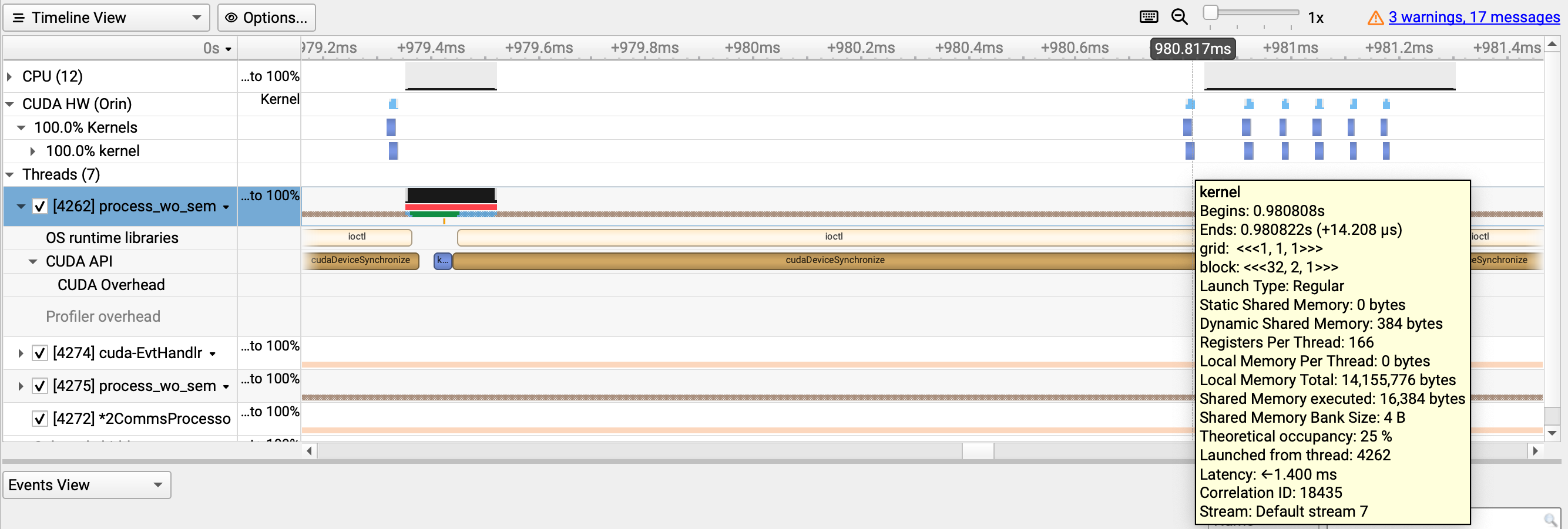
Issue is captured in below pictures from nsys.
Top: Overview of 2 processes using CUDA HW (Orin).
Lower-left: Kernel is executed right after kernel launch, which is normal behavior.
Lower-right: Kernel execution is delayed after kenerl launch. The delay happens frequently and appears to be approximately 100ms cyclical.
In my application, cublassSgemv() is used for Matrix Vector Multiplication.
The same issue is observed when reducing the size of matrix and vector (just 4x2 matrix and 2x1 vector).
Do you have any thought about the occurance which appear to be approximately cyclical?
One possible cause is that the tasks are waiting in the queue when submitting to the GPU.
Please try to increase the work queue number to see if it helps:
$ export CUDA_DEVICE_MAX_CONNECTIONS=32
Here is the corresponding document for your reference:
If this doesn’t help, could you share a reproducible source and steps so we can try it in our environment as well?
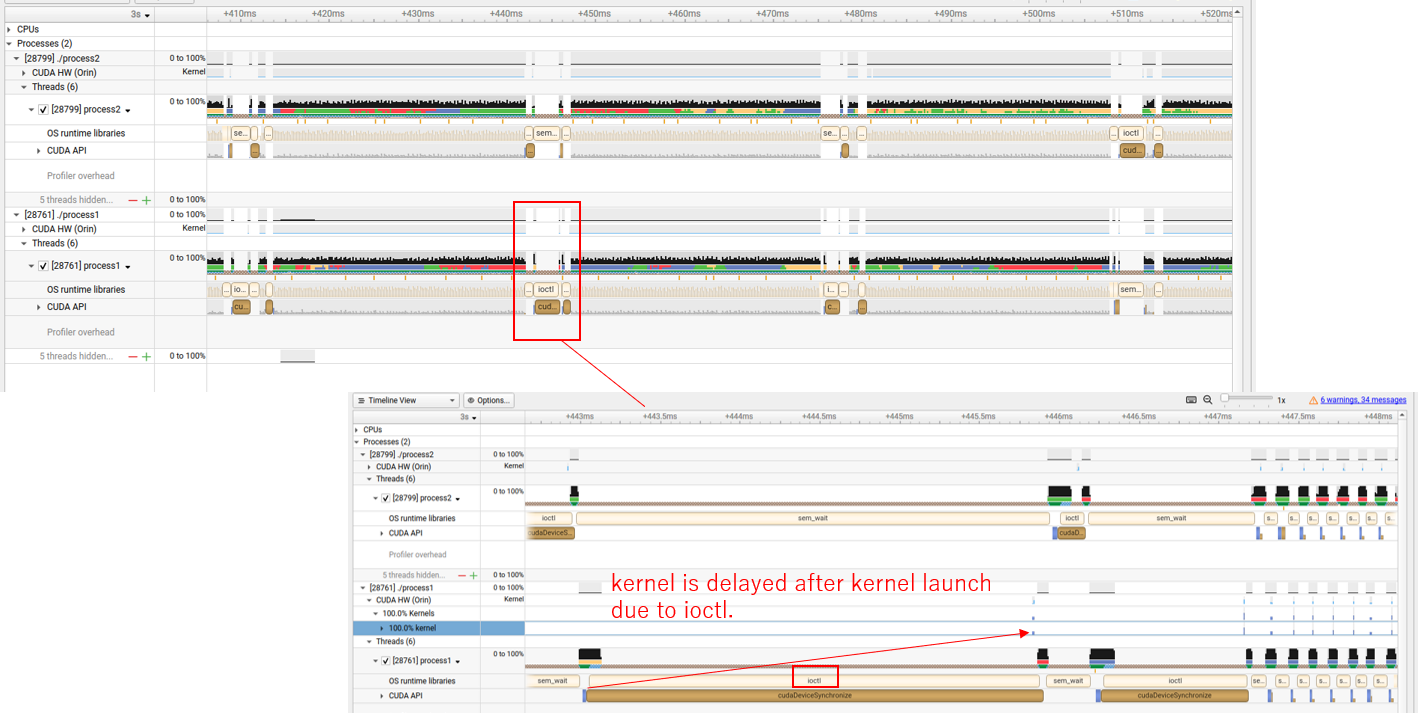
I tried with simple application that does similar to the original application.
From nsys report ioctl appears to block kenel execution after kernel launch periodically.
What is ioctl running for periodically and is there any way to stop it?
One process uses outputs from the other one.
It is to simulate process communication in the original application.
MPS is used to reduce the overhead for context swtich on GPU when 2 processes requests GPU calculation.
Do you also meet the same issue without using MPS?
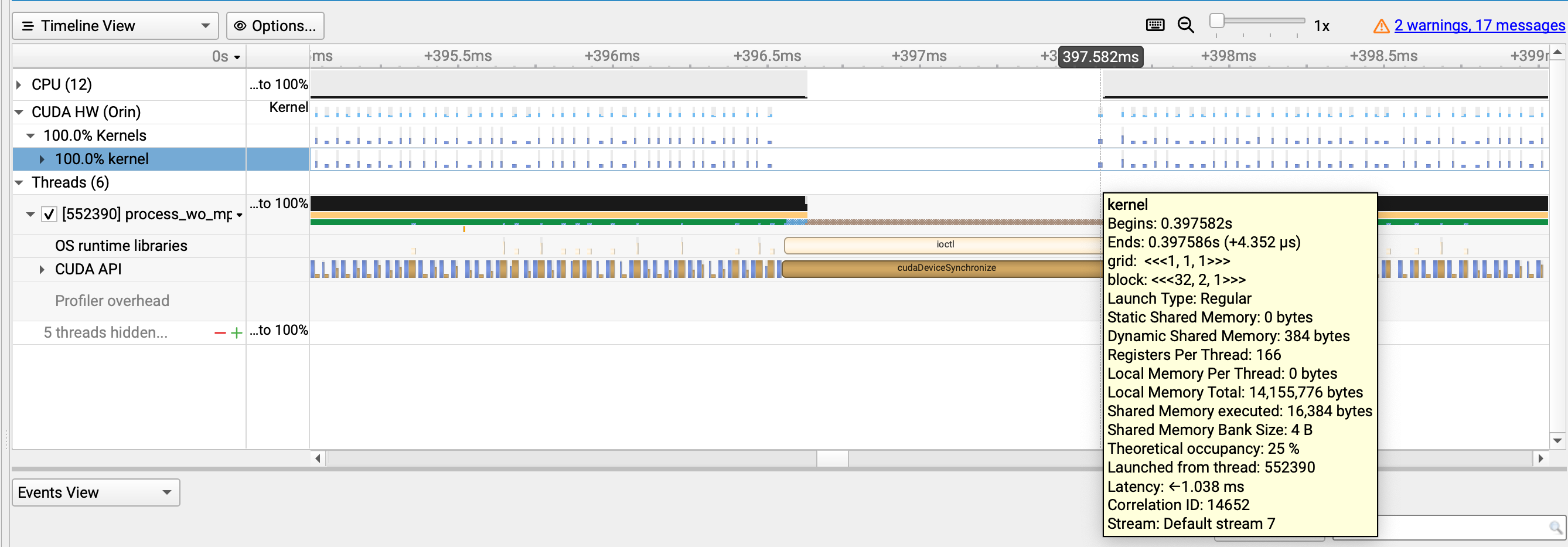
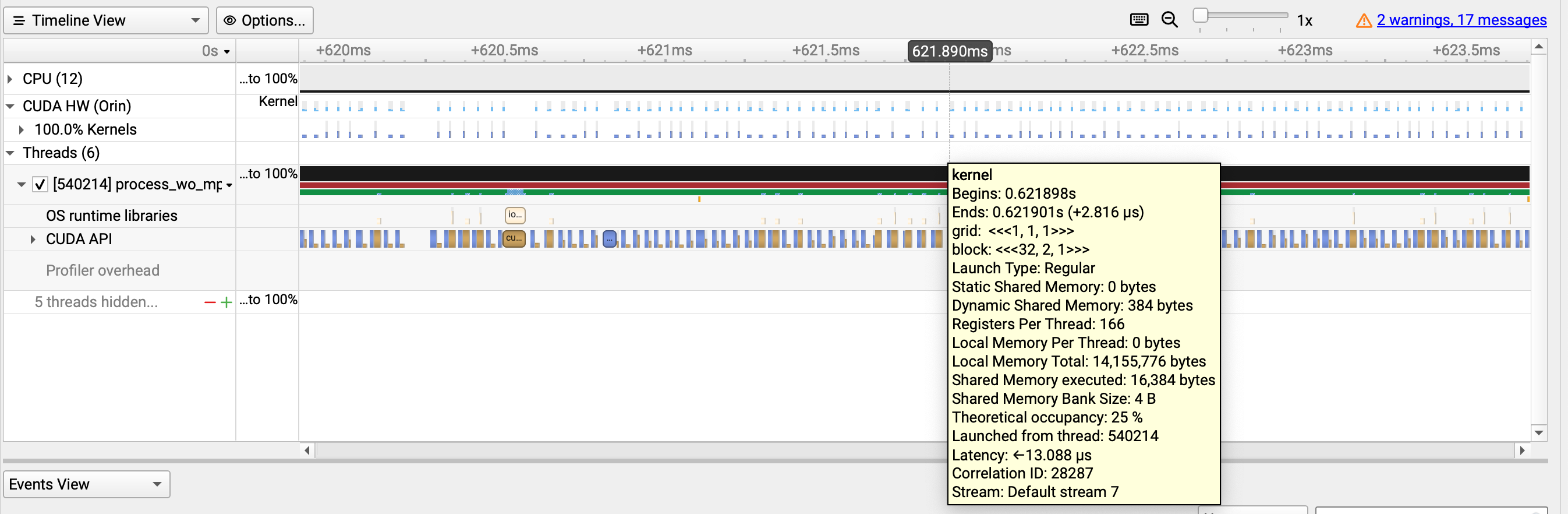
We double-checked the source and the profiling output shared on Apr 9.
Setting CUDA_DEVICE_MAX_CONNECTIONS does help.
The below experiment is done with the non-MPS sample.
Before increasing the max queue number, we do see the launch latency increase from ~12 µs to 1ms.
Is there any way to check the number of total quenes submitted to GPU?
It may be that other applications on my environment are submitting more quene than your environemnt, which lead to ioctl’s blocking although increasing limit with CUDA_DEVICE_MAX_CONNECTIONS=32.
2.
Unfortunately, this is controlled by the low-level GPU scheduler and no info can be retrieved.
Usually, this comes from the smaller kernel like DNNs.
But you can try if the CUDA graph helps for your use case.
The library is designed to minimize launch latency.
Thank you for the link.
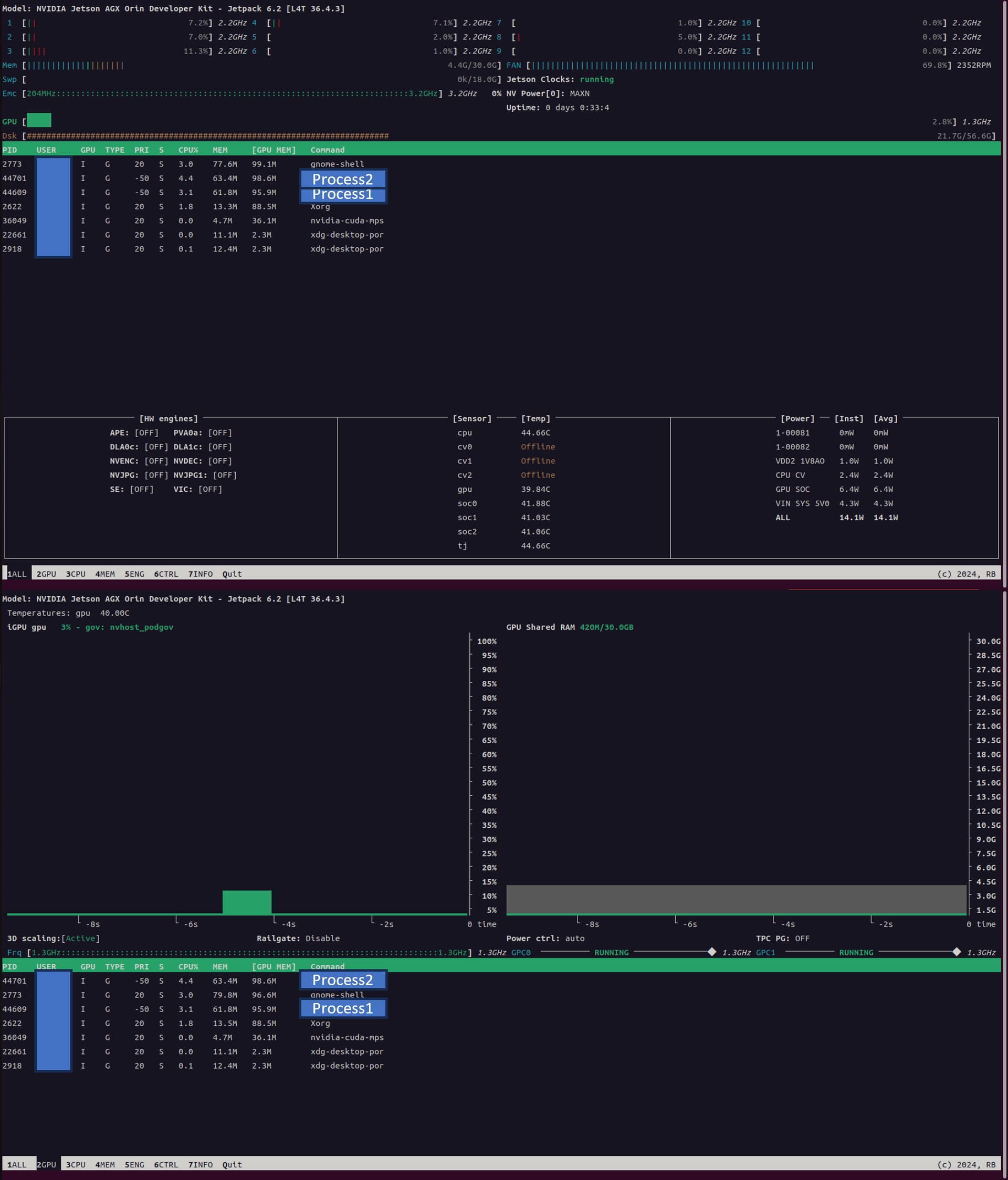
Using tracing tool like strace, I found that Xorg and gnome-shell are calling ioctl() system call, which can be processes interrupting my application.
Setting up jetson with CUI mode disables those applications using GPU for GUI, and worked to reduce latency due to ioctl().