hi,
I train a YOLOv4-tiny 288x288 model with helipad data using darknet and convert the trt model using tensorrrt_demos github and compare it with jetson-inference SSD-Mobilnet v2.
Since jetson-inference is written in C/C++ when loading the model with the drone script (using MAVSDK-python) it works very well at up to 44 fps.
However, the YOLOv4-tiny-288 model drops 1/3 fps whenever there is drone action. So here’s a question.
I know that jetson-inference doesn’t support yolo, but it produces results up to 70fps (Amazing!!!) as shown in the image below, and I couldn’t overlook that!!!
The YOLO model has three labels: helipad, Person, and Vehicle. Looking at the terminal output, there are many more ClassIDs. Why?
I think the difference is in the output part (OUTPUTS : Dimension is different).
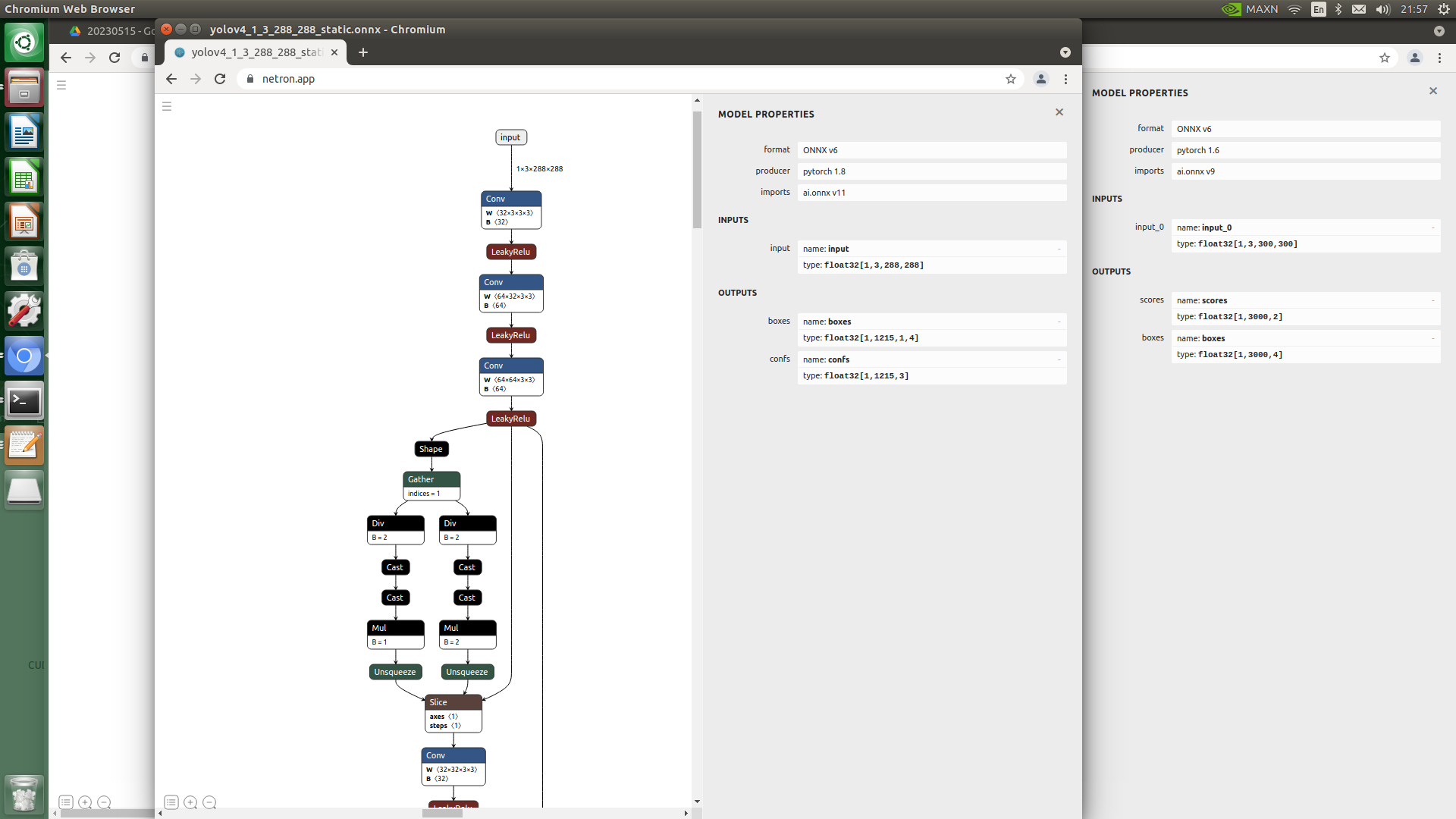
Comparing SSD-Mobilenet v2 and YOLOv4-tiny-288.onnx using a site called Netron, the output is different.
Hi @3629701, yes I believe you are correct that YOLO having different output tensor format is leading jetson-inference to think that there are more classes in the model than there actually are. For ONNX models, the pre/post-processing in jetson-inference detectNet object is setup for SSD models from train_ssd.py. This is where it gets the number of classes from the dimensions of the output tensor:
I confirmed that one big difference is the boxes type of OUTPUTS.
The old boxes are [1,3000,4] , and the current model is [1,1215,1,4] .
The first value of 1 is batch_size, the second value of 3000 is the maximum number of bounding boxes, and the last value is boxes (left, top, right, bottom).
Is my understanding correct?
So can you tell me exactly where I need to modify in detectNet.cpp here?
@3629701 I don’t think it’s realistic to attempt to alter the network topology of YOLO model to match SSD-Mobilenet output and expect the model to still produce valid results or be as accurate. And even if the output tensor dimensions match, they might still carry different data.
Instead, you would need to re-implement the YOLOv4 post-processing code in detectNet.cpp. Alternatively, it may just be easier to run your YOLOv4 model in a project that uses TensorRT Python API directly like this tutorial: https://jkjung-avt.github.io/tensorrt-yolov4/