I’m running a python project on jetson nano 4 gb developer kit, covering two models I made with yolov5. I’m using pytorch. but I am getting low fps when detecting objects using my models. How can I increase the fps rate?
Hi,
Yolo is a heavy model and it may not be able to meet target performance on Jetson Nano. We would suggest run tiny model such as Yolov3 tiny or Yolov4 tiny.
And for running deep learning inference, we suggest try DeepStream SDK. You can install the package through SDKManager and the package is put in
/opt/nvidia/deepstream/deepstream-6.0
Document: https://docs.nvidia.com/metropolis/
I trained my own models using the yolov5 small model.when I switch to a smaller model will I have to train the whole model from scratch?I followed the steps of this link https://developer.nvidia.com/embedded/learn/get-started-jetson-nano-devkit#prepare on jetson nano setup.
Hi,
DeepStream SDK uses Tensor RT. If your model is based on Tensor RT, it can be applied to DeepStream SDK directly. Or you would need to convert the model.
hello,I first converted my model that I created with pytorch to onnx and then to a .pb file. How do I convert pb file to tensorrt and how do I use this tensorrt file in jetson nano?
Hi,
An ONNX format is enough.
You can convert it to TensorRT engine with the following command:
$ /usr/src/tensorrt/bin/trtexec --onnx=[your/model] --saveEngine=model.trt
More, if half-precision is acceptable, you can also convert it with fp16 mode for better performance.
$ /usr/src/tensorrt/bin/trtexec --onnx=[your/model] --saveEngine=model.trt --fp16
Thanks.
I am installing my jetson nano using sd card image. What is the best way to use Tensorrt? I want my model to use deepstream sdk. Can you help me?
Hi,
Please try deepstream-app wit default config file:
/opt/nvidia/deepstream/deepstream-6.0/samples/configs/deepstream-app$ deepstream-app -c source8_1080p_dec_infer-resnet_tracker_tiled_display_fp16_nano.txt
And then refer to document to replace the default model(ResNet10) with yours.
Apart from the slowness of the model, the project starts very slowly when starting. The system is very slow in general. Do you have any suggestions for this?
Hi,
Is it possible your power supply does not supply sufficient current? Somehow you describe the condition we have never seen. Please check Jetson Nano FAQ and see if you can get another power supply for a try.
Should we use the recommended 5v 2.5 amp power supply, or should we use a larger amp supply?
Hi,
5V 2.5A should be fine fo rgeneral use-cases. But Yolo is a heavy model and you may consider 5V 4A.
For the first run please run with sudo so that the generated cache files can be saved:
/opt/nvidia/deepstream/deepstream-6.0/samples/configs/deepstream-app$ sudo deepstream-app -c source8_1080p_dec_infer-resnet_tracker_tiled_display_fp16_nano.txt
The slowness at startup is due to generating cache. Once the cache exists, the step at startup is skipped.
1 Like
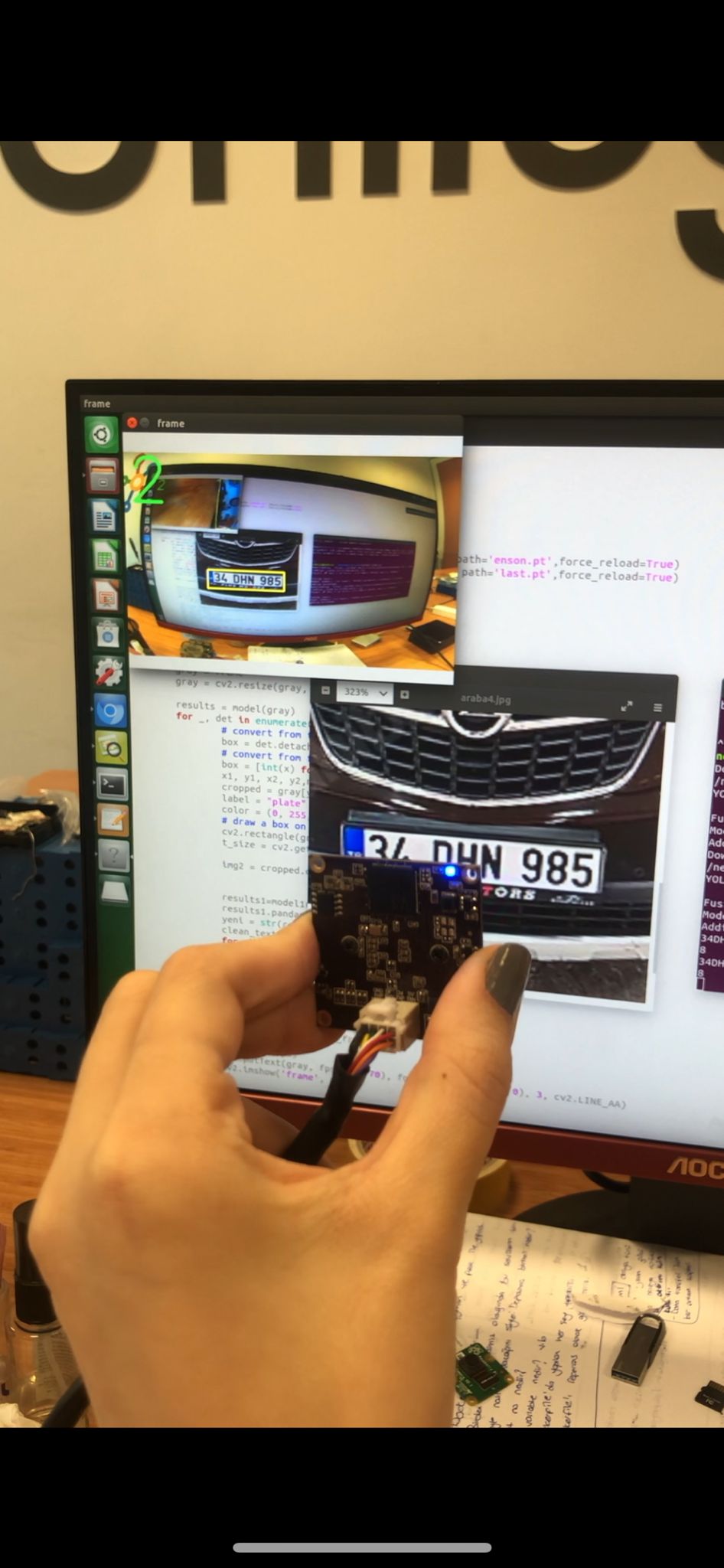
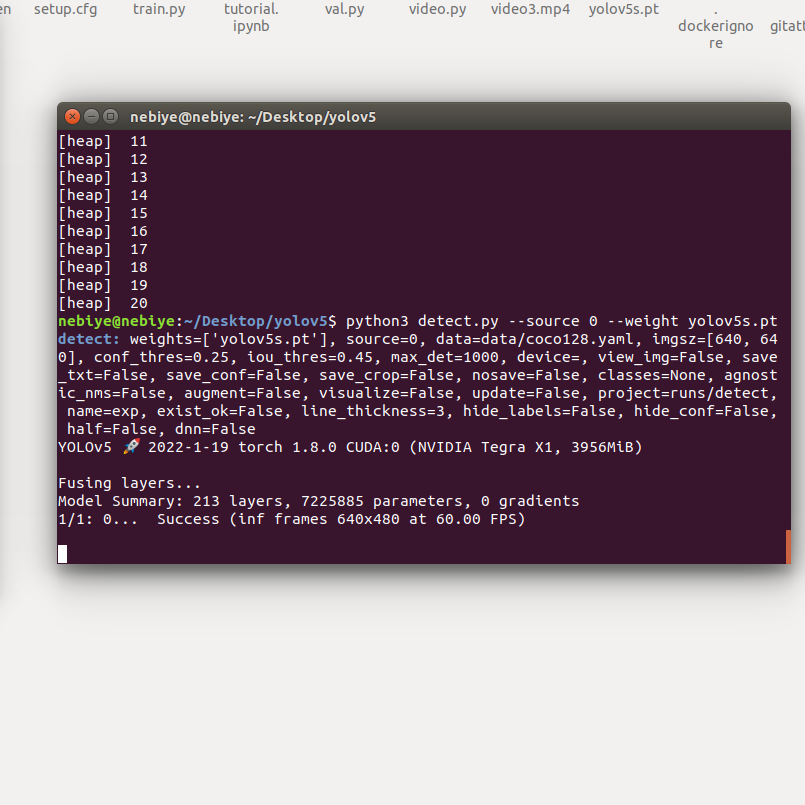
Is the slowness that occurs while running the file due to the lack of cache? The fusing layer, adding autoshape sections are very slow as follows. I made my total space 4 gb and my swap memory 8 gb. Is the slowness in the system due to lack of space or power supply? Can you inform me about this?
Hi,
If you mean low fps, it is due to complexity of the model. Yolo models are heavy and on Jetson Nano, we suggest use tiny models, such as Yolov3 tiny or Yolov4 tiny. If there is Yolov5 tiny, please use the model.
hello, when I try to convert my .onnx model to .trt model with your command, I encounter this error.

!pip install -U nvidia-tensorrt --index-url https://pypi.ngc.nvidia.com # install
!python export.py --weights yolov5s.pt --include engine --imgsz 640 640 --device 0 # export
!python detect.py --weights yolov5s.engine --imgsz 640 640 --device 0 # inference
When I try these steps, I have an .onnx and .engine file, but when I want to detect, I get this error.

Hi,
The error indicates that the trtexec binary cannot open the small.onnx file.
Would you mind double-checking if the file exists or not first?
Thanks.
I converted my yolov5 model to .engine. My model works very well when I detect. but I don’t know how to use my .engine models.Attached is the python file I want to run.
main.py (1.7 KB)
Hi,
You can find a TensorRT sample with engine file below:
https://elinux.org/Jetson/L4T/TRT_Customized_Example#OpenCV_with_PLAN_model
Thanks.
This topic was automatically closed 14 days after the last reply. New replies are no longer allowed.