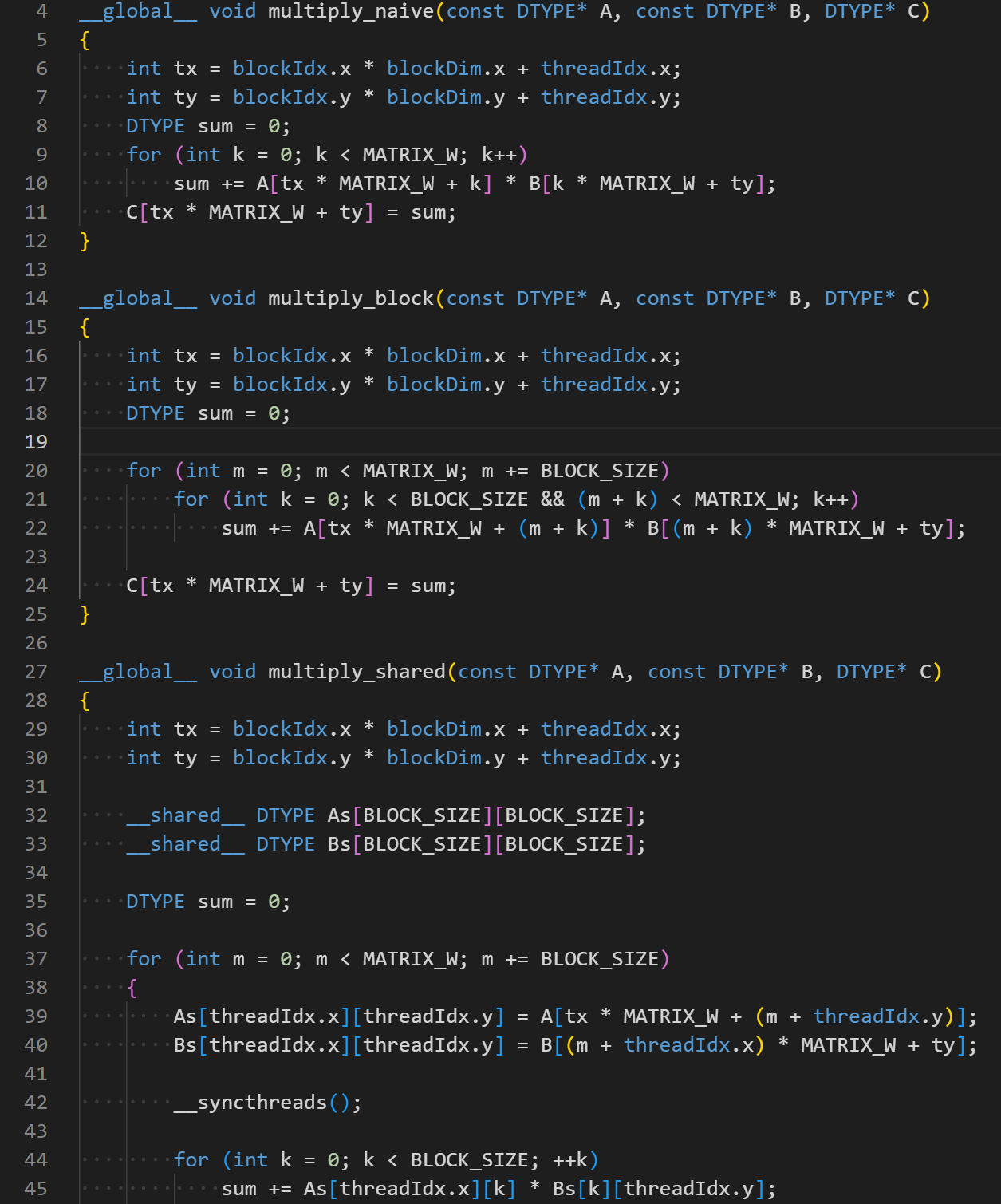
That’s what I did. I modified the code in 2 ways:
- Made the random seed fixed, so that the generate function will produce the same input matrix data.
- completed the
double calculation path (basically add a cublasDgemm call) selectable at compile-time.
When I do that I get results like this:
FLOAT CALCULATION (CPU, GPU/CUBLAS)
(0, 0) 267569632.000000, 267569632.000000
(0, 1) 266916400.000000, 266916512.000000
(0, 2) 268765760.000000, 268765632.000000
(0, 3) 264223248.000000, 264223264.000000
(0, 4) 255403552.000000, 255403584.000000
(1, 0) 273801568.000000, 273801600.000000
(1, 1) 278523488.000000, 278523392.000000
(1, 2) 276506720.000000, 276506752.000000
(1, 3) 274823584.000000, 274823552.000000
(1, 4) 265850304.000000, 265850160.000000
(2, 0) 259909680.000000, 259909792.000000
(2, 1) 264786000.000000, 264785952.000000
(2, 2) 265651488.000000, 265651424.000000
(2, 3) 260584064.000000, 260584144.000000
(2, 4) 253351904.000000, 253351792.000000
(3, 0) 261354752.000000, 261354592.000000
(3, 1) 265288320.000000, 265288576.000000
(3, 2) 260826784.000000, 260826848.000000
(3, 3) 267221984.000000, 267221888.000000
(3, 4) 255389024.000000, 255388832.000000
(4, 0) 261693456.000000, 261693344.000000
(4, 1) 274166112.000000, 274166016.000000
(4, 2) 266335712.000000, 266335776.000000
(4, 3) 267844144.000000, 267844160.000000
(4, 4) 257772992.000000, 257773072.000000
DOUBLE CALCULATION (CPU, GPU/CUBLAS)
(0, 0) 267569561.000000, 267569561.000000
(0, 1) 266916533.000000, 266916533.000000
(0, 2) 268765654.000000, 268765654.000000
(0, 3) 264223253.000000, 264223253.000000
(0, 4) 255403590.000000, 255403590.000000
(1, 0) 273801644.000000, 273801644.000000
(1, 1) 278523489.000000, 278523489.000000
(1, 2) 276506714.000000, 276506714.000000
(1, 3) 274823532.000000, 274823532.000000
(1, 4) 265850147.000000, 265850147.000000
(2, 0) 259909803.000000, 259909803.000000
(2, 1) 264785989.000000, 264785989.000000
(2, 2) 265651427.000000, 265651427.000000
(2, 3) 260584163.000000, 260584163.000000
(2, 4) 253351797.000000, 253351797.000000
(3, 0) 261354579.000000, 261354579.000000
(3, 1) 265288529.000000, 265288529.000000
(3, 2) 260826798.000000, 260826798.000000
(3, 3) 267221847.000000, 267221847.000000
(3, 4) 255388903.000000, 255388903.000000
(4, 0) 261693373.000000, 261693373.000000
(4, 1) 274165966.000000, 274165966.000000
(4, 2) 266335782.000000, 266335782.000000
(4, 3) 267844167.000000, 267844167.000000
(4, 4) 257773075.000000, 257773075.000000
First of all I’ll just advance without proof the notion that the double calculation represents the “correct” values. This is generally supported (although not proven) by the observation that the CPU and GPU(CUBLAS) results match exactly. Given that, we can look at specific differences in the float case. I’ll just look at the first 3 lines of output. Comparing the first line of output:
FLOAT: (0, 0) 267569632.000000, 267569632.000000
DOUBLE: (0, 0) 267569561.000000, 267569561.000000
Here we see that even in the float case, the results between CPU and GPU(CUBLAS) match. Therefore although neither one matches the “golden” double result, they are equidistant from it. Neither is more or less “accurate”. In the next line:
FLOAT: (0, 1) 266916400.000000, 266916512.000000
DOUBLE: (0, 1) 266916533.000000, 266916533.000000
we see that the CPU (first) result is farther from the double value than the GPU (second) result. If we wish, we could say that particular float GPU result is “more accurate” than the corresponding CPU result. In the 3rd line:
FLOAT: (0, 2) 268765760.000000, 268765632.000000
DOUBLE: (0, 2) 268765654.000000, 268765654.000000
we see the same thing: the CPU result appears to be farther away from the “golden” double calculation.
This doesn’t preclude the possibility that you may find situations in the output where the CUBLAS/GPU result is “farther away” from the “golden” value than the CPU result. I didn’t spot any but didn’t look hard. However, I don’t see any data that would support a general conclusion that CUBLAS is somehow “less accurate” than something else.
As an off-topic aside, I witnessed something I had never seen before in your code; I would not have guessed a-priori that this would have worked, but it seems to.
The gpu_check routine (in gpu_main.cu) accepts a function pointer. You are variously passing pointers to “ordinary” functions as well as those decorated with __global__. Within the gpu_check routine, you are configuring this function pointer call as follows:
int gpu_check(const char* method, void (*kernal)(const DTYPE*, const DTYPE*, DTYPE*),
int loop = 1)
{
...
kernal<<<grid, block>>>(d_a, d_b, d_tmp);
in particular, you call it with:
printf("average: %d ms\n\n", gpu_check("cublas", multiply_cublas));
where multiply_cublas (in matrix_gpu.cu) is not decorated with __global__. It’s amazing to me that seems to work, giving the desired behavior whether a kernel function pointer is passed, or an ordinary function pointer is passed (in the later case it seems that the kernel launch config is simply ignored).
Interesting/weird.