To begin with, my main question is: when profiling a CUDA application, is there any way to differentiate CUDA core usage versus Tensor core usage?
To try and answer this, I decided to start with the samples from Nvidia’s cuTENSOR
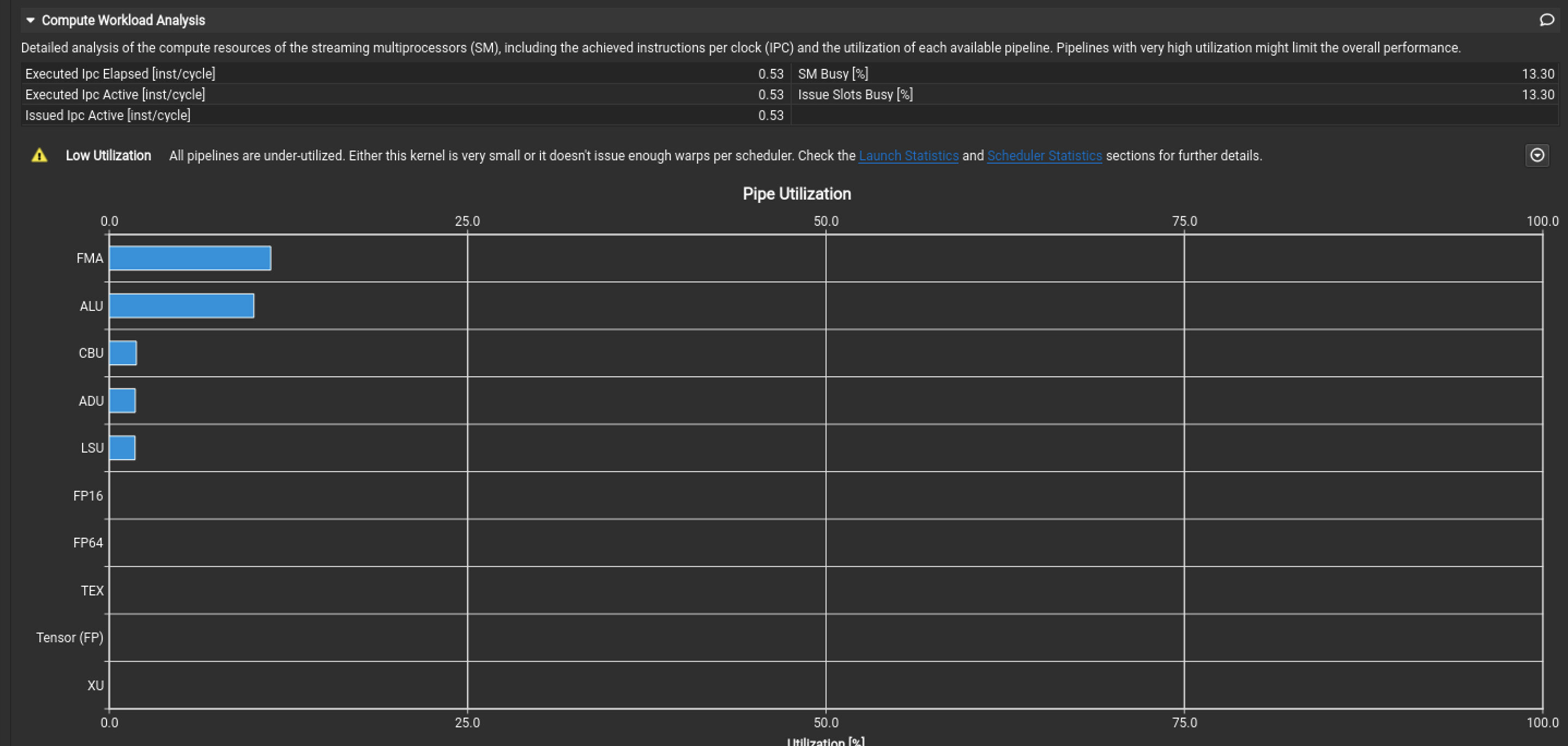
using Nsight Compute’s GUI. Enabling “Compute Workload Analysis” option shows utilization for the various execution pipelines of the SMs. Curious how the Tensor pipeline was not used at all. I understand, Tensor cores are reserved for mixed precision operations, and I haven’t checked the data types used by the profiled application. However, I assumed the cuTENSOR library was an API explicit for leveraging Tensor core processing.
I haven’t studied it carefully, but at first glance it appears to be using float data types, which is FP32. There isn’t any tensorcore support for FP32 on any current CUDA GPUs. Tensorcore support on the latest GPUs includes FP64, FP16, FP8, INT8, and others (INT4, TF32 etc.)
There may be tensorcore usage if the data types are appropriate. Appropriate data types will depend on the GPU you are using, but for example FP32 will not use tensorcores.
There are also metrics you can ask the profiler for, which can indicate tensorcore usage. There is a blog here, as well as various questions on this topic on various forums.
Questions specifically about cuTENSOR should be posted on the libraries forum.
Thank you. This information was extremely helpful. For a followup question, are the Warp Matrix Functions the ONLY way to access Tensor unit operations?