Thank you for pinging me again, I somehow missed Holly’s ping. I’m sorry about that.
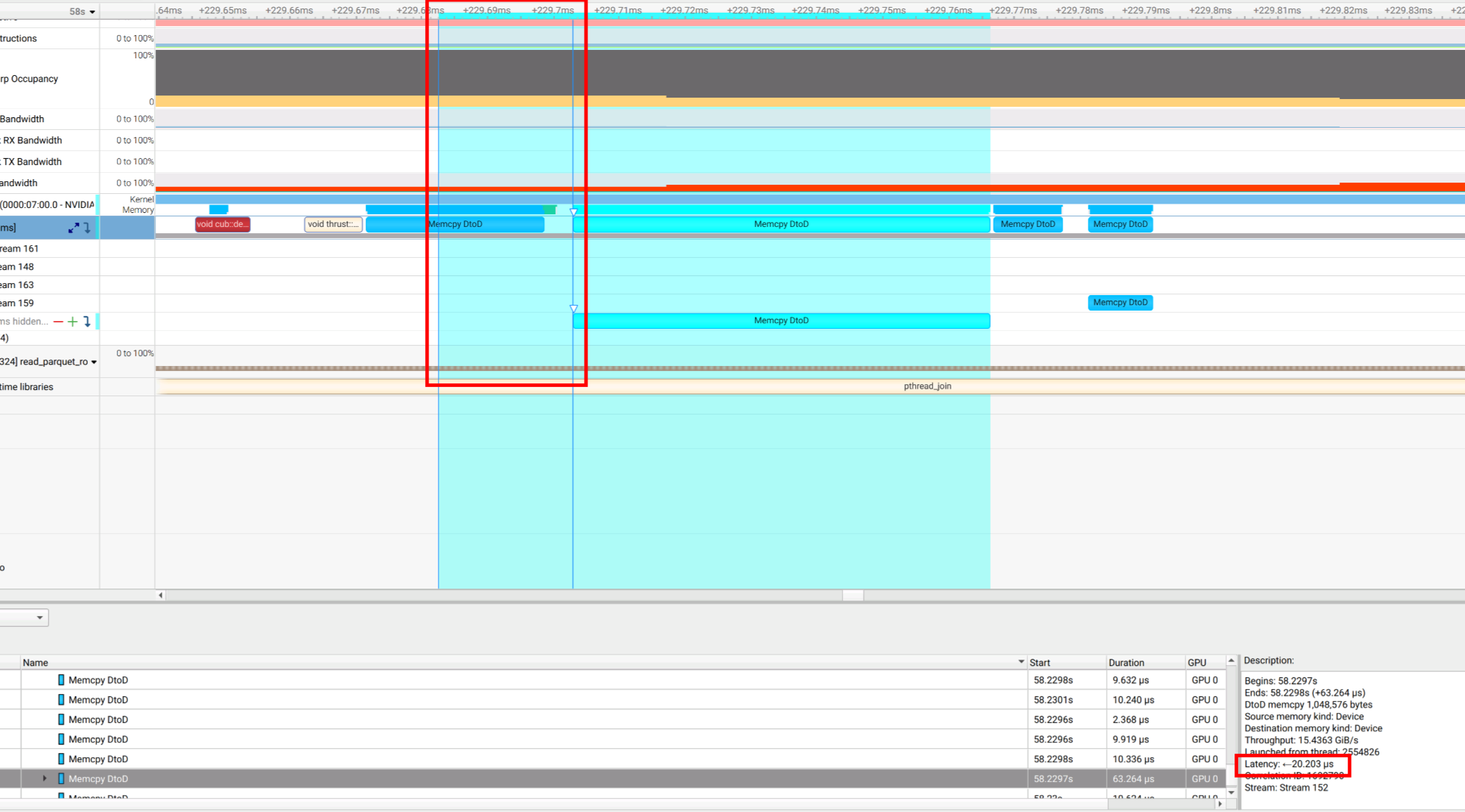
I’m not sure if Queue Duration is the exact same as Latency, but you do have the right idea about what it is trying to represent. Stats scripts have help text available to try to explain the specifics of the data values. In the case of cuda_kern_exec_trace, that output is below. The paragraphs at the end get into specific details, including the fact that optimizing for queue/latency is not always a desirable thing.
$ nsys stats --help-report cuda_kern_exec_trace
cuda_kern_exec_trace[:nvtx-name][:base|:mangled] -- CUDA Kernel Launch & Exec Time Trace
nvtx-name - Optional argument, if given, will prefix the kernel name with
the name of the innermost enclosing NVTX range.
base - Optional argument, if given, will cause summary to be over the
base name of the kernel, rather than the templated name.
mangled - Optional argument, if given, will cause summary to be over the
raw mangled name of the kernel, rather than the templated name.
Note: the ability to display mangled names is a recent addition to the
report file format, and requires that the profile data be captured with
a recent version of Nsys. Re-exporting an existing report file is not
sufficient. If the raw, mangled kernel name data is not available, the
default demangled names will be used.
Output: All time values default to nanoseconds
API Start : Start timestamp of CUDA API launch call
API Dur : Duration of CUDA API launch call
Queue Start : Start timestamp of queue wait time, if it exists
Queue Dur : Duration of queue wait time, if it exists
Kernel Start : Start timestamp of CUDA kernel
Kernel Dur : Duration of CUDA kernel
Total Dur : Duration from API start to kernel end
PID : Process ID that made kernel launch call
TID : Thread ID that made kernel launch call
DevId : CUDA Device ID that executed kernel (which GPU)
API Function : Name of CUDA API call used to launch kernel
GridXYZ : Grid dimensions for kernel launch call
BlockXYZ : Block dimensions for kernel launch call
Kernel Name : Name of CUDA Kernel
This report provides a trace of the launch and execution time of each CUDA
kernel. The launch and execution is broken down into three phases: "API
time," the execution time of the CUDA API call on the CPU used to launch the
kernel; "Queue time," the time between the launch call and the kernel
execution; and "Kernel time," the kernel execution time on the GPU. The
"total time" is not a just sum of the other times, as the phases sometimes
overlap. Rather, the total time runs from the start of the API call to end
of the API call or the end of the kernel execution, whichever is later.
The reported queue time is measured from the end of the API call to the
start of the kernel execution. The actual queue time is slightly longer, as
the kernel is enqueue somewhere in the middle of the API call, and not in
the final nanosecond of function execution. Due to this delay, it is
possible for kernel execution to start before the CUDA launch call returns.
In these cases, no queue times will be reported.
Be aware that having a queue time is not inherently bad. Queue times
indicate that the GPU was busy running other tasks when the new kernel was
scheduled for launch. If every kernel launch is immediate, without any queue
time, that _may_ indicate an idle GPU with poor utilization. In terms of
performance optimization, it should not necessarily be a goal to eliminate
queue time.
You might also be interested in the cuda_kern_exec_sum script, which groups kernels by name, and provides min/max/med/avg/stdev for each of the times, for each kernel.
Both stats reports can also be accessed in the GUI by selecting “Stats System View” in the lower pane. You can then sort the table by any column, including Queue Duration.
If you want to change the order of the CLI output, that does require tinkering with the SQL, but that level of change should be pretty simple. See <nsys-install-dir>/reports for the source files.
Regardless of which report you want to use, if your goal is to create a histogram, I assume you’ll be pulling the data into a spreadsheet or other analytics environment. If this is a task you expect to do over and over, you might look at the recipe system, which allows you to quickly write Python code to extract the data you need and generate a Jupyter notebook to do your analytics and renderings. If you want something simpler, like just pulling the data into Excel or another spreadsheet, be aware that nsys stats can output a number of different formats, including CSV files. Just add --format=csv --output=. to you nsys stats command. That will output in CSV format, using the default output, which for CSV is a file named <report_name>_<stats_report_name>.csv Once that file is loaded into an analysis environment, you can sort or manipulate the data however you see fit.
Let me know if you have any additional questions, and again, I’m sorry I missed this on the first round.