Hi all, I am trying to optimize a CUDA kernel by nsight compute, in the profile result, the report shows it is memory bound, low eligible warps and stall long scoreborad:
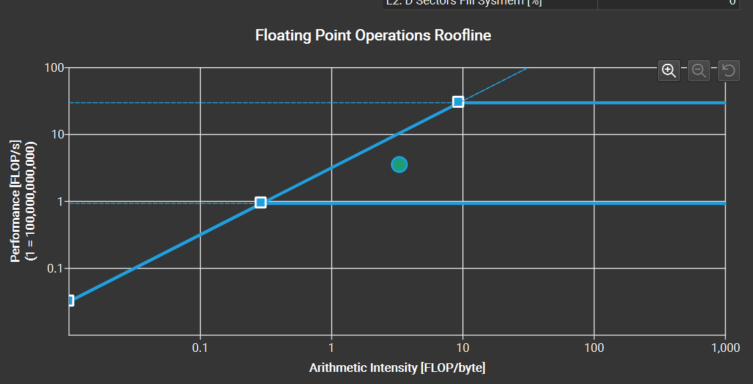
Roofline model:
low eligible warps:
stall long scoreboard
so I check the source code, I find the main contribution code of warp stall is like


loop on j:
{
int cid = col_ind[j];
result = scalar * weight[cid * hf + hfid];
}
and the warp stall happens on the access to the weight in global memory, the weight[cid * hf + hfid] accessed only once.
I wonder how can I reduce warp stall, is there anything like prefetch in global memory?
Hope for any advise!