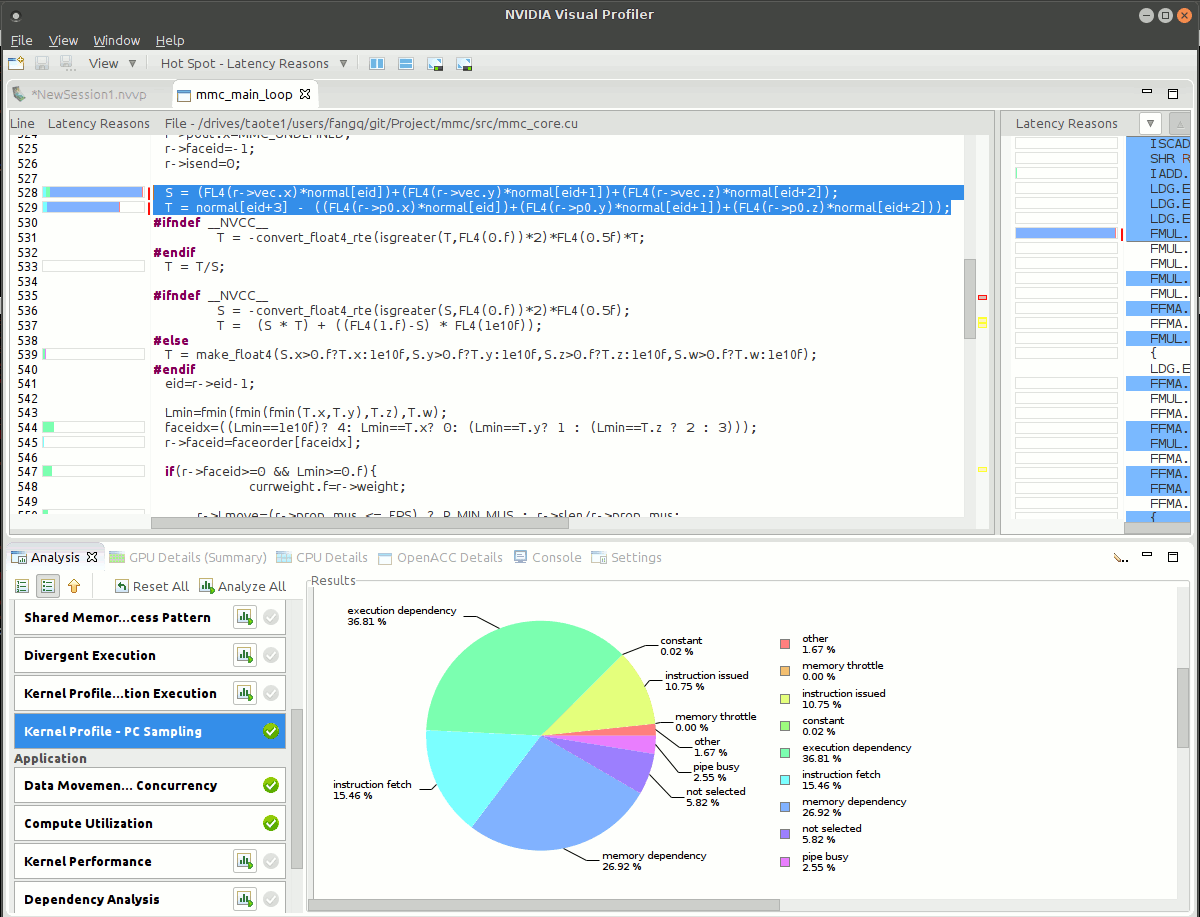
I recently converted an OpenCL kernel to CUDA, and ran nvvp, and found out the below two lines of code placed a heavy toll to the speed of my code. Here is a
#define FL4(f) make_float4(f,f,f,f)
float4 S = FL4(r->vec.x)*normal[eid]+FL4(r->vec.y)*normal[eid+1]+FL4(r->vec.z)*normal[eid+2];
float4 T = normal[eid+3] - (FL4(r->p0.x)*normal[eid]+FL4(r->p0.y)*normal[eid+1]+FL4(r->p0.z)*normal[eid+2]);
where each normal[i] is a float4 (read-only) in the global memory, and as you can see, I need to read 3x normals to compute S and 4x normals (3 of them overlap with the prior line) to compute T. So, a total of 64 bytes are needed for these two lines, making them responsible for nearly 90% of the memory latency of my code.
I previously thought that each global memory read in CUDA comes with a 128-byte cache line - so, reading 1x float vs 4x float4 cost the same. However, the memory latency I observed from these two lines are dramatically higher than what I expect for reading a single float.
Below is the output from nvvp. I would like to hear what you think about on strategies to cut the memory reading cost of these two lines. One thing I want to mention that this code implements the Monte Carlo algorithm. there is very little coalescence between threads due to the random nature of the execution.