Please provide complete information as applicable to your setup.
• Hardware Platform (Jetson / GPU) GPU • DeepStream Version 6.1 • TensorRT Version 8.2 • NVIDIA GPU Driver Version (valid for GPU only) 515 • Issue Type( questions, new requirements, bugs) question
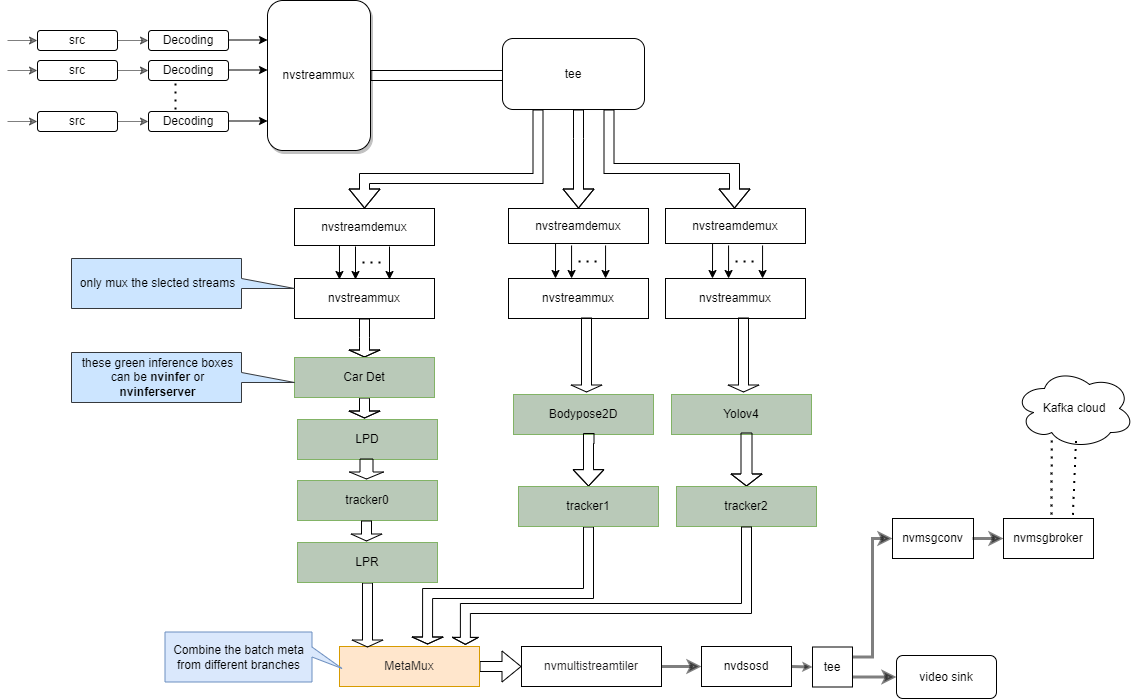
I have read the Parallel Inference example in DeepStream with the same nvstreammux for all models. However, in my case, I use 2 models, each of which requires different input_shape, so I think it is required to use two nvstreammux so that each model can get the right input_shape. How do you think or do you have any recommendation?
gst-nvinfer or gst-nvinferserver will handle the different input shape of the different models. It has nothing to do with nvdsmetamux. You don’t need two nvdsmetamuxs.
Thank you for your reply. Even though DeepStream supports python bindings, I think it is still not clear how to build up the pipeline with streamux → tee → multiple nvstreamdemux → nvstreamux → … → metamux with python binding.
There is no update from you for a period, assuming this is not an issue anymore.
Hence we are closing this topic. If need further support, please open a new one.
Thanks