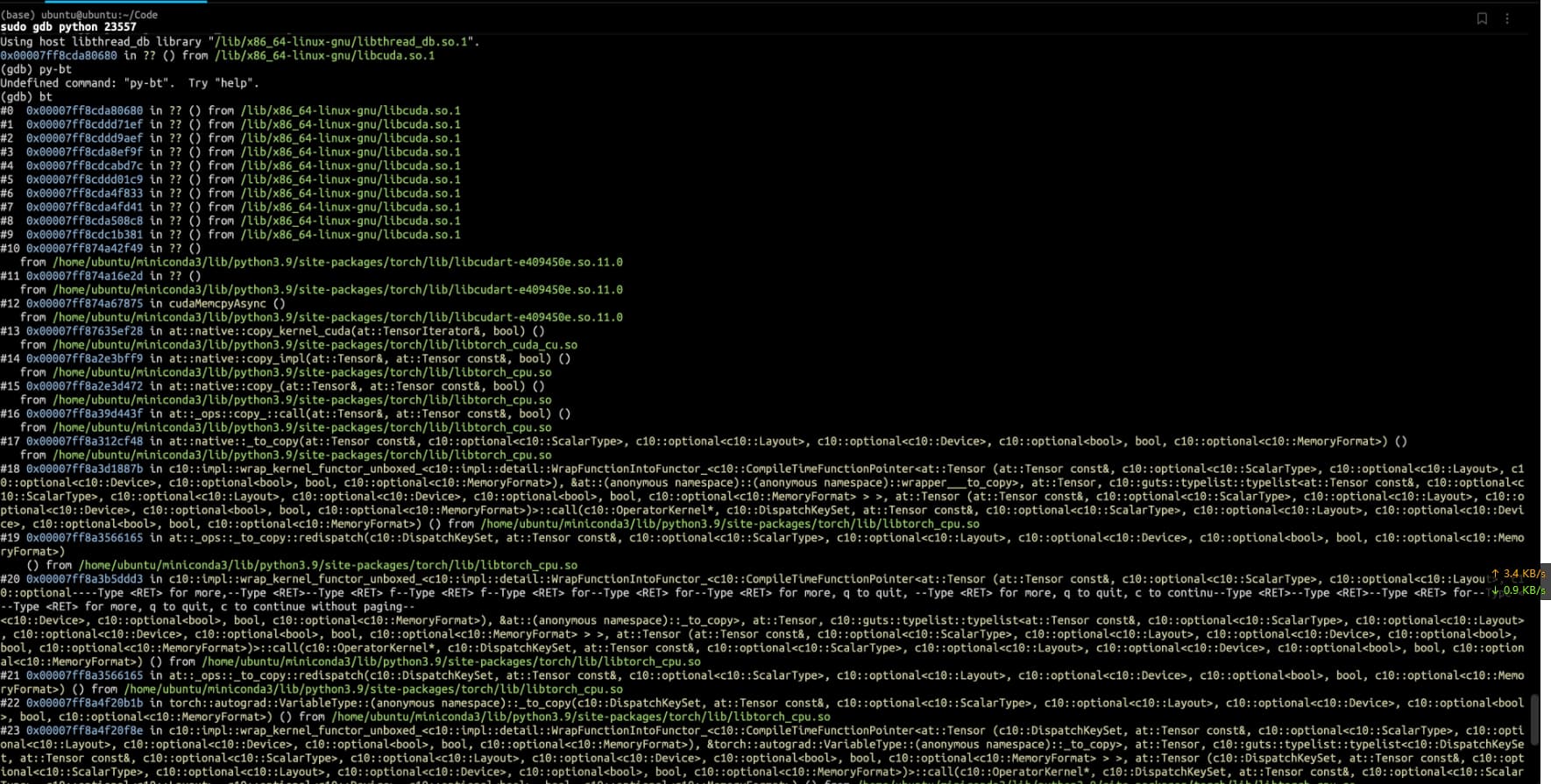
I use a CPU of AMD 5975WX, and four 4090 graphics cards. cuda version is cuda12, pytoch version is 2.0
I noticed that the last call stack is on cuda
See attachment for bug report,My code is also in the attachmentex002_DataParallel.py (6.4 KB)
nvidia-bug-report.log.gz (1.2 MB)
njuffa
December 23, 2022, 7:26am
2
(1) Post text as text, not as images.
Out of interest: What kind of power supply is used in this system? 3200 Watts?
cudalog.rtf (14.7 KB)
opened 03:35PM - 11 Feb 21 UTC
oncall: distributed
module: multi-gpu
module: cuda
triaged
module: deadlock
module: data parallel
module: ddp
## 🐛 Bug
Training CNN (include torchvision resnet18 and timm efficientnet) wi… th a single machine and multi-gpu using dataparallel cause deadlock in machines with AMD cpu, while the same code works well in the machines with Intel cpu.
The code run until forward pass, i.e., `output = model(images)` , inside the for loop in the training. It remains in the `model(images)` forever with gpu utilization go to 0% (memory is occupied, not 0), three cpu cores go to 100%, and other cpu cores go to 0%. The processes PID and GPU mempry usage remains after stopping with `ctrl+c` and `ctrll+z`. The `kill` , `pkill` , and `fuser -k /dev/nvidia*` commands cause zombie processes, also known as defunct and z state. The zombie processes have the parent pid of 1, so it cannot be killed. The only solution is to reboot the system.
The code works well in 3 machines with Intel cpu and has this issue in 4 machines with AMD cpu.
We tested on GTX 1080, Titan V, Titan RTX, Quadro RTX 8000, and RTX 3090. So, it is independent of gpu model.
**Note**: There is similar issue with Distributed Data Parallel (DDP).
## To Reproduce
Steps to reproduce the behavior:
1. use a machine with AMD cpu and multiple NVIDIA gpu
2. Linux, Python3.8, cuda 11.0, pytorch 1.7.1, torchvision 0.8.2
3. write a code to train a resnet18 model in torchvisaion
4. please test both Data Parallel (DP) and Distributed Data Parallel (DP)
## Expected behavior
1. code go to deadlock at forward pass of in the first epoch and the first iteration of training when using AMD cpu.
2. same code work well when using intel cpu
## Environment
#### Intel cpu environment (system 1)
Intel(R) Xeon(R) CPU E5-2699C v4 @ 2.20GHz
```
PyTorch version: 1.7.1+cu110
Is debug build: False
CUDA used to build PyTorch: 11.0
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: version 3.10.2
Python version: 3.8 (64-bit runtime)
Is CUDA available: True
CUDA runtime version: 9.1.85
GPU models and configuration:
GPU 0: GeForce RTX 3090
GPU 1: GeForce RTX 3090
GPU 2: GeForce RTX 3090
GPU 3: GeForce RTX 3090
Nvidia driver version: 455.45.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.1.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip] Could not collect
[conda] Could not collect
```
#### Intel cpu environment (system 2)
Intel(R) Xeon(R) CPU E5-2699A v4 @ 2.40GHz
```
PyTorch version: 1.7.1+cu110
Is debug build: False
CUDA used to build PyTorch: 11.0
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: Could not collect
Python version: 3.8 (64-bit runtime)
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: TITAN RTX
GPU 1: TITAN RTX
GPU 2: TITAN RTX
GPU 3: Quadro RTX 8000
Nvidia driver version: 450.80.02
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.1.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip] Could not collect
[conda] Could not collect
```
#### Intel cpu environment (system 3)
Intel(R) Xeon(R) CPU E5-2699A v4 @ 2.40GHz
```
PyTorch version: 1.7.1+cu110
Is debug build: False
CUDA used to build PyTorch: 11.0
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: Could not collect
Python version: 3.8 (64-bit runtime)
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: Tesla K80
GPU 1: Tesla K80
GPU 2: Tesla K80
GPU 3: Tesla K80
GPU 4: Tesla K80
GPU 5: Tesla K80
GPU 6: Tesla K80
GPU 7: Tesla K80
GPU 8: Tesla K80
GPU 9: Tesla K80
GPU 10: Tesla K80
GPU 11: Tesla K80
GPU 12: Tesla K80
GPU 13: Tesla K80
GPU 14: Tesla K80
GPU 15: Tesla K80
Nvidia driver version: 450.102.04
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.1.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip] numpy==1.14.3
[conda] Could not collect
```
#### AMD cpu environment (system 4)
AMD Eng Sample: 100-000000053-04_32/20_N
```
PyTorch version: 1.7.1+cu110
Is debug build: False
CUDA used to build PyTorch: 11.0
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: version 3.10.2
Python version: 3.8 (64-bit runtime)
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: GeForce GTX 1080 Ti
GPU 1: GeForce GTX 1080 Ti
GPU 2: GeForce GTX 1080 Ti
GPU 3: GeForce GTX 1080 Ti
GPU 4: GeForce GTX 1080 Ti
Nvidia driver version: 450.102.04
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.1.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip] Could not collect
[conda] Could not collect
```
#### AMD cpu environment (system 5)
AMD Eng Sample: 100-000000053-04_32/20_N
```
PyTorch version: 1.7.1+cu110
Is debug build: False
CUDA used to build PyTorch: 11.0
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: Could not collect
Python version: 3.8 (64-bit runtime)
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: TITAN V
GPU 1: TITAN V
Nvidia driver version: 455.45.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.1.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip] Could not collect
[conda] Could not collect
```
#### AMD cpu environment (system 6)
AMD Opteron(tm) Processor 6380
```
PyTorch version: 1.7.1+cu110
Is debug build: False
CUDA used to build PyTorch: 11.0
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: version 3.10.2
Python version: 3.8 (64-bit runtime)
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: TITAN V
GPU 1: TITAN V
Nvidia driver version: 450.102.04
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.1.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip] Could not collect
[conda] Could not collect
```
#### AMD cpu environment (system 7)
AMD Opteron(tm) Processor 6380
```
PyTorch version: 1.7.1+cu110
Is debug build: False
CUDA used to build PyTorch: 11.0
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: version 3.10.2
Python version: 3.8 (64-bit runtime)
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: GeForce GTX 1080 Ti
GPU 1: GeForce GTX 1080 Ti
GPU 2: GeForce GTX 1080 Ti
Nvidia driver version: 450.102.04
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.1.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.1.0
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.1.0
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.0
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.0
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.0
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.0
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.0
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip] Could not collect
[conda] Could not collect
```
cc @ngimel @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @agolynski @SciPioneer @H-Huang @mrzzd @cbalioglu
Some information I have learned is that there is no such problem with intel CPUs. The solution given in this Issue is to turn off the IOMMU of the motherboard, but this option is what I need, so I want to know if there are other solutions
I use two 1600W power supplies. A power supply is connected to 2 graphics cards, and the motherboard.
njuffa
December 23, 2022, 8:23am
4
As far as I understand the linked thread, the working hypothesis there is that the issue is due to an incompatibility between NVIDIA’s NCCL and AMD’s IOMMU. That is outside my area of expertise, and frankly, appears to have nothing to do with CUDA.
Off-hand I do not know of a sub-forum for NCCL (in fact I did not know of NCCL’s existence until just now). If there is more corroborating evidence strengthening the hypothesis, that might lead to a classical “it’s the other vendor’s fault” finger-pointing exercise.
Consider filing a bug with NVIDIA.
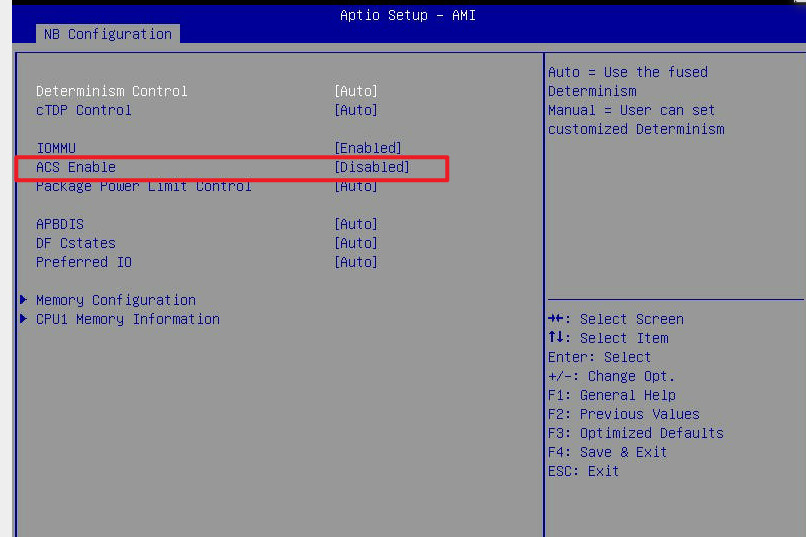
The motherboard I’m using is Supermicro’s M12SWA-TF, I’m sure the BIOS has been updated to the latest from the official website, and the ASC has been turned off. But my situation is still the same, and I am not sure whether the 4090 supports P2P, because I see that the link you shared is running simpleP2P, and I have run simpleP2P
IOMMU_enable_ACS_disable.txt (16.0 KB)
IOMMU_disable_ACS_enable.txt (16.1 KB)
IOMMU_disable_ACS_disable.txt (16.1 KB)
The failures in your attachments indicate a problem with the motherboard. You should address this with Supermicro.
I don’t have this problem with 4 A100s, only 4090s currently have this problem
The platform is still the original platform, I only changed the graphics card
please help me
I have communicated with Supermicro technical staff, they recognized the problem of ACS, but after checking my settings, they confirmed that ASC has been turned off, and they asked me to take 4 A100s for experiment, it is indeed possible to run p2psimple, but when I change Back to 4090, the problem remains
FWIW, I have 2 4090s and I’m having same problems training deep learning models on a system that worked fine with 2 3090s.
Its a bummer. About to get my WRX80 WS next week with 2 4090s and 5975WX. Why is this issue not widespread? Aren’t workstation builders not seeing this issue when assembling/selling AMD WS with multiple 4090s?
Is turning amd_iommu off the solution in some configurations?
Did it work and scale with amd_iommu turned off?
iommu was one of the bios settings I tried and it didn’t help.
@jaybob20 , you might be aware from the other ticket. An issue is being worked on by nVidia.
Hi vasilii.shelkov
Thank you for the additional information. We can reproduce this issue on our systems. This is under investigation.