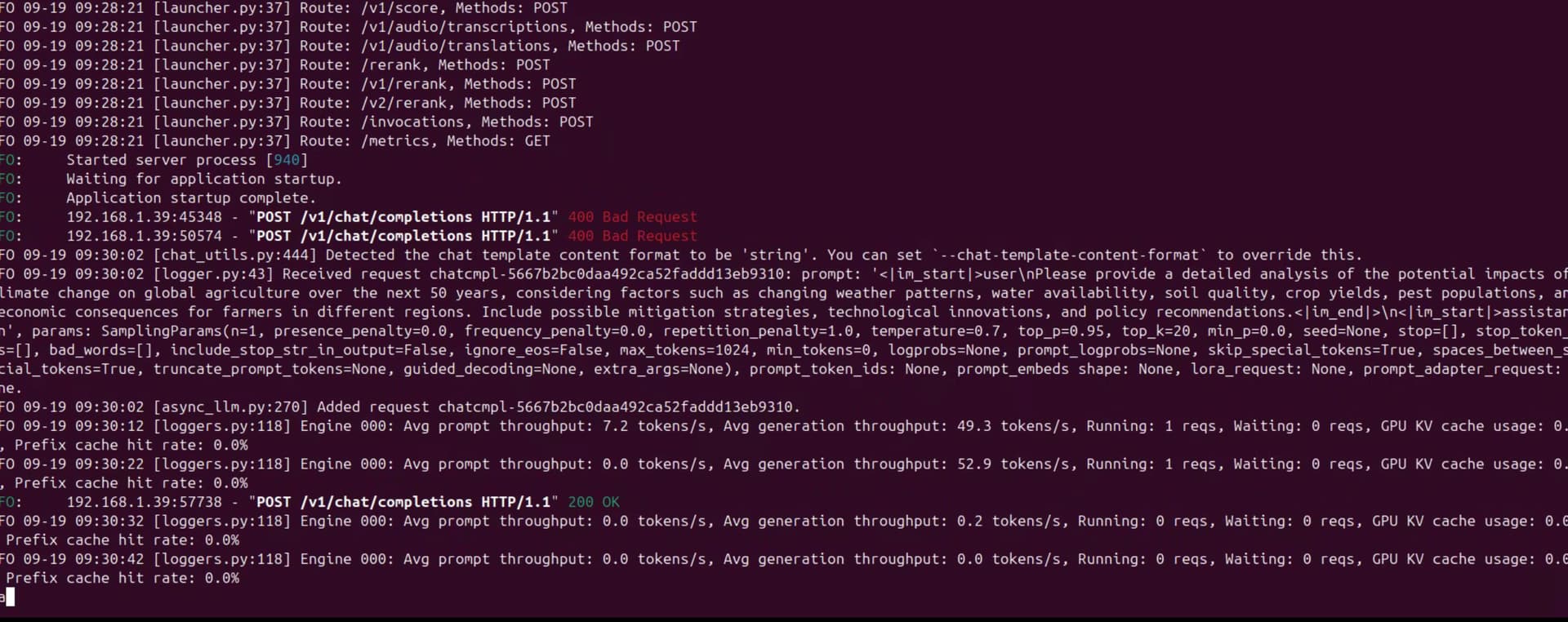
I conducted a performance comparison of the Qwen3-30B-A3B-AWQ model on two NVIDIA Jetson devices.The model is downloaded from Qwen3-30B-A3B-AWQ · 模型库
Jetson Thor Test (192.168.1.168)
-
Model used: Qwen3-30B-A3B-AWQ
-
Container:
nvcr.io/nvidia/tritonserver:25.08-vllm-python-py3 -
vLLM command:
python3 -m vllm.entrypoints.openai.api_server
–model ./Qwen3-30B-A3B-AWQ/
–dtype auto
–tensor-parallel-size 1
–max-model-len 20480
–gpu-memory-utilization 0.8
–served-model-name qwen30b
Jetson Orin AGX Test (192.168.1.39)
-
Model used: same as above
-
vLLM installed via jp6/cu126 index, version 0.8.5(I downloaded this whl file 2 months ago, now is 0.10.2)
-
vLLM command:
python3 -m vllm.entrypoints.openai.api_server
–model /data/qwen3-30B
–dtype auto
–tensor-parallel-size 1
–max-model-len 20480
–gpu-memory-utilization 0.9
–served-model-name Qwen3-30B-A3B-AWQ
Testing via curl
Thor device:
curl -X POST http://192.168.1.168:8000/v1/chat/completions
-H “Content-Type: application/json”
-d ‘{
“model”: “qwen30b”,
“messages”: [
{
“role”: “user”,
“content”: “Please provide a detailed analysis of the potential impacts of climate change on global agriculture over the next 50 years, considering factors such as changing weather patterns, water availability, soil quality, crop yields, pest populations, and economic consequences for farmers in different regions. Include possible mitigation strategies, technological innovations, and policy recommendations.”
}
],
“max_tokens”: 1024,
“temperature”: 0.7,
“top_p”: 0.95
}’

Orin AGX 64GB:
curl -X POST http://192.168.1.39:8000/v1/chat/completions
-H “Content-Type: application/json”
-d ‘{
“model”: “Qwen3-30B-A3B-AWQ”,
“messages”: [
{
“role”: “user”,
“content”: “Please provide a detailed analysis of the potential impacts of climate change on global agriculture over the next 50 years, considering factors such as changing weather patterns, water availability, soil quality, crop yields, pest populations, and economic consequences for farmers in different regions. Include possible mitigation strategies, technological innovations, and policy recommendations.”
}
],
“max_tokens”: 1024,
“temperature”: 0.7,
“top_p”: 0.95
}’

Monitoring vLLM service results:
- Jetson Thor: ~53.0 tokens/s
- Orin AGX 64GB: ~41.5 tokens/s
Question:
The Thor has 2000 TOPS FP4, while the Orin AGX 64GB has 275 TOPS INT8. Why is the performance difference so small? Could there be something wrong in my setup or testing method?