I followed your guide and pull the docker iamges:

I started it with the command of:
sudo docker run --ipc=host --net host --gpus all --runtime=nvidia --privileged
-it -u 0:0 -v ~/my_models:/models --name=thor_vllm thor_vllm_container:25.08-py3-base
docker exec -it thor_vllm /bin/bash
cd script
I’ve downloaded the model from Qwen3-30B-A3B-quantized.w4a16 · 模型库
then I modified the run_vllm_llm_serve.sh as follow:
#!/bin/bash
# Simple script to serve a model with vLLM
# Usage: ./run_vllm_llm_serve.sh <model_name>
if [ -z "$1" ]; then
echo "Usage: $0 <model_name>"
exit 1
fi
MODEL_NAME="$1"
shift
# Run vllm serve with the given model name and any extra options
echo 3 | tee /proc/sys/vm/drop_caches
export VLLM_DISABLED_KERNELS=MacheteLinearKernel
# Set quantization flag based on the model name
if [ "$MODEL_NAME" = "RedHatAI/Meta-Llama-3.1-8B-Instruct-quantized.w4a16" ]; then
QUANTIZATION="gptq"
else
QUANTIZATION="compressed-tensors"
fi
sync && echo 3 | tee /proc/sys/vm/drop_caches && VLLM_ATTENTION_BACKEND=FLASH_ATTN vllm serve /models/Qwen3-30B-A3B-quantized.w4a16 --swap-space 16 --max-seq-len 32768 --max-model-len 32768 --tensor-parallel-size 1 --max-num-seqs 1024 --dtype auto --gpu-memory-utilization 0.80 --served-model-name qwen30b
then I used the command:
./run_vllm_llm_serve.sh
Then I used another device to make a curl request and monitored the Thor device’s vllm log:
However I got the same result?
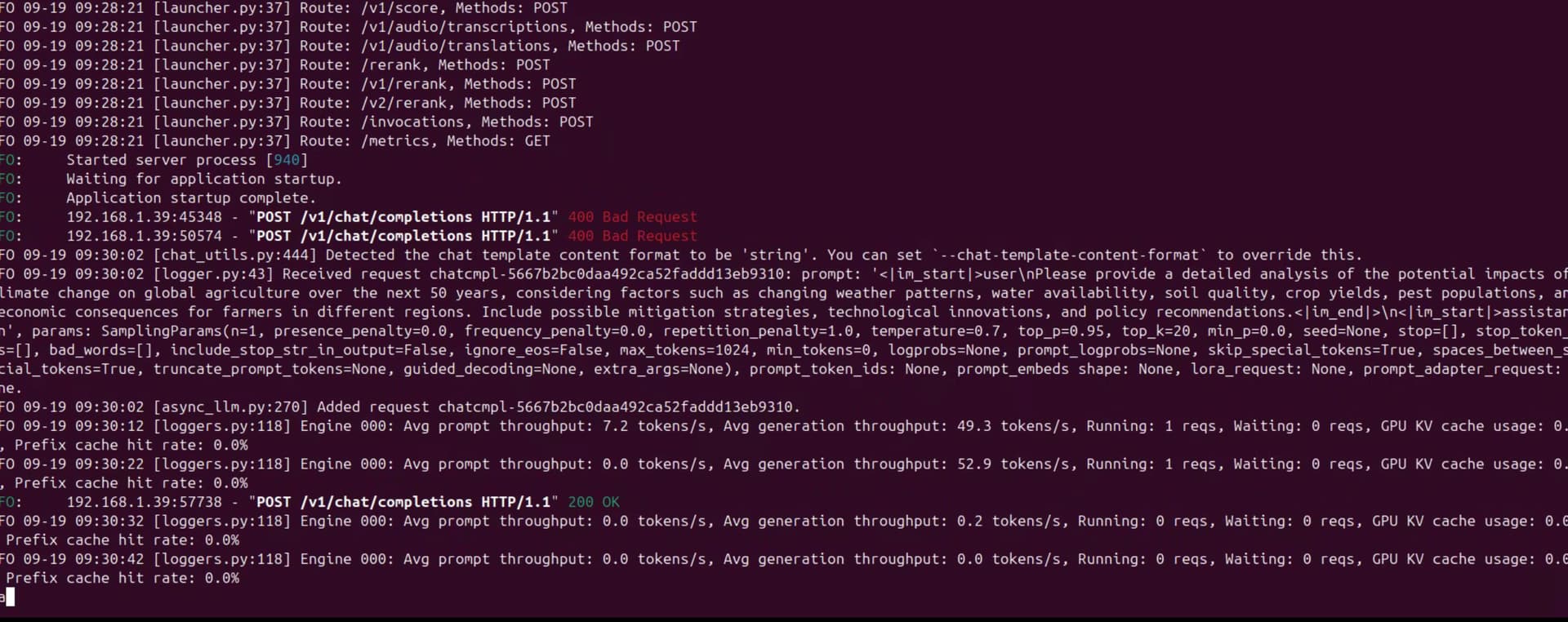
It was still around 53 tokens/s?