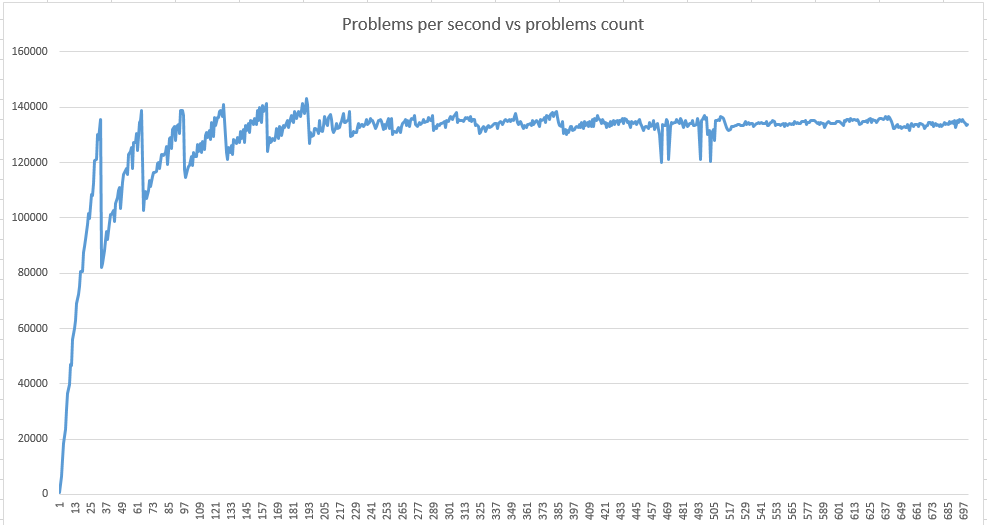
I am writing a code to solve the lamé equation for anisotropic waveguides and have come across the following situation. The performance of the code that calculates the part of the green matrix drops after a certain task size is reached.
I understand why performance is jagged at small sizes - it’s tail effects, but what causes the drop at large sizes? In my understanding, performance should asymptotically tend to peak with growth in size.
CUDA 11.8 Win 10 GTX1080 (PC)
CUDA 11.8 Win 10 GTX840M (Laptop)
part of my code
#define hv _host_ void
hv test_speed_new_v3(int lo = 1, int hi = 1025, int step = 1, int repetitions = 10)
{
//global variables, nothing interesting
timer_data_ timer;
t_device_config device;
t_math_solver_configs solver;
int dim1 = 1;
int dim2 = 1;
float default_override = 4;
int layers = 1;
int mesh_kind = MESH_GAMMA_ALPHA;
cuDoubleComplex g1 = make_cuDoubleComplex(1.000000, 0.0);
cuDoubleComplex g2 = make_cuDoubleComplex(1.000001, 0.0);
cuDoubleComplex a1 = make_cuDoubleComplex(1.0, 0.0);
cuDoubleComplex a2 = make_cuDoubleComplex(10.0, 0.0);
double m__ = 1;
cuDoubleComplex omega = make_cuDoubleComplex(0.628 * m__, 0.0 * m__);
cuDoubleComplex z = make_cuDoubleComplex(0.0, 0.0);
float override_ = default_override;
int smem = 64 * 1024;
int th = 128;
int regs = 128 * 1024;
int preset = NO_PRESET_BLOCKS;
int thuse;
int smemuse;
int reguse;
t_math_solver_configs* solver_on_device;
device_init(device);
init_empty_vals(device);
cuda_streams_init(device);
init_timer(&timer);
cudaMalloc(&solver_on_device, sizeof(t_math_solver_configs));
cuda_check(cudaDeviceSynchronize());
//this part is measuring time for different problems
for (int cur_pc = lo; cur_pc < hi; cur_pc += step)
{
solver.dim1 = dim1;
solver.dim2 = cur_pc ;
//allocating mem
build_spec_pools_Nxlay_v3_expandedME(device, solver, 1);
cudaMemcpy(solver_on_device, &solver, sizeof(t_math_solver_configs), cudaMemcpyHostToDevice);
//initialize physic constants
k1x1_init_com0_1l_caller << <1, 1 >> > (solver_on_device);
thuse = 32;
reguse = 110;
smemuse = 1024;
int blocks = GetBlocksCountf4(device.device_SM, smem, smemuse, th, thuse, regs, reguse, override_, dim1 * dim2, preset);
//generate mesh
knxm_generate_points_v2 << <blocks, 32 >> > (solver_on_device, g1, g2, a1, a2, omega, z, dim1, dim2, mesh_kind);
cudaMemcpy(&solver, solver_on_device, sizeof(t_math_solver_configs), cudaMemcpyDeviceToHost);
start_timer(&timer);
//time consuming part
for (int rep_id = 0; rep_id < repetitions; rep_id++)
{
k1x1_smart_launch_ENEV << <1, 1 >> > (solver_on_device, dim1 * dim2 * layers, device.device_SM);
k1x1_smart_launch_BLOCKS_V2 << <1, 1 >> > (solver_on_device, dim1 * dim2, device.device_SM);
k1x1_smart_launch_SOLVER << <1, 1 >> > (solver_on_device, dim1 * dim2, device.device_SM);
}
double elapsed = stop_timer_avg(&timer, (double)repetitions);
double points_per_sec = ((double)dim2 * 1000000) / elapsed;
printf("count %d elapsed %lf us perf pps %lf \n", dim2, elapsed, points_per_sec);
deallocate_pool(device, solver.multi_pool);
cuda_check(cudaDeviceSynchronize(), "post cycle check", true, __FILE__, __LINE__);
}
kill_timer(&timer);
device_release(device);
}
code for timer
#define hv _host_ void
struct timer_data_
{
double executed_us;
cudaEvent_t start, stop;
};
hv init_timer(timer_data_* timer)
{
cuda_check(cudaEventCreate(&timer->start));
cuda_check(cudaEventCreate(&timer->stop));
}
hv start_timer(timer_data_* timer)
{
cuda_check(cudaEventRecord(timer->start, 0));
cuda_check(cudaEventRecord(timer->stop, 0));
}
__host__ double stop_timer(timer_data_* timer)
{
float time;
cuda_check(cudaEventRecord(timer->stop, 0));
cuda_check(cudaEventSynchronize(timer->stop));
cuda_check(cudaEventElapsedTime(&time, timer->start, timer->stop));
timer->executed_us = (double)time / 1000.0;
return timer->executed_us;
}
__host__ double stop_timer_avg(timer_data_* timer, double avg)
{
float time;
cuda_check(cudaEventRecord(timer->stop, 0));
cuda_check(cudaEventSynchronize(timer->stop));
cuda_check(cudaEventElapsedTime(&time, timer->start, timer->stop));
timer->executed_us = ((double)time * 1000.0) / avg;
return timer->executed_us;
}
__host__ void kill_timer(timer_data_* timer)
{
cuda_check(cudaEventDestroy(timer->start));
cuda_check(cudaEventDestroy(timer->stop));
}
UPD: GPU temperature stays low during computing ~50-55 degrees Celsius