My machine have 4 V100s, which are connected by NVLink. I run a process on each GPU and read other GPU’s memory via IPC. In my understanding, if each GPU read other GPU’s memory simultaneously, this will puts more pressure on NVLink. So if I stagger their kernel, I should have better performance.
But result is is the opposite. I guess peer GPU L2 cache have impact on this. So my question is:
Is my understanding right?
I want to vertify the effects of L2 cache, can I disable L2 cache on V100?
No, that is probably not correct, for the V100 SXM2 case. The V100 SXM2 machines with NVLink have separate links connecting each pair of GPUs (considering the first 4 GPUs). So the data transfer from GPU 0 to GPU 3 flows over a different set of links than for example the data transfer from GPU 0 to GPU 2 (or any other pair you wish to name). So there should not be much contention or interference between paths.
You cannot disable L2 cache on any CUDA GPU at least up through cc7.5 (Turing). Volta devices cannot have their L2 cache disabled. (On cc8.x devices, you can reserve a portion of the L2, but the portion that you reserve cannot be 100%, so the L2 cannot be completely disabled for other accesses).
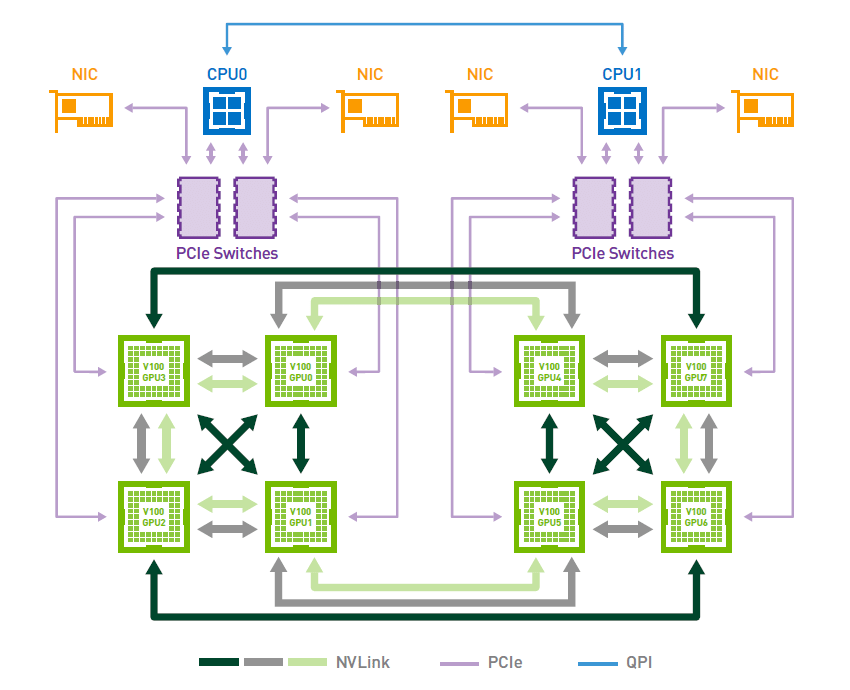
My answer is based on the idea that you are probably working on a machine that is “one half” of this diagram:
On my machine, each pair GPUs are connected by 2 links, and bidirection bandwidth is 100GB.
My guess is based on, by profiling sm peer read, I find GPU not only receives data from peer, but also transmits data to peer due to protocol. So if 2 GPU read peer memory simultaneously, performance will degrade compared to single GPU peer read.
I think that will also happen in 4 GPU, and assume peer memory read is symmetrical.
If each GPU is only reading from the other 3 GPUs, then considering the NVLink case (e.g. GPUs 0 and 1 connected via NVLink), running the activities concurrently should not matter. GPU 0 reads from GPU 1, GPU 1 reads from GPU 0. (This is the only NVLink traffic possible for those 2 GPUs in your setup). NVLink provides separate, dedicated bandwidth in each direction. Therefore the read from GPU 0 to 1 flows across separate HW links compared to the read from 1 to 0. There should be no interference for that NVLink traffic, in the simultaneous case.
The GPU memory itself doesn’t present a meaningful bottleneck for this case. The aggregate bandwidth across PCIE (~24GB/s) and across NVLink (~100GB/s) is small compared to the V100 memory bandwidth (~900GB/s).
I run a test, let GPU 0 and GPU 1 perform sm read simultaneously, this takes 1.1x times as long as only GPU 0 reads. Moreover I use -Xptxas -dlcm=cv flag to avoid effect of cache, same result.
Dose NVLink do separate, dedicated bandwidth logically or physically? Back to the test mentioned above, when only read from 0 to 1, GPU 0 → GPU 1 and GPU 1 → GPU 0 traffic both exist. I think 0->1 and 1->0 bandwith are both 50GB/s, but GPU 0 read GPU 1 will also consume 0->1 banwidth, which is a reason for the test result.
Each nvlink of that generation provides 25GB/s per direction. The “per direction” is isolated from each other: separate wires, separate transmitter and receiver. So you can sustain 25 GB/s from A to B and 25 GB/s from B to A, at the same time, over a single link. The reason you have 50GB/s per direction is that the NVLink bridge (of that generation) provides 2 links of connectivity.
Regarding the rest, you originally said:
You now appear to be describing something different.
If GPU 0 reads from GPU 1 memory, and GPU 1 reads from GPU 0 memory, then those transactions will flow over separate dedicated hardware lanes. But maybe your test is actually doing something else. I won’t be able to comment further since I don’t know what your test case is doing.