Description
We are using TensorRT via Triton to inference a BERT classification model.
Our model is simply a BERT base + classifier.
Previous we are using TRT 8.5.2, at tail of trtexec, the log shows
Average on 10 runs - GPU latency: 1.52078 ms - Host latency: 1.53953 ms (enqueue 1.5259 ms)
But after we upgrade to TRT 8.6.1, at tail of trtexec, the log shows
Average on 10 runs - GPU latency: 4.13606 ms - Host latency: 4.15786 ms (enqueue 0.541821 ms)
It shows alomost 3x latency regression, the source onnx model are same.
it seems the --fp16 didn’t work, I use nsys profile and see the 8.6.1 is always using fp32 cuda apis
you can see it’s using fp32 in 8.6.1

but it’s using fp16 in 8.5.2
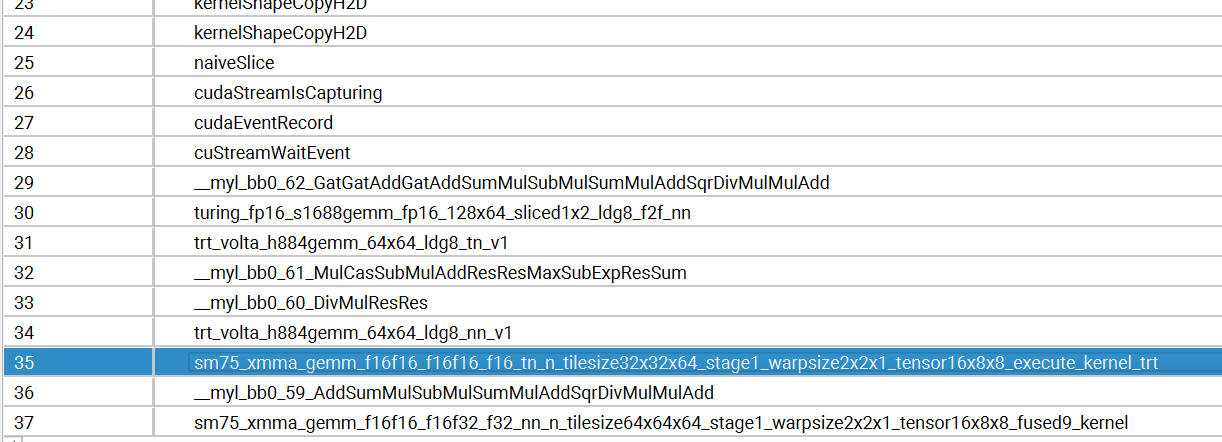
attached trtexec logs and nsight logs
Environment
TensorRT Version: 8.6.1
GPU Type: T4
Nvidia Driver Version: 525.105.17
CUDA Version: 12.0
CUDNN Version:
Operating System + Version: Ubuntu 20.04
Python Version (if applicable):
TensorFlow Version (if applicable):
PyTorch Version (if applicable):
Baremetal or Container (if container which image + tag):
Relevant Files
Please attach or include links to any models, data, files, or scripts necessary to reproduce your issue. (Github repo, Google Drive, Dropbox, etc.)
TextAnalyzerV2.t4.852.trt.log (1.4 MB)
TextAnalyzerV2.t4.861.trt.log (1.3 MB)
trt852.nsys-rep (735.7 KB)
trt861.nsys-rep (1.2 MB)
Steps To Reproduce
Please include:
- Exact steps/commands to build your repro
- Exact steps/commands to run your repro
- Full traceback of errors encountered