Good day everyone.
I am facing a problem with my laptop (Gigabyte Aero x15v7) for a while now and its affecting both Windows and Linux. Whenever i am playing a game (Some games worst then others) my nvidia driver would crash which leads to all kinds of problems. Windows would give a BSOD and Linux will give the following messages in the log:
Nov 27 10:30:15 aerix kernel: NVRM: Xid (PCI:0000:01:00): 31, pid=15973, name=Wobbly Life.exe, Ch 0000000e, intr 50000000. MMU Fault: ENGINE HOST0 HUBCLIENT_HOST faulted @ 0x0_35201000. Fault is of type FAULT_PTE ACCESS_TYPE_READ
Nov 27 10:30:15 aerix kernel: sched: RT throttling activated
Nov 27 10:30:14 aerix kernel: NVRM: Xid (PCI:0000:01:00): 13, pid=15973, name=Wobbly Life.exe, Graphics Exception: ChID 000b, Class 0000c197, Offset 00002390, Data 00600000
Nov 27 10:30:14 aerix kernel: NVRM: Xid (PCI:0000:01:00): 13, pid='<unknown>', name=<unknown>, Graphics Exception: ESR 0x405848=0x80000000
Nov 27 10:30:14 aerix kernel: NVRM: Xid (PCI:0000:01:00): 13, pid='<unknown>', name=<unknown>, Graphics Exception: ESR 0x405840=0xa2040248
Nov 27 10:30:14 aerix kernel: NVRM: Xid (PCI:0000:01:00): 13, pid='<unknown>', name=<unknown>, Graphics Exception: Shader Program Header 18 Error
Nov 27 10:30:14 aerix kernel: NVRM: Xid (PCI:0000:01:00): 13, pid='<unknown>', name=<unknown>, Graphics Exception: Shader Program Header 9 Error
Nov 27 10:30:14 aerix kernel: NVRM: Xid (PCI:0000:01:00): 13, pid='<unknown>', name=<unknown>, Graphics Exception: Shader Program Header 6 Error
Nov 27 10:30:14 aerix kernel: NVRM: Xid (PCI:0000:01:00): 13, pid='<unknown>', name=<unknown>, Graphics Exception: Shader Program Header 3 Error
Nov 27 10:30:14 aerix kernel: NVRM: GPU at PCI:0000:01:00: GPU-196d5b2e-9b09-3e5c-5065-ff717dbc8f2a
Its been happening for a while now, I have tried installing the vendor recommended drivers (On windows) and the latest drivers on Linux. And im a bit lost. I assume they are driver related problems considering the behavior of my laptop and the above error messages kinda confirms it (I have a AMD based desktop which does not crash when playing the same games so im assuming this is pure driver related).
On both Windows and Linux I have tried several driver versions.
If more information is required please let me know, ill be more then happy to supply any information needed to potentially solve this problem. nvidia-bug-report.log.gz (270.7 KB)
Many thanks for your reply, and sorry for the delayed answer (Was expecting an email when a reply was givven, but i did not receive anything).
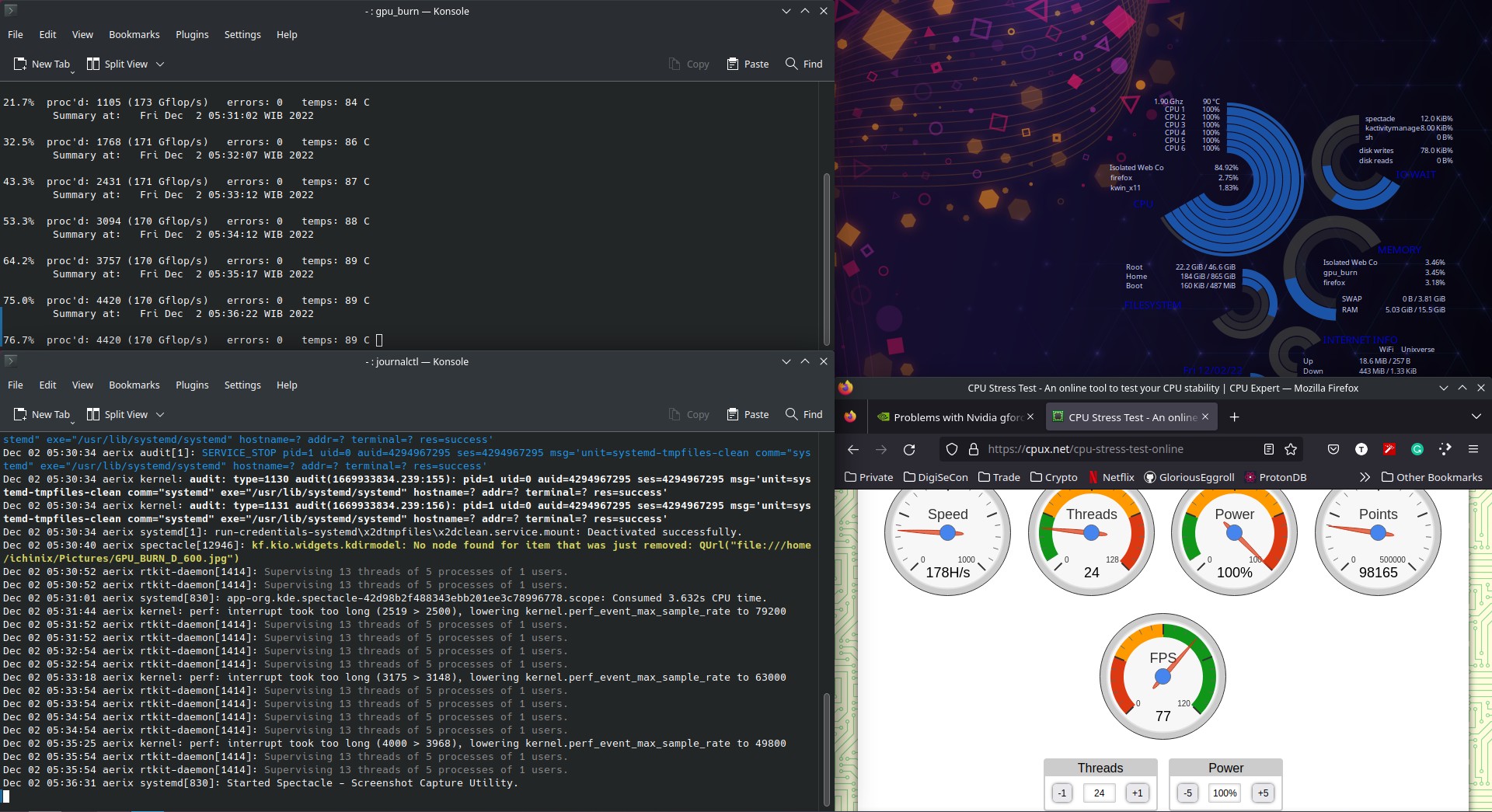
Anyhow, i just did the 10 min burn test without any problems, i have kept an eye on the sys logs but also nothing out wierd there either during the test.
Before i noticed your reply i was playing another game (Frozen Flame) where the problem happened again but with different error messages, i have included a new bug report in this post which i ran after the GPU_BURN test.
Dec 01 14:06:58 aerix kernel: nvidia-modeset: ERROR: GPU:0: Failed to query display engine channel state: 0x0000917e:3:0:0x0000000f
Dec 01 14:06:58 aerix kernel: nvidia-modeset: ERROR: GPU:0: Failed to query display engine channel state: 0x0000927c:3:0:0x0000000f
Dec 01 14:06:58 aerix kernel: nvidia-modeset: ERROR: GPU:0: Failed to query display engine channel state: 0x0000917e:2:0:0x0000000f
Dec 01 14:06:58 aerix kernel: nvidia-modeset: ERROR: GPU:0: Failed to query display engine channel state: 0x0000927c:2:0:0x0000000f
Dec 01 14:06:58 aerix kernel: nvidia-modeset: ERROR: GPU:0: Failed to query display engine channel state: 0x0000917e:1:0:0x0000000f
Dec 01 14:06:58 aerix kernel: nvidia-modeset: ERROR: GPU:0: Failed to query display engine channel state: 0x0000927c:1:0:0x0000000f
Dec 01 14:06:58 aerix kernel: nvidia-modeset: ERROR: GPU:0: Failed to query display engine channel state: 0x0000917e:0:0:0x0000000f
Dec 01 14:06:58 aerix kernel: nvidia-modeset: ERROR: GPU:0: Failed to query display engine channel state: 0x0000927c:0:0:0x0000000f
Dec 01 14:06:58 aerix kernel: nvidia-modeset: ERROR: GPU:0: Failed to query display engine channel state: 0x0000987d:0:0:0x0000000f
Dec 01 14:06:46 aerix kernel: NVRM: A GPU crash dump has been created. If possible, please run
NVRM: nvidia-bug-report.sh as root to collect this data before
NVRM: the NVIDIA kernel module is unloaded.
Some extra information which might help (Ive been searching the forums for potential solutions where information was given which i did not supply yet)
I am running arch with:
Intel Core i7-8750H
16 GB Ram memory (Still from the factory, asides from the NVME drive all hardware is stock)
Samsung evo 970 1tb
Intel Corporation CoffeeLake-H GT2 [UHD Graphics 630]
NVIDIA Corporation GP104M [GeForce GTX 1070 Mobile]
Software (Which might be relevant)
kernel 6.0.10-arch2-1
nvidia 525.60.11-1
nvidia-prime 1.0-4
nvidia-settings 525.60.11-2
nvidia-utils 525.60.11-1
opencl-nvidia 525.60.11-1
lib32-nvidia-utils 525.60.11-1
Current kernel parameters in grub:
GRUB_CMDLINE_LINUX_DEFAULT=“loglevel=3 quiet modprobe.blacklist=nouveau nvidia_drm.modeset=1 ibt=off intel_idle.max_cstate=1”
Ive blacklisted nouveau as without it nouveau kept loading preventing nvidia to load, nvidia_drm.modeset and ibt=off and intel)idel.max_cstate=1 are all parameters which i used in order to solve this issue.
If any more information is needed please let me know and ill happily supply it.
Rather odd, since gpu-burn ran up to 84°C without errors and the nvidia gpu stayed alive.
Please monitor cpu temperatures, maybe there’s something to find (i.e. if the cpu gets too hot, the gpu is shut down by the bios)
CPU generally hovers arround the same temp with spikes to 90C which for a I7 CPU is to be expected, currently its late at night here. So ill give it a try again tomorrow morning. (GMT+7 here)
I’ve run the test for an hour without any problems it seems. Any idea what else to do ?
Highest temp ive seen on the GPU was 90C, similar on the CPU roughly
Just to share some info. I installed the latest nvidia 525.60.11-3 drivers and linux 6.0.12.arch1-1 kernel (Among other packages not really relevant to this topic). And i have seen a reduced performance of the system.
I have read that Nvidia has some issues with Steam Proton somewhere to i started to test a bit. So far it seems that Linux Native games are working fine and that the issues are mainly with Steam Proton.
With the current package versions of Nvidia and the Linux Kernel any Windows game using Proton will kill the Nvidia driver before a game even starts (Barely get into the main menu of a game). But when playing a Linux Native game through steam it seems to be working fine. Although currently ive only tested it with 1 hour gaming sessions so far. Soon (Probably tonight or tomorrow) i will test this further.
I am not sure if the 2nd part is done currently (The VK_KHR_present_wait part).
Please help correct if needed.
With the current env variables proton games still seem to break the driver just as fast as before these changes. nvidia-bug-report.log.gz (260.6 KB)
Your Xserver is somehow misconfigured, the nvidia gpu is not bound to it. Also, files from the driver package seem to be missing. Please delete /etc/X11/xorg.conf and create
/etc/X11/xorg.conf.d/nvidia-drm.conf
I am sorry for the late reply, and happy holidays and great new year.
I mainly have been using wayland instead of xorg, it seemed to have better results (Toke longer for nvidia to crash). I dont think i ever had a xorg.conf before (Even when running xorg). Currently i have double checked if i had xorg.conf and added the nvidia-drm.conf. Please find attached the requested log file. nvidia-bug-report.log.gz (258.5 KB)