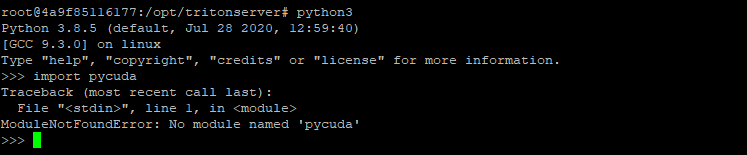
I’m running the FasterRCNN notebook with Transfer Learning Toolkit 3.0 and encountered this error when running tlt faster_rcnn dataset_convert:
pycuda._driver.LogicError: cuInit failed: system not yet initialized
I’m running the FasterRCNN notebook with Transfer Learning Toolkit 3.0 and encountered this error when running tlt faster_rcnn dataset_convert:
pycuda._driver.LogicError: cuInit failed: system not yet initialized
Can you run following command and share the result?
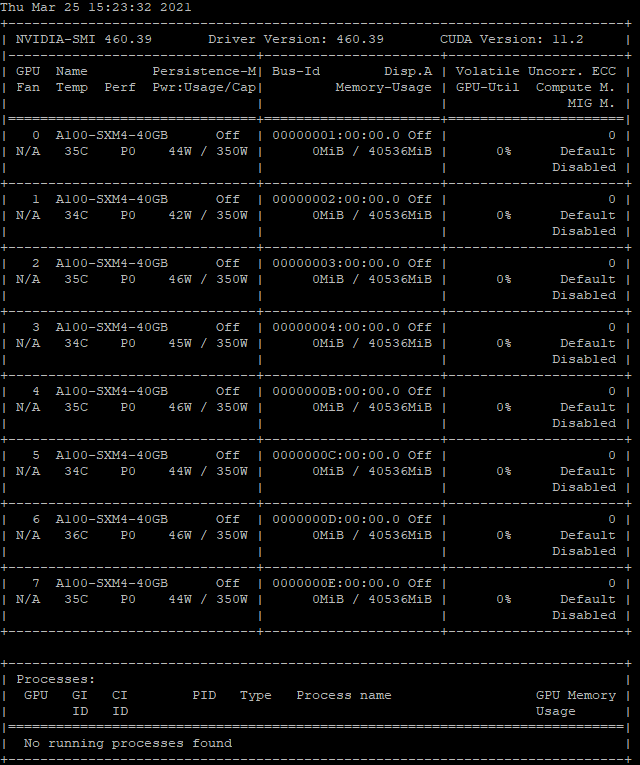
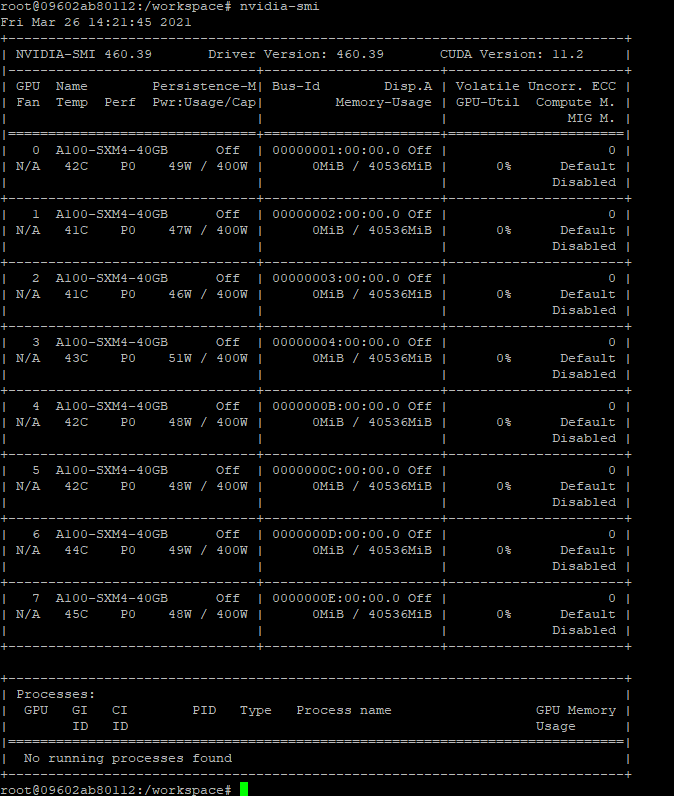
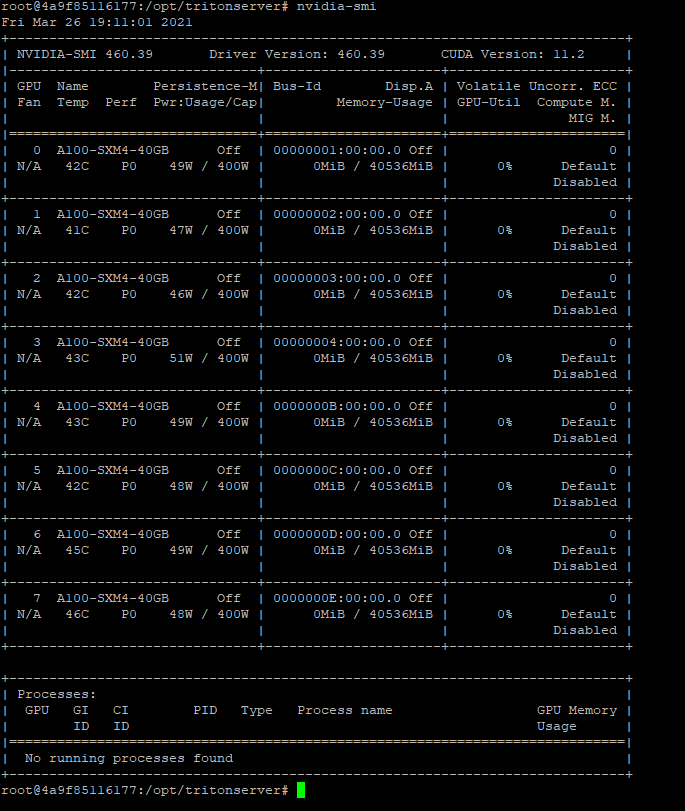
$ nvidia-smi
$ dpkg -l |grep cuda
Please refer to Code Yarns – PyCUDA error: cuInit failed
and Bug #1388217 “pycuda.autoinit fails after upgrade to 14.10” : Bugs : pycuda package : Ubuntu
Thank you for the suggestion. I ran sudo apt-get install nvidia-modprobe but the error still occurs.
Just confirming that the error is exactly the same after installing nvidia-modprobe:
!tlt faster_rcnn dataset_convert --gpu_index $GPU_INDEX -d $SPECS_DIR/frcnn_tfrecords_kitti_trainval.txt
-o $DATA_DOWNLOAD_DIR/tfrecords/kitti_trainval/kitti_trainval
2021-03-26 13:10:54,552 [WARNING] tlt.components.docker_handler.docker_handler:
Docker will run the commands as root. If you would like to retain your
local host permissions, please add the “user”:“UID:GID” in the
DockerOptions portion of the ~/.tlt_mounts.json file. You can obtain your
users UID and GID by using the “id -u” and “id -g” commands on the
terminal.
Using TensorFlow backend.
Traceback (most recent call last):
File “/usr/local/bin/faster_rcnn”, line 8, in
sys.exit(main())
File “/home/vpraveen/.cache/dazel/_dazel_vpraveen/216c8b41e526c3295d3b802489ac2034/execroot/ai_infra/bazel-out/k8-fastbuild/bin/magnet/packages/iva/build_wheel.runfiles/ai_infra/iva/faster_rcnn/entrypoint/faster_rcnn.py”, line 12, in main
File “/home/vpraveen/.cache/dazel/_dazel_vpraveen/216c8b41e526c3295d3b802489ac2034/execroot/ai_infra/bazel-out/k8-fastbuild/bin/magnet/packages/iva/build_wheel.runfiles/ai_infra/iva/common/entrypoint/entrypoint.py”, line 227, in launch_job
File “/home/vpraveen/.cache/dazel/_dazel_vpraveen/216c8b41e526c3295d3b802489ac2034/execroot/ai_infra/bazel-out/k8-fastbuild/bin/magnet/packages/iva/build_wheel.runfiles/ai_infra/iva/common/entrypoint/entrypoint.py”, line 47, in get_modules
File “/usr/lib/python3.6/importlib/init.py”, line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File “”, line 994, in _gcd_import
File “”, line 971, in _find_and_load
File “”, line 955, in _find_and_load_unlocked
File “”, line 665, in _load_unlocked
File “”, line 678, in exec_module
File “”, line 219, in _call_with_frames_removed
File “/home/vpraveen/.cache/dazel/_dazel_vpraveen/216c8b41e526c3295d3b802489ac2034/execroot/ai_infra/bazel-out/k8-fastbuild/bin/magnet/packages/iva/build_wheel.runfiles/ai_infra/iva/faster_rcnn/scripts/evaluate.py”, line 18, in
File “/home/vpraveen/.cache/dazel/_dazel_vpraveen/216c8b41e526c3295d3b802489ac2034/execroot/ai_infra/bazel-out/k8-fastbuild/bin/magnet/packages/iva/build_wheel.runfiles/ai_infra/iva/faster_rcnn/tensorrt_inference/tensorrt_model.py”, line 16, in
File “/usr/local/lib/python3.6/dist-packages/pycuda/autoinit.py”, line 5, in
cuda.init()
pycuda._driver.LogicError: cuInit failed: system not yet initialized
2021-03-26 13:11:17,519 [INFO] tlt.components.docker_handler.docker_handler: Stopping container.
To narrow down, can you login the docker
docker run --runtime=nvidia -it -v
<yourfolder>:/workspace/tlt-experiments nvcr.io/nvidia/tlt-streamanalytics:v3.0-dp-py3 /bin/bash
In the docker, please refer to python - How to remove cuInit failed: unknown error in CUDA (PyCuda) - Stack Overflow and run some commands.
For example,
# python
Python 3.6.9 (default, Oct 8 2020, 12:12:24)
[GCC 8.4.0] on linux
Type “help”, “copyright”, “credits” or “license” for more information.
>>>import pycuda
>>> import pycuda.driver as cuda
>>> cuda.init()
# nvcc -V
I’ve followed the advice and still encounter the same error.
Here are the results of running cuda.init(), nvcc -V, and nvidia-smi within the tlt-streamanalytics:v3.0-dp-py3 container:


Next I ran sudo nvidia-modprobe -u before launching the jupyter notebook, but encountered the same error. The same error occurred whether or not I used the --allow-root flag.
To narrow down, could you please download one triton server docker (Release Notes :: NVIDIA Deep Learning Triton Inference Server Documentation) and run previous commands again in it?
BTW, which gpu card are you using?
Could you please try GCP or AWS ?
Some end users can have successful experience with TLT 3.0.
Reference: Instructions/Guide/Tutorials to run TLT 3 on any cloud platform - #3 by Morganh
Many of our clients are integrated with Azure, so we prefer to use Azure VMs if possible. It’s worth noting that the same project runs successfully when configured the same way on our Azure instance with 8x V100s. The pycuda driver error only occurs when using A100 GPUs.
@gsweeney
Could you help describe the detailed steps for the Azure instance setup?
I need to reproduce on my side.
More, have you installed CUDA in the instance?
When I login tlt-streamanalytics:v3.0-dp-py3 container, I can find below info. But yours is not.
root@77718c28fab1:/workspace# dpkg -l |grep cuda
ii cuda-command-line-tools-11-1 11.1.1-1 amd64 CUDA command-line tools
ii cuda-compat-11-1 455.45.01-1 amd64 CUDA Compatibility Platform
ii cuda-compiler-11-1 11.1.1-1 amd64 CUDA compiler
ii cuda-cudart-11-1 11.1.74-1 amd64 CUDA Runtime native Libraries
ii cuda-cudart-dev-11-1 11.1.74-1 amd64 CUDA Runtime native dev links, headers
ii cuda-cuobjdump-11-1 11.1.74-1 amd64 CUDA cuobjdump
ii cuda-cupti-11-1 11.1.105-1 amd64 CUDA profiling tools runtime libs.
ii cuda-cupti-dev-11-1 11.1.105-1 amd64 CUDA profiling tools interface.
ii cuda-driver-dev-11-1 11.1.74-1 amd64 CUDA Driver native dev stub library
ii cuda-gdb-11-1 11.1.105-1 amd64 CUDA-GDB
ii cuda-libraries-11-1 11.1.1-1 amd64 CUDA Libraries 11.1 meta-package
ii cuda-libraries-dev-11-1 11.1.1-1 amd64 CUDA Libraries 11.1 development meta-package
ii cuda-memcheck-11-1 11.1.105-1 amd64 CUDA-MEMCHECK
ii cuda-minimal-build-11-1 11.1.1-1 amd64 Minimal CUDA 11.1 toolkit build packages.
ii cuda-nvcc-11-1 11.1.105-1 amd64 CUDA nvcc
ii cuda-nvdisasm-11-1 11.1.74-1 amd64 CUDA disassembler
ii cuda-nvml-dev-11-1 11.1.74-1 amd64 NVML native dev links, headers
ii cuda-nvprof-11-1 11.1.105-1 amd64 CUDA Profiler tools
ii cuda-nvprune-11-1 11.1.74-1 amd64 CUDA nvprune
ii cuda-nvrtc-11-1 11.1.105-1 amd64 NVRTC native runtime libraries
ii cuda-nvrtc-dev-11-1 11.1.105-1 amd64 NVRTC native dev links, headers
ii cuda-nvtx-11-1 11.1.74-1 amd64 NVIDIA Tools Extension
ii cuda-sanitizer-11-1 11.1.105-1 amd64 CUDA Sanitizer
hi libcudnn8 8.0.4.30-1+cuda11.1 amd64 cuDNN runtime libraries
ii libcudnn8-dev 8.0.4.30-1+cuda11.1 amd64 cuDNN development libraries and headers
hi libnccl-dev 2.7.8-1+cuda11.1 amd64 NVIDIA Collectives Communication Library (NCCL) Development Files
hi libnccl2 2.7.8-1+cuda11.1 amd64 NVIDIA Collectives Communication Library (NCCL) Runtime
ii libnvinfer-dev 7.2.1-1+cuda11.1 amd64 TensorRT development libraries and headers
ii libnvinfer-plugin-dev 7.2.1-1+cuda11.1 amd64 TensorRT plugin libraries
ii libnvinfer-plugin7 7.2.1-1+cuda11.1 amd64 TensorRT plugin libraries
ii libnvinfer7 7.2.1-1+cuda11.1 amd64 TensorRT runtime libraries
ii libnvonnxparsers-dev 7.2.1-1+cuda11.1 amd64 TensorRT ONNX libraries
ii libnvonnxparsers7 7.2.1-1+cuda11.1 amd64 TensorRT ONNX libraries
ii libnvparsers-dev 7.2.1-1+cuda11.1 amd64 TensorRT parsers libraries
ii libnvparsers7 7.2.1-1+cuda11.1 amd64 TensorRT parsers libraries
I set up an AWS instance but cannot reproduce the issue. The cuda.init() works fine.
Step:
$sudo su - root
$apt update
$apt upgrade -y
$apt install -y python-pip python3-pip unzip
$pip3 install virtualenvwrapper
$export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
$source /usr/local/bin/virtualenvwrapper.sh
$mkvirtualenv launcher -p /usr/bin/python3
$pip3 install jupyterlab
$pip3 install nvidia-pyindex
$pip3 install nvidia-tlt
$tlt info
$tlt ssd help
$tlt faster_rcnn run /bin/bash
Then, in the docker, run python →>>> import pycuda.driver as cuda >>> cuda.init()
Part of log:
(launcher) root@ip-172-31-33-152:~/tlt_cv_samples_v1.0.2# tlt info
Configuration of the TLT Instance
dockers: ['nvcr.io/nvidia/tlt-streamanalytics', 'nvcr.io/nvidia/tlt-pytorch']
format_version: 1.0
tlt_version: 3.0
published_date: 02/02/2021
(launcher) root@ip-172-31-33-152:~/tlt_cv_samples_v1.0.2# tlt help
usage: tlt [-h]
{list,stop,info,augment,classification,detectnet_v2,dssd,emotionnet,faster_rcnn,fpenet,gazenet,gesturenet,heartratenet,intent_slot_classification,lprnet,mask_rcnn,punctuation_and_capitalization,question_answering,retinanet,speech_to_text,ssd,text_classification,tlt-converter,token_classification,unet,yolo_v3,yolo_v4}
...
tlt: error: invalid choice: 'help' (choose from 'list', 'stop', 'info', 'augment', 'classification', 'detectnet_v2', 'dssd', 'emotionnet', 'faster_rcnn', 'fpenet', 'gazenet', 'gesturenet', 'heartratenet', 'intent_slot_classification', 'lprnet', 'mask_rcnn', 'punctuation_and_capitalization', 'question_answering', 'retinanet', 'speech_to_text', 'ssd', 'text_classification', 'tlt-converter', 'token_classification', 'unet', 'yolo_v3', 'yolo_v4')
(launcher) root@ip-172-31-33-152:~/tlt_cv_samples_v1.0.2# tlt ssd help
2021-04-16 08:30:43,629 [INFO] tlt.components.docker_handler.docker_handler: The required docker doesn't exist locally/the manifest has changed. Pulling a new docker.
2021-04-16 08:30:43,629 [INFO] tlt.components.docker_handler.docker_handler: Pulling the required container. This may take several minutes if you're doing this for the first time. Please wait here.
...
2021-04-16 08:32:37,333 [INFO] tlt.components.docker_handler.docker_handler: Container pull complete.
2021-04-16 08:32:37,333 [INFO] root: No mount points were found in the /root/.tlt_mounts.json file.
2021-04-16 08:32:37,333 [WARNING] tlt.components.docker_handler.docker_handler:
Docker will run the commands as root. If you would like to retain your
local host permissions, please add the "user":"UID:GID" in the
DockerOptions portion of the ~/.tlt_mounts.json file. You can obtain your
users UID and GID by using the "id -u" and "id -g" commands on the
terminal.
Using TensorFlow backend.
usage: ssd [-h] [--gpus GPUS] [--gpu_index GPU_INDEX [GPU_INDEX ...]]
[--use_amp] [--log_file LOG_FILE]
{evaluate,export,inference,prune,train} ...
ssd: error: invalid choice: 'help' (choose from 'evaluate', 'export', 'inference', 'prune', 'train')
2021-04-16 08:33:04,063 [INFO] tlt.components.docker_handler.docker_handler: Stopping container.
(launcher) root@ip-172-31-33-152:~/tlt_cv_samples_v1.0.2# tlt faster_rcnn run /bin/bash
2021-04-16 08:33:47,812 [INFO] root: No mount points were found in the /root/.tlt_mounts.json file.
2021-04-16 08:33:47,812 [WARNING] tlt.components.docker_handler.docker_handler:
Docker will run the commands as root. If you would like to retain your
local host permissions, please add the "user":"UID:GID" in the
DockerOptions portion of the ~/.tlt_mounts.json file. You can obtain your
users UID and GID by using the "id -u" and "id -g" commands on the
terminal.
root@8645c75918be:/workspace# dpkg -l |grep cuda
ii cuda-command-line-tools-11-1 11.1.1-1 amd64 CUDA command-line tools
ii cuda-compat-11-1 455.45.01-1 amd64 CUDA Compatibility Platform
ii cuda-compiler-11-1 11.1.1-1 amd64 CUDA compiler
ii cuda-cudart-11-1 11.1.74-1 amd64 CUDA Runtime native Libraries
ii cuda-cudart-dev-11-1 11.1.74-1 amd64 CUDA Runtime native dev links, headers
ii cuda-cuobjdump-11-1 11.1.74-1 amd64 CUDA cuobjdump
ii cuda-cupti-11-1 11.1.105-1 amd64 CUDA profiling tools runtime libs.
ii cuda-cupti-dev-11-1 11.1.105-1 amd64 CUDA profiling tools interface.
ii cuda-driver-dev-11-1 11.1.74-1 amd64 CUDA Driver native dev stub library
ii cuda-gdb-11-1 11.1.105-1 amd64 CUDA-GDB
ii cuda-libraries-11-1 11.1.1-1 amd64 CUDA Libraries 11.1 meta-package
ii cuda-libraries-dev-11-1 11.1.1-1 amd64 CUDA Libraries 11.1 development meta-package
ii cuda-memcheck-11-1 11.1.105-1 amd64 CUDA-MEMCHECK
ii cuda-minimal-build-11-1 11.1.1-1 amd64 Minimal CUDA 11.1 toolkit build packages.
ii cuda-nvcc-11-1 11.1.105-1 amd64 CUDA nvcc
ii cuda-nvdisasm-11-1 11.1.74-1 amd64 CUDA disassembler
ii cuda-nvml-dev-11-1 11.1.74-1 amd64 NVML native dev links, headers
ii cuda-nvprof-11-1 11.1.105-1 amd64 CUDA Profiler tools
ii cuda-nvprune-11-1 11.1.74-1 amd64 CUDA nvprune
ii cuda-nvrtc-11-1 11.1.105-1 amd64 NVRTC native runtime libraries
ii cuda-nvrtc-dev-11-1 11.1.105-1 amd64 NVRTC native dev links, headers
ii cuda-nvtx-11-1 11.1.74-1 amd64 NVIDIA Tools Extension
ii cuda-sanitizer-11-1 11.1.105-1 amd64 CUDA Sanitizer
hi libcudnn8 8.0.4.30-1+cuda11.1 amd64 cuDNN runtime libraries
ii libcudnn8-dev 8.0.4.30-1+cuda11.1 amd64 cuDNN development libraries and headers
hi libnccl-dev 2.7.8-1+cuda11.1 amd64 NVIDIA Collectives Communication Library (NCCL) Development Files
hi libnccl2 2.7.8-1+cuda11.1 amd64 NVIDIA Collectives Communication Library (NCCL) Runtime
ii libnvinfer-dev 7.2.1-1+cuda11.1 amd64 TensorRT development libraries and headers
ii libnvinfer-plugin-dev 7.2.1-1+cuda11.1 amd64 TensorRT plugin libraries
ii libnvinfer-plugin7 7.2.1-1+cuda11.1 amd64 TensorRT plugin libraries
ii libnvinfer7 7.2.1-1+cuda11.1 amd64 TensorRT runtime libraries
ii libnvonnxparsers-dev 7.2.1-1+cuda11.1 amd64 TensorRT ONNX libraries
ii libnvonnxparsers7 7.2.1-1+cuda11.1 amd64 TensorRT ONNX libraries
ii libnvparsers-dev 7.2.1-1+cuda11.1 amd64 TensorRT parsers libraries
ii libnvparsers7 7.2.1-1+cuda11.1 amd64 TensorRT parsers libraries
root@8645c75918be:/workspace# nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2020 NVIDIA Corporation
Built on Mon_Oct_12_20:09:46_PDT_2020
Cuda compilation tools, release 11.1, V11.1.105
Build cuda_11.1.TC455_06.29190527_0
root@8645c75918be:/workspace# python
Python 3.6.9 (default, Oct 8 2020, 12:12:24)
[GCC 8.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import pycuda
>>> import pycuda.driver as cuda
>>> cuda.init()
>>>
root@8645c75918be:/workspace# ls /usr/local/lib/python3.6/dist-packages/pycuda/autoinit.py
/usr/local/lib/python3.6/dist-packages/pycuda/autoinit.py
root@8645c75918be:/workspace# cat /usr/local/lib/python3.6/dist-packages/pycuda/autoinit.py
from __future__ import absolute_import
import pycuda.driver as cuda
# Initialize CUDA
cuda.init()
from pycuda.tools import make_default_context
global context
context = make_default_context()
device = context.get_device()
def _finish_up():
global context
context.pop()
context = None
from pycuda.tools import clear_context_caches
clear_context_caches()
import atexit
atexit.register(_finish_up)
root@8645c75918be:/workspace# python
Python 3.6.9 (default, Oct 8 2020, 12:12:24)
[GCC 8.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import pycuda.driver as cuda
>>> cuda.init()
>>>
This error is due to the Fabric Manager not being properly set up.
Can you provide more detail about the problem and solution in this instance?
Did you read the document I linked? It covers those things much better than I can.
Fabric Manager is an additional software component that is basically required any time you have HGX A100 - 8 GPU product configurations (basically systems that use A100 and NVSwitch). The system described here with 8 A100 SXM4 GPUs is one of those.
Fabric Manager must be installed separately from the GPU driver. The document explains how to do it.
If you do not install FM properly, but attempt to use CUDA anyway, a specific error code (“system not yet initialized”) will be reported.