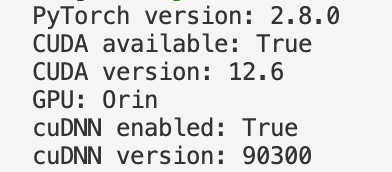
i am trying to build EdgeTAM from source (a model built on top of Facebook’s Segment Anything), and I’m getting a bunch of user warnings. I have CUDA enabled, here is my system information:
PyTorch version: 2.8.0
torchvision version: 0.23.0
CUDA available: True
CUDA version: 12.6
GPU: Orin
cuDNN version: 90300
BFloat16 supported: True
torch.backends.cuda.flash_sdp_enabled: True
torch.backends.cuda.mem_efficient_sdp_enabled: True
torch.backends.cuda.cudnn_sdp_enabled: True
Why are my kernels not loading properly? Does it have to do with my CUDA build? Also, when I convert the model to bfloat16, the userwarnings go away, but the speed of the model is still a magnitude of difference away from the expected speed (that others have replicated).
UserWarning: Memory efficient kernel not used because: (Triggered internally at /opt/pytorch/aten/src/ATen/native/transformers/cuda/sdp_utils.cpp:863.)
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p)
UserWarning: Memory Efficient attention has been runtime disabled. (Triggered internally at /opt/pytorch/aten/src/ATen/native/transformers/sdp_utils_cpp.h:552.)
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p)
UserWarning: Flash attention kernel not used because: (Triggered internally at /opt/pytorch/aten/src/ATen/native/transformers/cuda/sdp_utils.cpp:865.)
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p)
UserWarning: Expected query, key and value to all be of dtype: {Half, BFloat16}. Got Query dtype: float, Key dtype: float, and Value dtype: float instead. (Triggered internally at /opt/pytorch/aten/src/ATen/native/transformers/sdp_utils_cpp.h:91.)
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p)
UserWarning: CuDNN attention kernel not used because: (Triggered internally at /opt/pytorch/aten/src/ATen/native/transformers/cuda/sdp_utils.cpp:867.)
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p)
UserWarning: Flash Attention kernel failed due to: No available kernel. Aborting execution.
Falling back to all available kernels for scaled_dot_product_attention (which may have a slower speed).
for anyone who wants to see the code that I am running, here:
import torch
import os
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from sam2.build_sam import build_sam2
from sam2.sam2_image_predictor import SAM2ImagePredictor
from sam2.automatic_mask_generator import SAM2AutomaticMaskGenerator
import time
device = torch.device("cuda")
image = Image.open('./left.png')
image = np.array(image.convert("RGB"))
checkpoint = "./checkpoints/edgetam.pt"
model_cfg = "edgetam.yaml"
model = build_sam2(model_cfg, checkpoint, device=device)
mask_generator = SAM2AutomaticMaskGenerator(model)
for i in range(10):
now = time.time()
masks = mask_generator.generate(image)
print(time.time() - now, "seconds")
Thank you so much!!