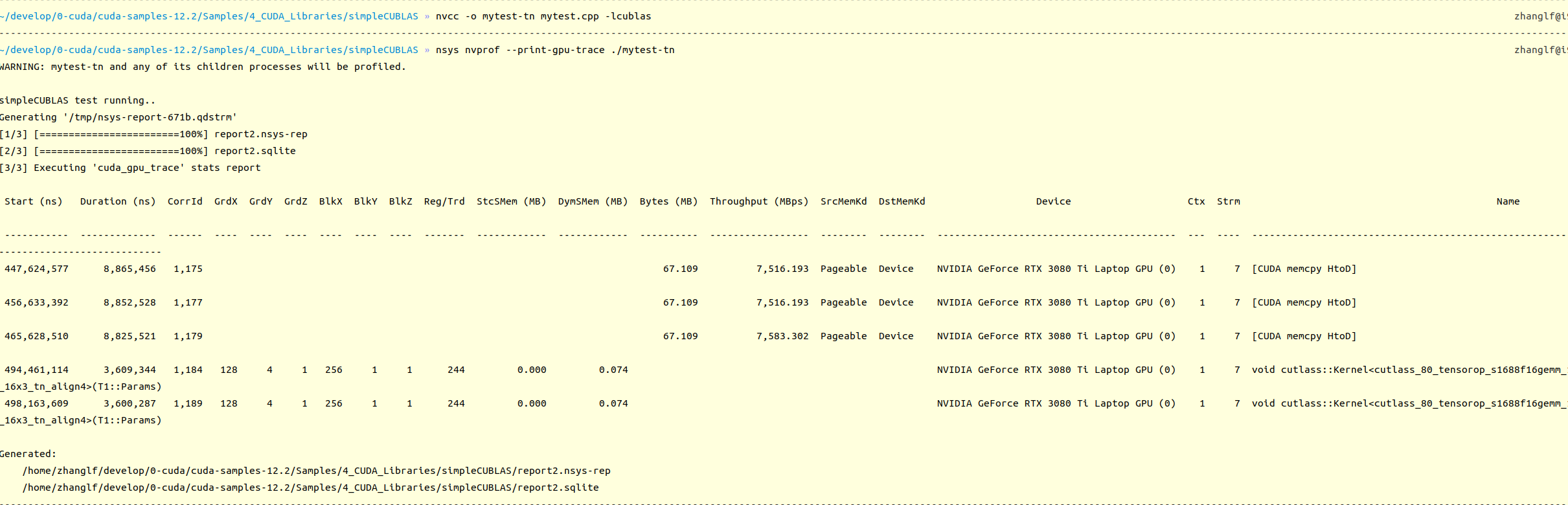
I understand that the memory layout of input matrices affects the performance of cuBLAS GEMM. According to the information I’ve found ( cuBLAS related question - CUDA / CUDA Programming and Performance - NVIDIA Developer Forums), the NT case (that is, for A*B, A is row-major and B is column-major) should be the fastest. However, I observed different phenomena on my RTX 3080 Ti 3080 laptop. I ran the simpleCublas example from the CUDA Toolkit samples and set cublasSetMathMode(handle, CUBLAS_TENSOR_OP_MATH);. Then I added some precise timing code. I tested several sizes, such as m=n=k=1024, 1048, 4096. I found that the TN case was always slightly better than the NT case. So, has NVIDIA now done some special optimization for the TN case ? Or could someone verify this phenomenon? thanks.
the test results :
m=n=k=4096
TN: 3951 us
NT: 4247 us
m=n=k=2048
TN: 704 us
NT: 780 us
m=n=k=1024:
TN: 205 us
NT: 220 us
my codes :
/* Includes, system */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
/* Includes, cuda */
#include <cublas_v2.h>
#include <cuda_runtime.h>
#include <helper_cuda.h>
#include "C:\F_develop\1-cuda\1-cuda_tookit_samples\cuda-samples-11.6\cuda-samples-11.6\Samples\4_CUDA_Libraries\batchCUBLAS\batchCUBLAS.h"
/* Matrix size */
#define N (4096)
/* Main */
int main(int argc, char** argv) {
cublasStatus_t status;
float* h_A;
float* h_B;
float* h_C;
//float *h_C_ref;
float* d_A = 0;
float* d_B = 0;
float* d_C = 0;
float alpha = 1.0f;
float beta = 0.0f;
int n2 = N * N;
int i;
float error_norm;
float ref_norm;
float diff;
cublasHandle_t handle;
int dev = findCudaDevice(argc, (const char**)argv);
if (dev == -1) {
return EXIT_FAILURE;
}
/* Initialize CUBLAS */
printf("simpleCUBLAS test running..\n");
status = cublasCreate(&handle);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "!!!! CUBLAS initialization error\n");
return EXIT_FAILURE;
}
status = cublasSetMathMode(handle, CUBLAS_TENSOR_OP_MATH); // enable tensor core
/* Allocate host memory for the matrices */
h_A = reinterpret_cast<float*>(malloc(n2 * sizeof(h_A[0])));
if (h_A == 0) {
fprintf(stderr, "!!!! host memory allocation error (A)\n");
return EXIT_FAILURE;
}
h_B = reinterpret_cast<float*>(malloc(n2 * sizeof(h_B[0])));
if (h_B == 0) {
fprintf(stderr, "!!!! host memory allocation error (B)\n");
return EXIT_FAILURE;
}
h_C = reinterpret_cast<float*>(malloc(n2 * sizeof(h_C[0])));
if (h_C == 0) {
fprintf(stderr, "!!!! host memory allocation error (C)\n");
return EXIT_FAILURE;
}
/* Fill the matrices with test data */
for (i = 0; i < n2; i++) {
h_A[i] = 1;
h_B[i] = 1;
h_C[i] = 1;
}
/* Allocate device memory for the matrices */
if (cudaMalloc(reinterpret_cast<void**>(&d_A), n2 * sizeof(d_A[0])) !=
cudaSuccess) {
fprintf(stderr, "!!!! device memory allocation error (allocate A)\n");
return EXIT_FAILURE;
}
if (cudaMalloc(reinterpret_cast<void**>(&d_B), n2 * sizeof(d_B[0])) !=
cudaSuccess) {
fprintf(stderr, "!!!! device memory allocation error (allocate B)\n");
return EXIT_FAILURE;
}
if (cudaMalloc(reinterpret_cast<void**>(&d_C), n2 * sizeof(d_C[0])) !=
cudaSuccess) {
fprintf(stderr, "!!!! device memory allocation error (allocate C)\n");
return EXIT_FAILURE;
}
/* Initialize the device matrices with the host matrices */
status = cublasSetVector(n2, sizeof(h_A[0]), h_A, 1, d_A, 1);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "!!!! device access error (write A)\n");
return EXIT_FAILURE;
}
status = cublasSetVector(n2, sizeof(h_B[0]), h_B, 1, d_B, 1);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "!!!! device access error (write B)\n");
return EXIT_FAILURE;
}
status = cublasSetVector(n2, sizeof(h_C[0]), h_C, 1, d_C, 1);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "!!!! device access error (write C)\n");
return EXIT_FAILURE;
}
double start, stop, total = 0.0;
int repeat = 10;
for (int i = 0; i < repeat; i++) {
start = second();
/* Performs operation using cublas */
//status = cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_T, N, N, N, &alpha, d_A,
// N, d_B, N, &beta, d_C, N);
status = cublasSgemm(handle, CUBLAS_OP_T, CUBLAS_OP_N, N, N, N, &alpha, d_A,
N, d_B, N, &beta, d_C, N);
cudaError_t cudaStatus = cudaDeviceSynchronize();
stop = second();
total += (stop - start);
fprintf(stdout, "^^^^ elapsed = %10.8f sec \n", (stop - start));
}
fprintf(stdout, "^^^^ average elapsed = %10.8f sec \n", total / repeat);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "!!!! kernel execution error.\n");
return EXIT_FAILURE;
}
/* Memory clean up */
free(h_A);
free(h_B);
if (cudaFree(d_A) != cudaSuccess) {
fprintf(stderr, "!!!! memory free error (A)\n");
return EXIT_FAILURE;
}
if (cudaFree(d_B) != cudaSuccess) {
fprintf(stderr, "!!!! memory free error (B)\n");
return EXIT_FAILURE;
}
if (cudaFree(d_C) != cudaSuccess) {
fprintf(stderr, "!!!! memory free error (C)\n");
return EXIT_FAILURE;
}
/* Shutdown */
status = cublasDestroy(handle);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "!!!! shutdown error (A)\n");
return EXIT_FAILURE;
}
}