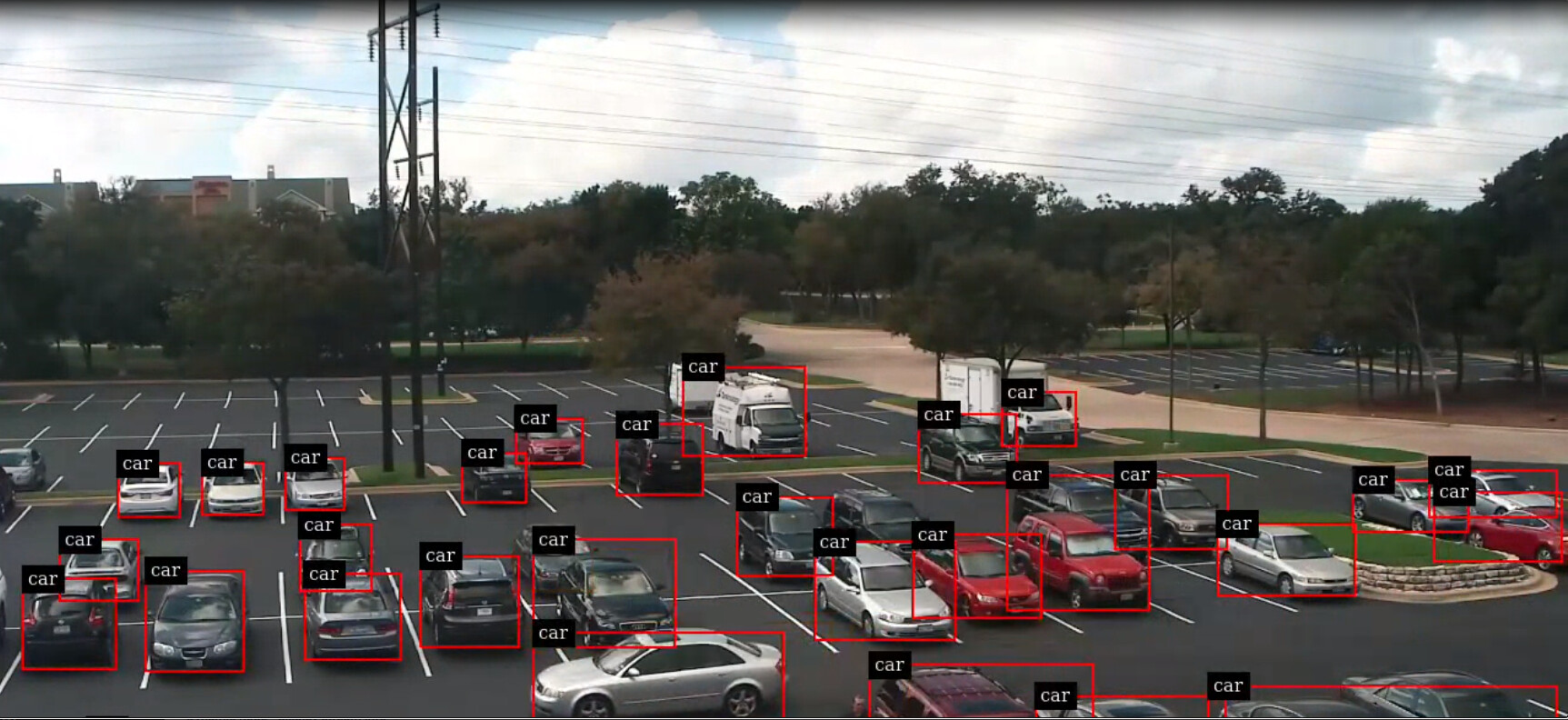
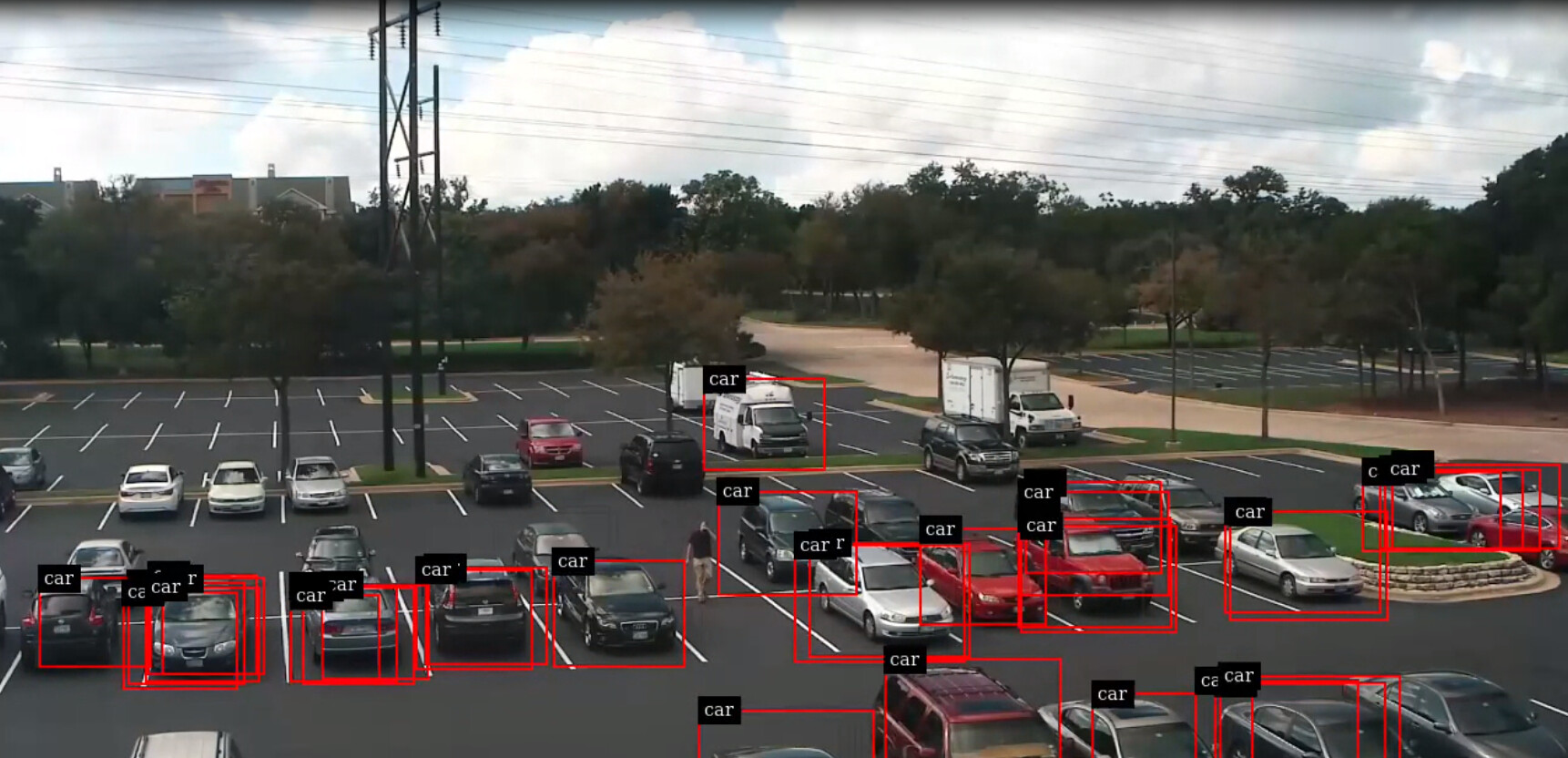
NVIDIA TrafficCamNet v1.0 performs fine in most of the cases, except when using cameras mounted with a “bird’s-eye” perspective as some vehicles are not detected.
I would like to improve the existing detector, by reusing the original weights and extend the model on TLT with additional “car” labelled images.
Initial training was performed during 120 epochs with no frozen layers, but the resulting model ended overfitted to the type of images & perspective present on the new dataset.
Then in another TLT training, I tried to freeze the model layers in a hope that will preserve the original weights, but the training converges too fast and also gets overfitted just after 3 or 4 epochs.
I would like the resulting model from TLT training be capable to keep similar accuracy as the original in the “car” detection, and additionally the same “car” class be able to deal with the “bird’s-eye” perspective images.
Is there anything I can tweak on the model and training config level?
Or should the dataset that I’m using in TLT be augmented to contain images identical to the ones used in NVIDIA private dataset, in order the model does not “forget” such cases during TLT training?
i ’ ve retrained the trafficCamnet as well, i assume we 've got the similar results, overfitting, but i only prepared very small dataSets with four labelled objects, approx 450 images, and i also froze blocks [0,1,2,3],expecting to reuse the original weights of the net, as far as i am concerned , the most important thing is to keep the much lower rate of learning, you could try like following config:
i am also confused about your question, should we prepare some similar scenario datasets with Nvidia pretrained trafficCamnet model? i 've tried to retrain model several times, however, it seemed the model was trained from scratch even i successfully loaded pretrained model and froze some blocks as well. Because the evaluation results illustrated the average precision 0 or Nan at the beginning training epoch, @Morganh
TrafficCamNet v1.0 model was trained on a proprietary dataset with more than 3 million objects for car class. Most of the training dataset was collected and labeled in-house from several traffic cameras in a city in the US. The dataset also contains 40,000 images from a variety of dashcam to help with generalization and discrimination across classes. This content was chosen to improve accuracy of the object detection for images from a traffic cam at a traffic intersection.
Thanks for your input, I will try to reduce the learning rate. I was using the default values from NVIDIA examples but with frozen blocks the model converges too fast.
By “four labelled objects” do you mean different object classes or you also tried to specialize a bit the existing ones? (car, person, road signs & two-wheeler)
As far as I know the (freeze block number) => (group of layers) relation is not shared by NVIDIA, according to some info present in the foruns (0 => 3) follows the order (input => output).
I was trying to preserve the weights & accuracy of the “car” class from the original model, so in the last training I frozen all the blocks.
My question was if in this case where we want to improve an existing class, we might need to use also on TLT training a subset of the original training set NVIDIA used, or at least something similar that recreates the original data distribution.
Otherwise the mAP and losses will only take in account our new training dataset for adjustment of the new output layer(s) weights?
But I’m new to TLT and transfer learning in general, that’s why I’m trying to gather some info in this topic. Thanks :)
But in this case I would like to improve the “car” class of the original model, not create a new model or class from scratch.
Do you mean that the only way to additionally extend the inference support to this “birds eye” view but keep similar accuracy of the original model in the other perspectives, would be augment the current distribution of the dataset I’m using on TLT training?
To reach this goal, ideally besides the Parking Lot Database it would be required add to the TLT a subset of the NVIDIA private dataset (Dashcam (5ft height) & Traffic-signal content environments) or something similar to it right?
Now the TLT training results. As you can see even with the frozen layers it quickly loses the ability to detect most of the cars.
(Please don’t mind about the multiple bounding boxes for the same object, I’ve reduced the thresholds and clustering settings to be able to visualize everything)
Epoch 1/20
=========================
Validation cost: 0.001405
Mean average_precision (in %): 35.9895
class name average precision (in %)
------------ --------------------------
car 35.9895
Epoch 11/20
=========================
Validation cost: 0.000325
Mean average_precision (in %): 96.8245
class name average precision (in %)
------------ --------------------------
car 96.8245
No, it is fine to train with the Parking Lot Database only. With the ngc pretrained model, the converge will be quicker than without pretrained model.
Suggest you do not freeze the blocks. And then trigger training.
More, your current training result shows that the mAP can reach 96.8% during evaluation but its inference result is not good. Can you double check? And what is your inference spec?
Training 120 epochs without frozen blocks was my initial attempt, but the resulting model ended overfitted to the “parking lot” perspective. When using it in other scenarios like dash-cam view TLT model gets a lot of false positives and lack of detection.
Sorry, I forgot to mention the images that I shared on the previous post does not belong to the training/testing dataset used on TLT.
They are printscreens for comparison purpose of the inference results on DeepStream when running the original model and the TLT model, but using a completely different input video. Hence there’s no direct relation with the mAP values from the training evaluation, they are there just for reference.
(well, I guess due to overfitting the relation might be: slightly_different_input_video_mAP = 1-training_mAP :) )
As you can see for 120 epochs without frozen blocks, results are not that different:
Validation cost: 0.001908
Mean average_precision (in %): 97.9555
class name average precision (in %)
------------ --------------------------
car 97.9555
There is no update from you for a period, assuming this is not an issue any more.
Hence we are closing this topic. If need further support, please open a new one.
Thanks